
文章から画像を生成するAI「DALL・E2」を使ってみた

文章から画像を自動生成する DALL・E2 が先日一般公開された。画像の商用利用も可能とのことなので、うまくすれば note 記事のアイキャッチ作成に使えるかもしれない。
使用は基本無料だが申請制である。かなり待ち行列が長いらしく、僕は7月6日に申請したら7月30日に通った。住所や職業や使用目的などの面倒な入力欄はなかった。SMS 認証があるので電話番号を取られる点だけ注意されたし。
テキスト(英文)を入力すると、15秒ほどで1024×1024の画像を4枚生成してくれる。初月は無料で50回、それ以後は毎月15回分のクレジットが発行される。もっと使うには課金が必要で、15ドル115回なので1回17円。OpenAI とか名乗っていながらずいぶん商業的なフリーミアム形態だが、ちょっと遊んでみる分にはちょうどいい。
とりあえず触ってみる
てっきり Python 等から API を叩くのだと思っていたが、普通にブラウザのフォームに文章を入れるだけでいいので、英語ができればプログラミング知識なしでも使える。さっそく使ってみよう。
Spherical Cow in A Vacuum
真空中にいる球形の牛
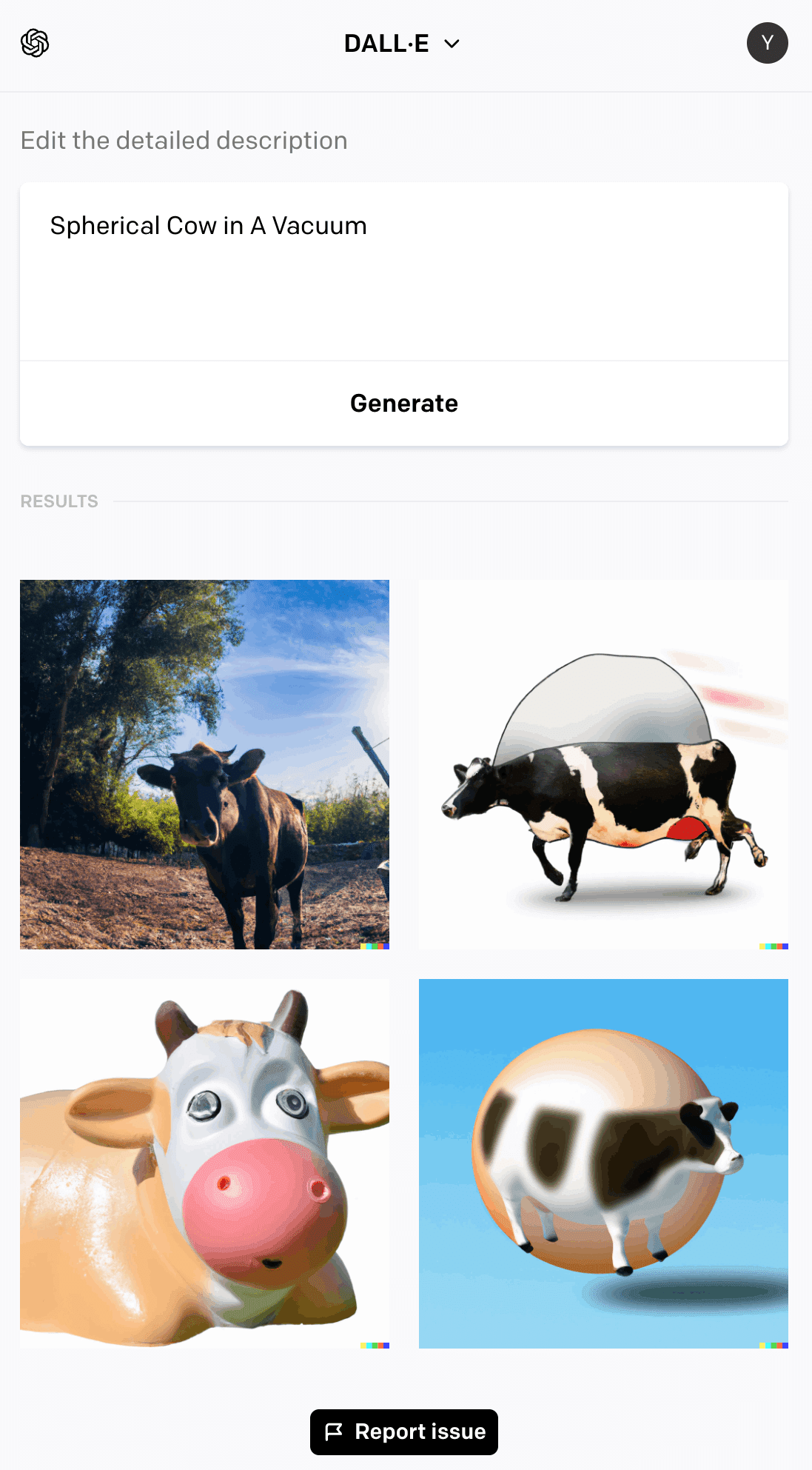
うーむ、想定と違うな。左上の画像は単なる牛だし、レンズが魚眼っぽいことくらいしか球形要素がない。左下は何が言いたいのかわからない。右下は比較的それっぽいが、球形の牛というよりは球と融合した牛である。
Tips によると「長くて具体的な文を書くといい感じのが出ますよ」とのことである。長い英文を書くのは疲れるので、ここからは翻訳サービス DeepL に丸投げすることにする。次は自分のアバターを作ってみるか。うまくいったら今後アイコンとして使おう。
ひとりの男がオフィスの椅子に座っている。彼には顔がなく、頭は立方体をしている。グレーのシャツと黒いズボンを穿いている。オフィスに他の人はいない。
A man is sitting in his office chair. He has no face and his head is a cube. He is wearing a gray shirt and black pants. There is no one else in the office.
「四次元立方体の展開図」が機械に通じるか不安なので、単なる立方体で試してみる。

お、かなり想定に近いぞ。「黒いズボン」と指定しているのに青いジーパンが出たりしているが。昔の感覚からするとコンピュータがこういう具体的なテキストを読み落とすのは不可解だが、今のAIはクソ厚いニューラルネットを通すことでいくつもの情報を削ぎ落としてしまうのだろう。
画像→文章→画像の再翻訳
次に、実際の写真をいったんテキストにして、それを AI に再現させてみよう。文章表現の練習によさそうだ。

田舎の風景写真。架線のない線路が手前から奥に向かってまっすぐ伸びている。線路の左側には緑色の畑がある。右側にはビニールハウスがあり、その奥には丘がある。遠くには住宅が立ち並び、さらに奥には青い山が見える。空は青く、雲は少ない。
Rural landscape photo. A railroad track without overhead wires runs straight from the front to the back. To the left of the tracks is a green field. To the right are plastic greenhouses, and behind them are hills. In the distance are rows of houses, and further back are blue mountains. The sky is blue and there are few clouds.

なかなかいいじゃないか。「右側」と指定したはずのビニールハウスが左側に出てくるのが気になるが。
編集機能を使う
DALL・E2 では生成した画像をもとに、ちょっと違う画像を再生成することができる。これもクレジットを1回分消費する。AI でもリテイクは有料であることを肝に銘じておこう。

また、画像中の気に入らない部分を消しゴムで消して、そこだけ再生成する Edit 機能もある……のだが、試しに電柱を消してみるとほぼ同じものが生成されてしまった。どうもAIのセンス的にはここに電柱がなくてはならないらしい。なかなか頑固だが人間にもこういうアーティストは多い。


アップロードした画像を部分的に消去し、そこだけAIに描いてもらう機能もある。試しにこないだ富良野で撮った写真をアップしてみよう。

黒服の忍者
Ninja dressed in black

うーむイマイチだ。右上は小さすぎて何なのかよくわからないし、左下は何も映っていない。忍者ゆえの隠密性と好意的に解釈すべきか。右下は比較的それっぽいが、どうもアメコミのザコキャラみたいで「忍者」に対する解像度の低さが否めない。このあたりは教師データが英語圏に偏っているゆえか。
版権キャラクターを描かせる
DALL・E2 で生成した画像は商用利用も可能とのことだが、版権のあるキャラクターを生成した場合、それを商用利用するのは版元の権利を侵害することにならないだろうか? 試しに有名キャラクターの名前を入れてみよう。
パーティ会場のイラスト。ひとつのテーブルにピカチュウ、ハローキティ、ドラえもん、ルフィが座って、並べられた料理を美味しそうに食べている。
Illustration of a party venue. Pikachu, Hello Kitty, Doraemon, and Luffy are sitting at one table, eating deliciously from the food laid out on the table.

4キャラ入れたのに全部ハローキティ、いやハローキティ風味の何かになった。推察するに、AIが各版元に問い合わせたらハローキティだけが出演OKしたのだろう。仕事を選ばないキティ先輩だけはある。日米で商習慣の違いとかあるだろうから、次はアメリカのキャラクターでやってみよう。
スパイダーマンとダースベイダーとポパイとミッキーマウスが麻雀をしている
Spider-Man, Darth Vader, Popeye and Mickey Mouse playing Mahjong.

今度はスパイダーマンだけになった(そして麻雀要素は消えた)。どうやらこの AI は版権キャラを1人しか出せないらしい。AI にも出演者のスケジュール調整は難しいんだろう。ということはハローキティを抜きにしてドラえもんだけを頼めば描いてくれるってことか。
どら焼きを食べているドラえもんのイラスト
Illustration of Doraemon eating dorayaki.

「青い・猫型・ヒゲ」といった特徴だけ押さえてるけどなんだこの「ドラえもんの風貌が口承で伝わっている地域が最近作ったゆるキャラ」みたいなデザイン。どら焼きの解釈もかなりブレてるし左下は明らかにハンバーガーだ。
名前を書かずに特徴を書いて版権キャラに寄せる、というのも試してみよう。
中年男性の写真。彼は口ひげをはやしている。青のオーバーオールの下に赤い長袖シャツを着て、白い手袋をしている。赤い帽子を被り、その帽子には大きく「M」と書かれている。右手を握りこぶしにして掲げて微笑んでいる。
Photo of a middle-aged man. He has a mustache. He is wearing a red long-sleeved shirt under blue overalls and white gloves. He wears a red hat with a large "M" written on it. He is smiling with his right hand raised in a clenched fist.

ああ、「口ひげをはやす」といった単一の要素はちゃんと指示通りになるけど、「赤」「白」「長袖」といった情報と「帽子」「手袋」「シャツ」といった情報をちゃんと結びつけてないぞ。単語は拾えるけど意味が理解できてないのではないか。左上のやつ、帽子には「M」だと言ったのに勝手に「L」を追加するな。兄弟愛か。
AI は意味を理解しているのか?
「AI は意味を理解できるのか?」というのはチューリングに遡る難題だ。この DALL・E2 はちゃんと入力文の意味を読解しているのか、それとも視界に入った単語をてきとうに拾って画像を構築しているのかを検証してみよう。
「ギターを弾いているシロクマ」という文が書かれた紙の写真
A photograph of a piece of paper with the text "Polar bear playing guitar."

「ギターを弾いているシロクマ」という文を書けと指示しても、ギターを弾いているシロクマの絵を描いてしまう。そしてテキストが添えられるところは入力文どおりだが、その内容は意味不明である(英語ですらない)。どうもこのAIは構文を理解できず、「シロクマ、ギター、テキスト、紙」といった情報を断片的にしか受け取っていなさそうである。
では次に、「夫婦」「親子」といった人間関係の意味を理解できるのかを試してみよう。
キッチンの写真。男性がナイフを持ってトマトを切っている。その隣にいる彼の妻が鍋でスープを煮込んでいる。その隣にいる彼女の夫がエプロンを着ている。
A picture of a kitchen. A man is cutting tomatoes with a knife. His wife next to him is simmering soup in a pot. Her husband next to her is wearing an apron.

おや、意外にもうまくいった。「トマトを切る男性」「スープを煮込む女性」「エプロンを着てる男性」の3人が生成されるのだろう、と思っていたのだが。「彼の妻の夫」が彼自身であることを、AI は理解しているのだろうか? 検証のために入力を少しだけ変えよう。
キッチンの写真。男性がナイフを持ってトマトを切っている。その隣にいる彼の妻が鍋でスープを煮込んでいる。その隣にいる彼女の息子がエプロンを着ている。
A picture of a kitchen. A man is cutting tomatoes with a knife. His wife next to him is simmering soup in a pot. Her son next to her is wearing an apron.

おお、「彼の妻の息子」は彼自身ではない、ということを AI がちゃんと理解している。思ったよりレベルが高い。ただトマトを切ってるはずの夫が後方腕組彼氏面をしていたり、画像から見切れてしまっている。ちゃんと家事に参加しろ。
では解釈の分かれる文章を入れてみよう。「彼の母親の息子」は彼と同一人物かもしれないし、兄弟かもしれない。
キッチンの写真。少年がナイフを持ってトマトを切っている。その隣にいる彼の母が鍋でスープを煮込んでいる。その隣にいる彼女の息子がエプロンを着ている。
A picture of a kitchen. A boy is cutting tomatoes with a knife. His mother next to him is simmering soup in a pot. Her son next to her is wearing an apron.

4枚出力されたが、どれも息子は1人きりである。どうやら AI 的には登場人物を最小限に押さえたいらしい。これは僕にも共感できるところがある。「彼の妻の息子の父親だが彼自身ではない」といった込み入った人間関係を考えるのは少々しんどい。
AI の考える各国の風景
AI が実用化されつつある現代で問題視されているのは「AI による差別」である。たとえば入力文に「CEO」と入れると白人男性ばかり出してしまう。このため DALL・E2 では「黒人」「女性」とかいった言葉を入力文に後付で追加しているらしい。
どうにもスマートさに欠けるアドホックな技術だが、そうした措置の是非はさておき、このAIが「各国の風景」をどう考えているのかを試してみよう。
日本の商店街。夏の午後。大勢の人が歩いている。
A shopping street in Japan. A summer afternoon. Many people are walking.

うむ。建物といい服装といい、全体的にどことも言い難いがどこかで見たような光景だ。看板に文字らしきものが一切書かれていないのが気になるが。次にここで国名だけを変えてみよう。
アメリカの商店街。夏の午後。大勢の人が歩いている。
A shopping street in United States. A summer afternoon. Many people are walking.

ぱっと見てわかる違いは、道が広い、看板が少ない、人種が多い、などである。僕の考える日米の違いにおおむね合致している。
中国の商店街。夏の午後。大勢の人が歩いている。
A shopping street in United States. A summer afternoon. Many people are walking.

他3枚は北京や上海といった大都市の雰囲気だが、右下だけちょっとテイストが違うな。これだけ土産物屋の並ぶ観光地という感じがする。全体的にピンぼけしていてわかりづらいが、髪型や服装にも日本との文化的差異が繁栄されている気がする。
まったく行ったことのない国も試してみよう。
ナイジェリアの商店街。夏の午後。大勢の人が歩いている。
A shopping street in Nigeria. A summer afternoon. Many people are walking.

なるほどなあ、とは思うが行ったことないので検証できない。頑張って探せば「AI のイメージと実体が全然違う地名」を見つけられそうな気もする。「アメリカ映画はメキシコを黄色く描きすぎ」ということが問題視されているらしいが、こういう要素が AI に組み込まれてしまう可能性はあるな。
商用利用してみよう
「商用利用が可能」とのことなのでさっそく商用利用してみよう。AI クイズ(答え有料)である。以下のイラストは、ある有名キャラクターの名前を AI 入力し、描いてもらった画像だ。

おわかりいただけただろうか。言うまでもなく Kirby(カービィ)である。左上は完全にスムージーになってしまったし右上も「KKPBY」という微妙な文字でカービィ性を表現しようとしているが、全体的にピンク色という最大の特徴を捉えているし、左下などはかなり元ネタのポイントを押さえている。
ということで以下5問出題します。ぜひチャレンジしてみてください。





売上が15ドルを超えたらクレジットを追加購入してもっといろいろ生成しようと思います。よろしくおねがいします。
ここから先は
¥ 100
文章で生計を立てる身ですのでサポートをいただけるとたいへん嬉しいです。メッセージが思いつかない方は好きな食べ物を書いてください。