CNNを用いた画像認識 -柑橘類の分類-

はじめに
AidemyさんのAIアプリ開発コースの最終成果物として、AIによる画像認識アプリを作成しました。本記事が今後、AIアプリの開発に挑戦する方にとって、少しでも役に立つと嬉しいです。
開発したアプリは、柑橘類(レモン、ライム、みかん、ゆず)を分類するものです。画像認識にあたって、CNN(Convolutional Neural Network)といったニューラルネットワークモデルを使いました。人間の脳の視覚野と似た構造を持つ「畳み込み層」という層を使って特徴抽出を行います。2次元の画像データを処理し線や角といった特徴を抽出した後、プーリング層で畳み込み層から得た情報を縮約し、最終的に画像の分類を行います。
以下、1~8の順番で作業を進めました。
実行環境
macOS Big Sur: 11.2.3
Python: 3.8.8
Visual Studio Code: 1.63.2
Google Colaboratory
1. 画像の収集
今回はKaggle(カグル)のデータセットを使っています。多様なデータセットが用意されているため、今回の柑橘類のような一般的な画像データであれば見つかると思われます。
■ 使用したデータセット:「Fruits-262」
■ データセット説明:
A dataset containing 225,640 images of 262 different fruits
量・種類ともに豊富であり柑橘類以外の分類にも活用可能
■ 取得枚数:4種それぞれ900枚ずつ
■ Kaggle:https://www.kaggle.com/
2. 画像の保存/マウント設定
画像はGoogleドライブに保存しています。Googleドライブ を Google Colaboratory にマウント(連携)することで、画像にアクセスが可能となります。以下のコードを実行するとGoogleの認証情報が求められるので、認証するGmailアカウントを選択し、処理結果のような表示が出ればマウント完了です。
# 実行
from google.colab import drive
drive.mount('/content/drive')Mounted at /content/drive3. モデル構築
まずはモデル部分の前にGoogleドライブから画像を取得し、学習できるように処理をおこないます。
# 必要なライブラリの取得
import os
import cv2
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.layers import Dense, Dropout, Flatten, Input
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras import optimizers
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
from google.colab import files
# Googleドライブから画像を読み込み
path_lemon = os.listdir('/content/drive/MyDrive/citrus/lemon')
path_lime = os.listdir('/content/drive/MyDrive/citrus/lime')
path_orange = os.listdir('/content/drive/MyDrive/citrus/orange')
path_yuzu = os.listdir('/content/drive/MyDrive/citrus/yuzu')
# 種類ごとの配列を作成
img_lemon = []
img_lime = []
img_orange = []
img_yuzu = []
# 種類ごとの配列に、データをリスト形式で保存
for i in range(len(path_lemon)):
img = cv2.imread('/content/drive/MyDrive/citrus/lemon/' + path_lemon[i])
img = cv2.resize(img, (300,300))
img_lemon.append(img)
for i in range(len(path_lime)):
img = cv2.imread('/content/drive/MyDrive/citrus/lime/' + path_lime[i])
img = cv2.resize(img, (300,300))
img_lime.append(img)
for i in range(len(path_orange)):
img = cv2.imread('/content/drive/MyDrive/citrus/orange/' + path_orange[i])
img = cv2.resize(img, (300,300))
img_orange.append(img)
for i in range(len(path_yuzu)):
img = cv2.imread('/content/drive/MyDrive/citrus/yuzu/' + path_yuzu[i])
img = cv2.resize(img, (300,300))
img_yuzu.append(img)
# リスト形式で保存した画像を、Numpy配列に変換
X = np.array(img_lemon + img_lime + img_orange + img_yuzu)
# 正解ラベルを用意
# 4種類の柑橘類に0~3のラベルを付与した状態
y = np.array([0]*len(img_lemon) + [1]*len(img_lime) + [2]*len(img_orange) + [3]*len(img_yuzu))
# 画像データをシャッフル
rand_index = np.random.permutation(np.arange(len(X)))
X = X[rand_index]
y = y[rand_index]
# 学習データ8割、テストデータ2割でデータを分割
X_train = X[:int(len(X)*0.8)]
y_train = y[:int(len(y)*0.8)]
X_test = X[int(len(X)*0.8):]
y_test = y[int(len(y)*0.8):]
# 混同行列による結果確認のために、one-hotベクトルに変換前のデータを確保
y_test_check = y[int(len(y)*0.8):]
# データをone-hotベクトルに変換
# one-hot ベクトルとは、(0,0,0,1) のような1つの成分が1で、残りの成分が全て0であるようなベクトルを指す。
# 上記の例の場合、(0,0,0,1) はゆず(yuzu)を表すベクトルとなる
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)今回はVGG16を使って転移学習による学習を行います。転移学習とは、既に学習済みのモデルを転用して、新たなモデルを生成する方法です。
ざっくり言うと、特徴を得る層だけもらって分類を行う層は自身で作ったモデルを使います。他の画像データを使って学習されたモデルを使うことによって、新たに作るモデルは少ないデータ・学習量でモデルを生成することが可能になります。
# 入力値を定義 (画像サイズ, 画像サイズ, チャンネル数(RGB))
input_tensor = Input(shape=(300, 300, 3))
# include_top:False に設定
# 元のモデルの畳み込み層による特徴抽出部分のみを用いて、それ以降の層に自分で作成したモデルを追加することが可能
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
# vggのoutputを受け取り、4クラスに分類する層を自分で追加
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dense(128, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(4, activation='softmax'))
# モデルの連結
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
# VGG16側の層の重みは学習時に変更されないように固定
for layer in model.layers[:19]:
layer.trainable = False
# コンパイル:まだ学習はしていない状態のため、指標を設定し学習するための方法を決定
# loss で損失関数の指定しており、どれだけ精度が出ているかという指標として使用
# 損失値小さい = 精度が高いと判断可能
# metrics には正解率で評価を行いため、accuracy を設定
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(lr=1e-4, momentum=0.9),
metrics=['accuracy'])
# 学習の実行
history = model.fit(X_train, y_train, batch_size=20, epochs=7, validation_data=(X_test, y_test))
# 精度評価:学習完了したモデルにテストデータを与え、evaluateメソッドを使って損失値を計算する
# 変数score にはインデックス0番目に損失値、1番目に正解率が入っているためprint関数で出力
scores = model.evaluate(X_test, y_test, verbose=1)
print('Test loss:', scores[0])
print('Test accuracy:', scores[1])
# 学習モデルを保存
result_dir = 'results'
if not os.path.exists(result_dir):
os.mkdir(result_dir)
model.save(os.path.join(result_dir, 'citrus_model_300_v3.h5'))4. モデル検証
3. で設定した通り正解率を確認します。また混同行列を使用して4種の柑橘類にどの程度分類できているか確認してみたいと思います。
# 正解率の可視化
plt.plot(history.history['accuracy'], label='acc', ls='-')
plt.plot(history.history['val_accuracy'], label='val_acc', ls='-')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(loc='best')
plt.show()3. の精度評価の結果が以下となり、テストデータを使って正解率80%を超えている。
- Test loss: 0.6642587780952454
- Test accuracy: 0.8291666507720947

# 混同行列
y_pred = np.argmax(model.predict(X_test), axis=1)
citrus = ["lemon", "lime", "orange", "yuzu"]
cm = confusion_matrix(y_test_check,y_pred)
cm = pd.DataFrame(data=cm,index=citrus,columns=citrus)
sns.heatmap(cm,annot=True,cmap='Blues')
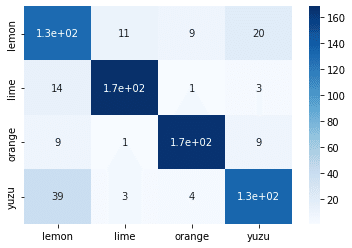
plt.show()混同行列を使うことであるデータを分類したときにその正解・不正解の数を整理して確認できます。
例えば今回で言うと、レモンのテストデータに対してレモンと予測した結果が、1.3e+02(130)個となります。逆にゆずのデータを与えた時は、39個レモンと判断していますが、色が似ているのもあり誤判断したのかもしれません。とはいえ、おおよそ分類できていることとします。
5. Flask側コード
学習したモデルを使ってアプリを開発するために、FlaskというPythonのWebアプリケーションフレームワークを使います。詳細は割愛しますが、これでブラウザから画像をアップロードし画像の分類が可能となります。
import os
from flask import Flask, request, redirect, render_template, flash
from werkzeug.utils import secure_filename
from tensorflow.keras.models import Sequential, load_model
from tensorflow.keras.preprocessing import image
import numpy as np
classes = ["レモン","ライム","みかん","ゆず"]
image_size = 300
UPLOAD_FOLDER = "uploads"
ALLOWED_EXTENSIONS = set(['png', 'jpg', 'jpeg', 'gif'])
app = Flask(__name__)
def allowed_file(filename):
return '.' in filename and filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS
# 学習済みモデルをロード
model = load_model('./citrus_model_300_v3.h5')
@app.route('/', methods=['GET', 'POST'])
def upload_file():
if request.method == 'POST':
if 'file' not in request.files:
flash('ファイルがありません')
return redirect(request.url)
file = request.files['file']
if file.filename == None:
flash('ファイルがありません')
return redirect(request.url)
if file and allowed_file(file.filename):
filename = secure_filename(file.filename)
file.save(os.path.join(UPLOAD_FOLDER, filename))
filepath = os.path.join(UPLOAD_FOLDER, filename)
# 受け取った画像を読み込み、np形式に変換
img = image.load_img(filepath, grayscale=False, target_size=(image_size,image_size,3))
img = image.img_to_array(img)
data = np.array([img])
# 変換したデータをモデルに渡して予測する
result = model.predict(data)[0]
predicted = result.argmax()
pred_answer = "これは " + classes[predicted] + " です"
return render_template("index.html",answer=pred_answer)
return render_template("index.html",answer="")
if __name__ == "__main__":
port = int(os.environ.get('PORT', 8080))
app.run(host = '0.0.0.0', port=port)6. HTML/CSSコード
最後にブラウザで表示される見た目を作ります。HTMLで構造を定義し、CSSで色やフォント、背景画像の設定をしています。
<!--HTML-->
<!DOCTYPE html>
<html lang='ja'>
<head>
<meta charset='UTF-8'>
<meta name='viewport' content="device-width, initial-scale=1.0">
<meta http-equiv='X-UA-Compatible' content="ie=edge">
<title>Citrus classification</title>
<link rel='stylesheet' href="./static/stylesheet.css">
</head>
<body>
<header>
<a class='header-logo'>Citrus classification</a>
</header>
<div class='main'>
<h2>これは、何の柑橘系?</h2>
<p>レモン、ライム、みかん、ゆずのどれかを当てます。</p>
<p>画像を送信してください</p>
<form method='POST' enctype="multipart/form-data">
<input class='file_choose' type="file" name="file">
<input class='btn' value="決定" type="submit">
</form>
<div class='answer'>{{answer}}</div>
</div>
</body>
</html>/* CSS */
header {
background-color: #FDF5E6;
height: 60px;
margin: -8px;
display: flex;
justify-content: space-between;
}
.header-logo {
color: #5F9EA0;
font-style: italic;
font: bold;
font-size: 25px;
margin: 15px 25px;
}
body{
position: relative;
margin: 0px;
background-image: url("./citrus_back.jpeg");
background-size:cover;
background-repeat: no-repeat;
}
h2 {
color: #20B2AA;
font-family: "Noteworthy";
margin: 120px 0px 50px 0px;
text-align: center;
}
p {
color: #20B2AA;
font-size: 18px;
margin: 10px 0px 30px 0px;
text-align: center;
}
.answer {
color: #444444;
font-size: 20px;
margin: 50px 0px 30px 0px;
text-align: center;
}
form {
text-align: center;
}7. モデル公開(デプロイ)
作成したアプリはHerokuにアップロードし公開しています。
https://citrus-app.herokuapp.com/
デプロイにあたって2点記述が必要になります。Flask側のコードの最下部に記載した内容です。
① hostの指定:サーバーを外部からも利用可能にするため
host='0.0.0.0'② ポート番号の設定:Herokuで使えるポート番号を取得してportに格納
port = int(os.environ.get('PORT', 8080))まとめ
初めはモデルって何??状態から始まったものの、何とか開発できました。
開発を進める中で苦労した点をまとめます。
1. 画像の収集
最終的に Kaggle のデータセットに行き着きましたが、それまでに icrawler を使ってみたり、ノンコーディングのアプリで Octoparse というサービスを使ってみたりと量を集めるのに苦労しました。画像をかさ増しする方法もあるので次回は試してみようと思います。
2. 精度評価
モデルを何となく構築できても、処理の意味を理解しないと最終的に評価ができないというのが一番大きな収穫だったと思います。今回で言えば、正解率をコード書いてサッと出力するのは良いものの、結局4つに分類できているのか深堀りできないので、混同行列を使ってみました。
この混同行列を使うために、処理途中の配列の形状やデータ形式を正確に把握する必要があり、print関数やshapeメソッドにお世話になりました。
最後に
Kaggle を使う前に画像を集めていた方法を書き留めておきます。既存のデータセットに画像がない場合には使えるかもしれません。
【icrawler】
以下のコードを実行すると、keyword_lists の画像を検索し、class_lists のフォルダに画像データを保存する
from icrawler.builtin import BingImageCrawler
keyword_lists = ["レモン","ライム","みかん","ゆず"]
class_lists = ["lemon", "lime", "orange", "yuzu"]
for i in range(len(keyword_lists)):
crawler = BingImageCrawler(storage={"root_dir": '/content/drive/MyDrive/citrus/' + class_lists[i]})
crawler.crawl(keyword=keyword_lists[i], max_num=50)【Octoparse → Tab Save】
■ Octoparse:
ノンコーディングのアプリケーション。Google画像検索から画像のURLを取得し、Excel形式でエクスポートが可能
■ Tab Save:
Google Chromeの拡張機能として利用可能。画像のURLを貼り付けると一括ダウンロードが可能
この記事が気に入ったらサポートをしてみませんか?