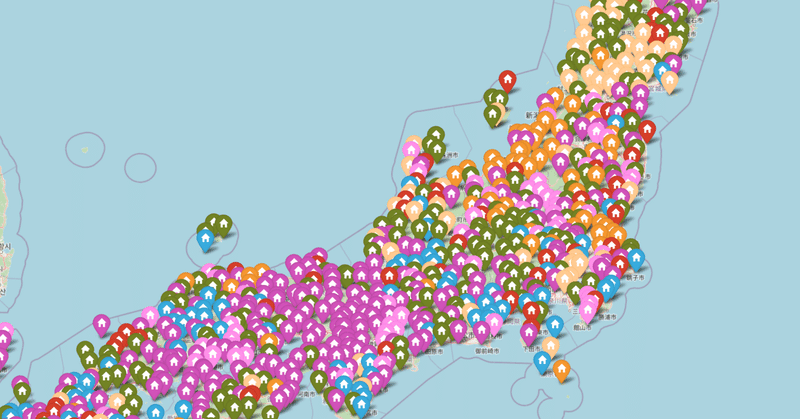
機械学習で「日本言語地図」を作る

ことしもアドベントの季節が来ました。この記事は、アドベントカレンダー「言語学な人々」2022の12月12日のエントリーとして書かれました。
★★★★
昨年は敬語の話を書いたが、今年はプログラミングのことでも書いてみよう。ここ2年くらい機械学習や深層学習のプログラミングを少しずつ学習できたので、自分でできることがかなり広がった。何か応用問題をやってみたくなって、言語地図を書いてみることに挑戦してみた。言語地図とは、言語地理学の中で発展してきたもので、特定の単語や音韻の、方言や、特定の言語による語形・音形を、その出現した地点の地図上に、アイコン化して配置したものとなる。たとえば、「かたつむり(蝸牛)」の言語地図では、方言形「マイマイ」の類を〇、「デンデンムシ」の類を△のように区別して表示するわけである。今回作ったものは、形でなく色で分けて、JavaScriptでインタラクティブにズームが動くようになっている。
まずはどんなものができるか、とりあえず、下の「かたつむり」の言語地図へのリンクを触っていただきたい。マウスのスクロールホイールでズーム縮尺の調節、ドラッグで地図の移動である。アイコンをクリックするとその地点の語形(ローマ字表記)がポップアップする。だいたい様子はご理解いただけるだろう。
日本言語地図・かたつむり(データ軽めバージョン・色も適宜)
言語地図とコンピュータ・GIS
もともと、言語地図はコンピュータとの相性がいい。アプリケーションとしても、古くはメインフレームの時代の荻野綱男氏のGLAPS、PCになってからの福嶋(尾崎)秩子氏のSEALなどが有名だ。大西拓一郎氏も、AdobeイラストレータやGIS系のアプリを駆使して言語地図を発表されている。Pythonを用いたものも、松浦年男氏、加藤幹治氏のものなどが公開されている。研究分野としては、いわゆるGIS(地理空間情報システム)ということになる。今回、屋上屋を架すことにはなるが、挑戦してみた新機軸は、言語地図の真髄とも言える語形の分類の自動化である。
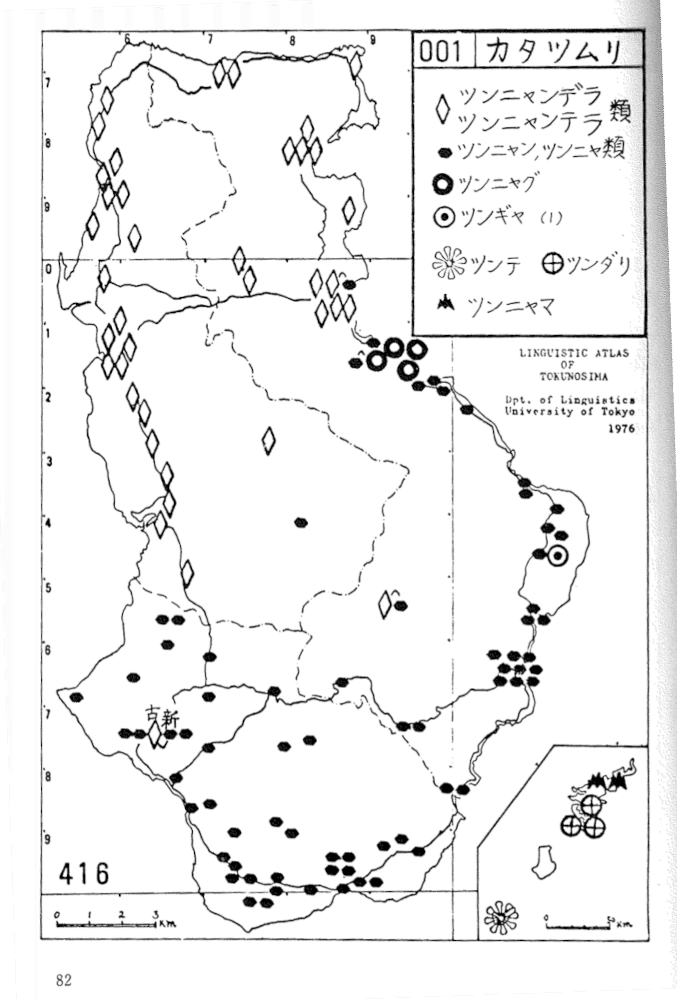
私は、学部生の頃、柴田武先生の言語地理学ゼミを履修していて、徳之島のフィールドワークにも行ったことがある。その頃(1970年代)の言語地図は、白地図に手作業でいろいろな形のゴム印の黒色スタンプを押して作っていたが、(カラーはまだ一般的ではなかったので)似た語形を類にまとめて、分布が見えやすいスタンプの「形」を使って、上手く描くというのが、ひとつの重要なノウハウだったのである。(下は、その調査の一部。『奄美徳之島のことば』(秋山書店・1977)から「カタツムリ」・各種語形をひし形と楕円との二類のスタンプに大別統合してあるのがポイント)
今回、言語地図の素材としては、国立国語研究所によって公開されている「日本言語地図」の緯度経度付き語形データ(このサイトにある)を使わせていただいた。「日本言語地図」は1960年代に作られた日本の代表的言語地図である。その「かたつむり」と「くるぶし」の項目データを用いる。「日本言語地図」の「かたつむり」の地図のオリジナル版はこのサイトにある通りで、非常に細かく語形ごとにスタンプを割り振ってある(あまりにも語形が多いので3つの地図に分割してある)。これを、ほぼそのまま再現することも技術的には可能だが、今回はちょっと趣向を変えてみたい。
語形のベクトル化とアイコン化
言語地図のメリットデメリット論はあるが、そこには今回は触れず、先にあげた言語地理学のノウハウである、語形によってスタンプ(以下、アイコン)を変えることを自動化してみる。方言語形は非常に多様で、「かたつむり」の方言形のひとつである「ナメクジ」系にしても、「ナメクシ・マメクジ・ナメクジリ・ナメラ・ナメクジナ」など極めて多くのバリエーションがある。これらをひとまとまりとして、「マイマイ」系や「デンデンムシ」系などをまとめたものと、はっきりと区別するように表示したいわけである。だから、今回は、数百種ある語形をせいぜい10種以内に統合する(かなり異なった語形も統合されるので、従来の非常に詳しい言語地図とはやや性格が異なるが、「語形の統合」が言語地図のポイントではある)。
現在はきれいなカラーが使えるので、アイコンの形は同一とし、色だけを変えてみた。具体的には、語形を多次元ベクトル化してから、各語形の地図の全地点の語形ベクトルを次元圧縮をして低次元にし、それをクラスタ分類してアイコンの色に変換する方法をとった。
語形をベクトル化するための計算方法はいろいろと考えられる。今回は、文書ではないので、文脈情報を使うことはない。純粋に語形(形態)だけの情報を使うこととする。語形(文字列)の類似度の指標としては、レーベンシュタイン距離などがあるが、言語地図の場合にはいろいろと考えるべきことがある。たとえば、仮名単位(モーラ)で「メダカ」(medaka)と「メタガ」(metaga)を比べた場合、明らかに直感的・語源的には似ているが、文字列(モーラ列)としては「メ」以外は一致していないのでレーベンシュタイン距離は遠くなる。少なくともモーラ単位のレーベンシュタイン距離は、歴史的関係などを捉えるには不適切である。
今回は簡単でわかりやすい方法として、方言の回答語形(英字大文字のみでローマ字で書かれている)を文字に分解して、文書分類などによく使われるBoW(Bag of Words)をキャラクタベースで行い、ローマ字1字ごとに扱うこととした。つまり、Bag of Characters あるいは、Bag of character Ngrams ( N = 1 )である。 次のように、アルファベットの26次元のベクトルを用意し、それぞれに語形内(この例は「デンデンムシ DENDENMUSI」)の各文字の使用頻度を入れる。つまり、このベクトルはある単語の語形(の構成音素)の持つ母音・子音の分布と頻度情報を持っていることになる(ここでは N = 1 ( unigram )なので、字の順序情報は入っていない)。
DENDENMUSIの語形音素ベクトル
[ 0 0 0 2 2 0 0 0 1 0 0 1 2 0 0 0 0 1 0 1 0 0 0 0 0 ]
a b c d e f g h i j k l m n o p q r s t u v w x y z
この語形音素ベクトルを地図ごと(地図により、それぞれ1500から2800余の語形がある)に、PCA(主成分分析)で適宜次元圧縮して、K-Meansでクラスタに分ければ、音素ベクトルの特徴量によって語形アイコンの色分けができるはずである。このように音素の特徴量を使えば、「コロコロ」と「カラカラ」の類似性などが捉えられる(モーラではまったく別語形!)。この機械学習部分は普通にscikit-learnのライブラリを用いた。あとは、語形の特徴で分類、色づけしたアイコンを、当該語形の出現した調査地点(緯度・経度)に貼り込むだけである。地図への貼り込みはPythonの地図用ライブラリのfoliumを用いた。また地図はfoliumの標準のOpenStreetMapを用いた。なお、次元圧縮には、PCA以外に、LSAとNMF等を試したが、それぞれにメリットがあるようだ。別途報告したい。
動的な「日本言語地図」の作成
プログラム全体(ipynbファイル)は筆者のGitHubにあげておくが、標準的なもので特別な処理もなく、Colaboratoryで動くようにしてあるので、このままColaboratoryバッジのところからクリックしていただければ問題なく動作するはずである。(資料ExcelファイルをGoogleドライブに持ってくるようにしてあるので、JupyterNoteBookの方は適宜御変更下さい。ソースに注釈が入れてあるので何をしているかはすぐにおわかりと思います。)出来上がったマップはJavaScriptで動くものになるので、単体のHTMLページに保存して出力してやれば、冒頭で示したように、それ自体を縮尺自在な動的な地図として使うことができる(今回はWebサーバーに置いてあるが、ローカルPCでもかまわない)。下にいくつかのパターンをHTMLページでサイトにあげてみた。アイコンの色数や、圧縮の次元数などを変えると微妙に違うアイコンの色使いになるのでおもしろい。人間の感覚とは異なる部分もあるが、よく見ると機械学習による分類の方が妥当と思われることもある。なお、「カタツムリ」では、全2400地点余のアイコンを全部載せると、ページが重くなるので、プログラム冒頭の定数の設定で、3分の1程度に間引いてある。これは自由に変えられるので、その定数値nを書き換えていただきたい。「かたつむり」の地図でわかるように、「カタツムリ」「デンデンムシ」「マイマイ」「ダイロ」「ナメクジ」など主要な語形は色分けされて示されている。
今後の課題 ベクトルで扱う形態論
お使いになってどうだろうか。非常におおまかではあるが、これだけでも、言語地図の語形の分布を概観するのに、とりあえずの、実用になるように思う。大量のデータを完全に自動的に分類でき、また、従来のスタティックな地図よりも、このfoliumでは、拡大・縮小ができるだけでもかなり違う。現状では色使いそのものは機械的にクラスタに割り振ってあるだけで、語形の類似とは直接の関係がないのであるが、今後、語形の類似と色の類似を関係づけて(似た語形は似た色になるよう)、もうすこしわかりやすくする予定である。また、語形がベクトル化できたので、地図の重ね合わせや、分布図同士の比較なども、従来の手作業や勘ではなく、いろいろと計算できそうな感じである(複数の地図を総合してベクトル化すればよい)。時間があればいろいろやってみたい。(プログラムソースではコメントアウトしてあるが、そこを生かすと、クラスタ化したものをプロットできるので語形ごとに分類状態を比較すると面白い)。非常に単純なプログラムであるが、意外に世界的に見ても、言語地図の機械学習処理例はないようである。
なお、国語研究所のサイトにある「新日本方言地図」のデータでも同じようなことができる。こちらは語形が片仮名なので、ローマ字変換を噛ませる必要があるが本質的には同じで、簡単に同様な作業ができたことを御報告しておく。もちろん、仮名文字(=モーラ)そのままのBoCでもほぼ同じにできるが、そのことによる結果の差異はまた別途報告したい。また、「似た語形」をうまくベクトル化できる手法としては、今回の音素のunigramのBag of character Ngramsをbigramにするとか、いろいろと考えられそうで、むしろそれによって、分布の解釈自体を刷新していくことができるという点に将来性を感じる。bigramにしても、キャラクターベースなのでさほどスパースになるわけではない。また、今回は元データがローマ字だったが、音声表記(IPA)ベースの語形データの場合は、音声字母のベクトルで計算することになるが、基本は同じである。
また、今回は地図の描画にはもっとも簡便なfoliumを用いたが、Pythonを使うなら、GeoPandasのような、GML(Geographic Map Language)による地図データを扱えるライブラリで地図を書き、その上にBokheのような描画アプリで、語形アイコンをマッピングするというようなことも考えられる。また、folium自体もGeoJSONを扱えるので、それを媒介にして、様様な言語地図データを、コロプレス地図のような形でもハンドリング可能である。
言語地理学は、もちろん方言研究であるが、日本語史研究と深い関係がある。語形や音形の分布は、何らかの形で、過去の言語変化を反映しているからである。そういう意味では、広義の日本語史研究ということになるのである。歴史的日本語言語資源・自然言語処理・地理空間情報の横断領域ということにもなるので、歴史的変化と重ねる形で、今後さらに研究を進めたいと思う。また、言語地図だけでなく、さまざまな言語学的な「語彙」のデータベースが存在するが、それを「分類整理」するために、ベクトル化を行い、研究に機械学習・深層学習の助けを得るということは広く考えてよい課題だと思う。意味論のほうは、単語分散表現の発達でvector semanticsという考え方が広まりつつあると思うが、形態論の方も今回のようなやり方で、vector morphologyとでもいうべき分野もありうると考えられる。
(謝辞)本研究にあたっては、lajdb(日本言語地図データベース)のサイトのデータを活用させていただいた。データベース作成の大西拓一郎氏・熊谷康雄氏や関係の皆様に感謝申し上げます。
読んでいただきありがとうございます。ツイートなどしていただけるとうれしいです。