
とある学生エンジニアの研究と日常② (研究編)

こんにちは。アーニーMLG学生エンジニアの山下です!
今回は、先月の自己紹介記事の続編として、ふだん取り組んでいる研究の「画像生成」について簡単にご紹介しようと思います。
研究紹介:画像生成ってどうやってるの?
みなさんは、「画像生成」という言葉を聞いたことはありますか?
テレビやSNSなどでフェイク画像、フェイク動画といったものを1度は目にしたことがあると思います。

これらは、AI、すなわち深層学習モデルによる生成技術によって作られています。そして僕は、学校でこの深層学習モデルによる画像生成に関する研究をしています。今回はとてもざっくりとした紹介になるので、興味のある方はぜひ関連するニュース記事や論文など読んでみてください〜

画像引用:Began: State of the art generation of faces with generative adversarial networks
画像生成モデルは、ある特定の対象のデータ(人の顔とか、動物とか、乗り物とかの画像)から学習を行い、その対象の画像を作ります。作られた画像はその特定の対象、つまり人の顔や動物などであることが一目見て分かる画像ですが、元のデータに含まれるどの画像とも異なる、完全に新しい画像となっています。
では、どうやってこのようなことを実現するのでしょう?
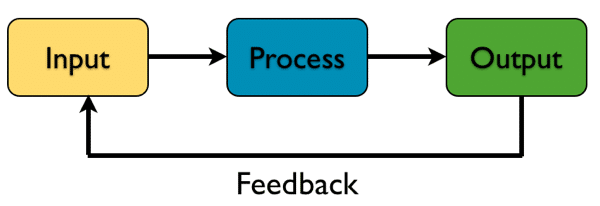
画像生成モデルは、データを「変換」することで新しい画像を作っています。(画像生成に限らず、多くの深層学習モデルが「変換」がカギになっています。音声認識もそうですね。)
「変換」とはつまり、「入力」されたデータをあるルールに従って変化させて、そのデータ(画像)を「出力」することをいいます。どんな画像は出来上がるかは、この変換の「ルール」次第というわけです。画像生成モデルは、大量の対象データの規則性や特徴を学習することで目的の画像を作ることができる変換ルールを探します。これが、画像生成のざっくりとしたイメージになります。
それでは、主要な画像生成モデルを2つほどご紹介します。
・GAN(Generative Adversarial Network, 敵対的生成ネットワーク)

画像引用:pix2pix - Thoth Children
今でも根強い人気があり多くの論文が出ている強力な画像生成モデルです。
画像生成を行うGenerator(生成モデル)に加えて、Discriminator(識別モデル)という生成された偽の画像を見抜くライバル(?)のようなモデルを用意して、互いに切磋琢磨して学習していくという画期的なやり方で、とても品質の高い画像を作ります。
<主要な研究例>
(↓興味のある方向け、タイトルをクリックで論文ページにリンクします)
・pix2pix:
線画→実写など様々な種類の画像変換を実現した論文です
・StyleGAN:
髪型、瞳の色など顔の「スタイル」を他の顔に転写します
・ProgressiveGAN:
学習中にモデルを段階的に大きくしていって高解像度の画像を作ります
・SinGAN:
単一画像で学習して、超解像・アニメ化など幅広いタスクを行います
・Auto-Encoder(オートエンコーダ)
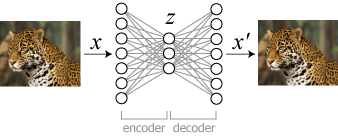
画像引用:Keras: 画像生成 (変分オートエンコーダー) - MOXBOX
画像データを小さいパラメータのデータに圧縮して、さらに元の画像を復元することができるモデルです。圧縮して容量を小さくできるのはいかにも便利そうですが、「データ補間」という面白い使い方もできます。
AさんとBさん、2人の顔画像をオートエンコーダで圧縮して、パラメータXとYがそれぞれ得られたとします。XとYはそれぞれAさんとBさんの顔画像に復元することができます。それではXとYの中間に位置するパラメータZをオートエンコーダで復元するとしたらどうなるでしょう?
よく学習されたモデルなら、AさんとBさんの中間の特徴を持った新しい顔を作ることができます。

画像引用:Agent Embeddings - 0scar Chang
色々な可能性を感じるモデルですが、音声認識にも使われていることを入社後に知って驚きました。僕の好きな深層学習モデルの一つです。
<主要な研究例>
(↓興味のある方向け、タイトルをクリックで論文ページにリンクします)
・Variational Auto Encoder (VAE):
パラメータを確率分布で表現した変分オートエンコーダの提案論文。現在有力なオートエンコーダの大部分はこのVAEの構造をもとにしています。
・β-VAE:
複雑に絡み合った画像の特徴を、独立した成分に分解して扱う手法を提案
・VQ-VAE:
「ベクトル離散化」により高解像度の画像生成を安定して学習可能にした
最後になりますが、僕が以前に行った画像生成の研究をご紹介します。
・PoPGAN(点入力による植物の動画像生成モデル)

この研究では、画像に加えてアニメーションの生成に挑戦しました。GUIで2つの植物の形をマウスによる簡単な操作で指定して、写実的な成長アニメーションを作ることができます。今回紹介したGANとオートエンコーダの両方のモデル構造を取り入れて応用しています。
研究のデモムービーを↓のリンクから公開していますので、興味のある方は是非ご覧ください〜
今年の夏には国際学会でのポスター発表を行いました。リモートだったのがちょっと残念でしたが、CG・CV分野の興味深い研究発表を沢山見ることができて有意義な経験になりました。
さいごに
今回は2種類の主要な画像生成モデルの概要について簡単に説明しました。実際にはこれらのモデルを応用した具体的な研究が多数あり、その目的に応じてモデルの構成は改良されています。関連する研究の詳しい内容に興味のある方は、<主要な研究例>のところに紹介した論文などをぜひ調べてみてください👀
この記事を読んで、画像生成とはどのようなものなのか簡単にイメージし、興味を持っていただけると幸いです!
この記事が参加している募集
この記事が気に入ったらサポートをしてみませんか?