
VRAM 4GBではじめるStable Diffusion - ゲーム素材を作ろう1 - 環境構築

この草稿は、VRAM 4GB環境下で『Stable Diffusion』を利用して、ローカルでの画像生成をするためのものです。生成する画像はファンタジー系の同人ゲーム/インディーゲームの画像素材です。この草稿は、2023年の2月下旬~3月上旬にかけて執筆されました。
草稿をまとめて大幅増補したものを電子書籍で出しました。『Kindle Unlimited』ユーザーの方は無料で読めます。是非読んでください。
この草稿では『Stable Diffusion』の簡単な解説をおこない、『AUTOMATIC1111版 Stable Diffusion web UI』の導入や使い方について説明します。また「背景」「キャラクター」「アイテム」「絵地図」「UI部品」といった画像素材の作成方法を説明します。
この草稿は、私が2022~2023年に、同人ゲーム『Little Land War SRPG』を開発した時の知見を中心にまとめたものです。こちらも購入して遊んでいただけると幸いです。
本章の概要
本章では「画像AI普及の経緯」「筆者の実行環境」「画像AIの環境構築方法」を扱います。
環境構築方法については、『AUTOMATIC1111版 Stable Diffusion web UI』の導入や、学習モデルの入手や配置、VAEの追加について触れます。
また、VRAM 4GB(NVIDIA GTX 1050 Ti)という低スペック環境で、どういったバッチファイルの設定にすればよいのかを解説します。
以下、本章の目次です。
画像AIの爆発的な普及
筆者の実行環境
環境構築
ソフトのインストール
「webui-user.bat」の実行
学習モデルの入手
学習モデルの配置
「webui-user-my.bat」の作成
「webui-user-my.bat」の実行
学習モデルを追加する
VAEを追加する
素材作成の目標
画像AIの爆発的な普及
2022年は画像AIが爆発的に広がった年でした。
前年の2021年からその萌芽はありました。2021年にはOpenAI社による『DALL·E』が発表され、翌2022年4月には『DALL·E2』が招待制になり、7月20日にベータ版が公開されました。この頃はまだ「すごいものがあるなあ」と遠い場所の何かを見るような目で、私は画像AIをながめていました。私以外の多くの人も、似たような状況だったと思います。
こうした画像AIが一般に下りてきて、爆発的に話題になったのはMidjourney社による『Midjourney』の登場です。2022年7月12日にオープンベータとしてサービスを開始して、Twitterなどを中心に大量の画像が流れ始めました。
――すごい画像が短時間で生成できる。
――「呪文(プロンプト)」を利用して画像生成を制御できる。
魅力的な玩具を与えられた子供たちのように、ネットの多くの人たちが画像AIに触れて、その出力結果と情報を共有しだしました。
この流れを一気に加速させたのが、2022年8月22日、Stability Ai社による『Stable Diffusion』のオープンソース化です。ある程度のGPUが載っているマシンであれば、自分のパソコン上で画像が生成できる。『Google Colab』を利用すれば、GPUが非力なマシンでも利用できる。そうした環境が提供されたのです。
『Stable Diffusion』の登場で、画像AIの利用は「はるか高いところにある神々の道具」から「手元で遊べる人間の道具」に変わりました。私自身も『Midjourney』は指をくわえて見ていましたが、『Stable Diffusion』はすぐに触れて、いろいろと試し始めました。
そこからの進歩は超速でした。『Stable Diffusion』を使う環境を自動でインストールするソフトの登場、WebブラウザーのUIで使うためのプログラムの開発、それらが全てパックになった環境の提供。そして多くのフィードバックを得ながら、様々な環境でも動くようにツールは進化していきました。
私も、最初はそうしたツールを『Google Colab』で利用していました。しかし、ツールの対応環境が充実してきた段階で、ローカルに移行して自宅のパソコンで実行するように変わりました。
筆者の実行環境
筆者が利用している実行環境を書きます。OSはWindows10です。パソコンのグラフィックボードは『NVIDIA GTX 1050 Ti』です。このグラフィックボードは、3Dを駆使したゲームをするには非力ですが、ビジネス用途には十分という性能です。
名前:NVIDIA GTX 1050 Ti
製造元:NVIDIA
表示メモリ(VRAM): 4018 MB
VRAMは4GBとなっており、『Stable Diffusion』を動かすには下限の数値です。省メモリー設定で実行しなければ不安定になり失敗します。また1枚生成するのに1分ほどの時間がかかります。可能ならばより高性能のグラフィックボードを購入した方が快適に画像生成をおこなえます。そして学習は非力すぎてできません。
このように性能が低いグラフィックボードですが、逆に言うと、より多くの人にとって身近な環境とも言えます。世の中は高性能のマシンばかりではありませんので。
自身が現在使用しているグラフィックボードの確認は、Windowsであれば以下の方法でおこなえます。
デスクトップの「ここに入力して検索」(虫眼鏡アイコン)から「dxdiag」を検索して実行する。
「ディスプレイ1」タブを選択して、「デバイス」の「名前」を確認する。
本稿を読み進める前に、ご自身のパソコンのグラフィックボードの名前を確認して、ネットでその名前を検索して、どういった性能や位置づけの商品なのかを確かめておくとよいでしょう。
次に、実行しているツールについて書きます。筆者が利用しているツールは『Stable Diffusion web UI - AUTOMATIC1111』(以降「Web UI」)です。このソフトウェアは、必要な環境を自動でインストールして、Webブラウザー経由で操作することができる「全部入りのセット」です。
AUTOMATIC1111/stable-diffusion-webui: Stable Diffusion web UI
https://github.com/AUTOMATIC1111/stable-diffusion-webui
この『Web UI』は、アップデートの頻度が高く、改良ペースが速いです。そのため、本稿とのズレはあると思います。その際は、その都度、最新の情報と読み換えていただければと思います。
こうした、最新のツールを使う際には、公式ドキュメント自体が、最新の内容に追い付いていないことも多いです。ブログなどを検索して、有志の知見を吸収しながら利用していくことが必須となります。
環境構築
本稿の内容を実際に試すには、Windowsパソコン環境で、『Web UI』が動くことが前提になります。
ローカルに環境構築するのが面倒、あるいはマシン性能の問題で無理という場合は、ネットに公開されている『Google Colab』で利用できるバージョンを探して利用するとよいです。過去では、無料枠の範囲内で『Web UI』を実行することができました。2023年4月21日以降に規約が変更になり、有料版(1ヶ月あたり1000円ほど)でないと『Web UI』の利用ができなくなりました。こうした環境は、刻々と変化します。
それでは以下、ローカルへの環境構築の方法を書いていきます。
ソフトのインストール
環境構築は、公式サイトの「Automatic Installation on Windows」を見て、順番にソフトをインストールして、実行コマンドを実行していきます。
AUTOMATIC1111/stable-diffusion-webui: Stable Diffusion web UI
https://github.com/AUTOMATIC1111/stable-diffusion-webui
基本の流れは「Pythonのインストール」「gitのインストール」「gitを利用したAUTOMATIC1111/stable-diffusion-webuiのインストール」です。その後、学習モデルの入手や、「webui-user.bat」の書き換えや実行があります。
最初の3つは、単純なソフトのインストールやコマンドの実行なので、特に問題なく進みます。注意すべき点は、公式に書かれている『Python』のバージョンをインストールすることです。異なるバージョンをインストールすると、動かないなどのトラブルが起きます。
こうした環境構築の手順ですが、方法が変わる可能性があるので必ず公式の手順を確認してください。またインストールするフォルダーは、Cドライブ直下にフォルダを作るなど、ネストが浅い方がよいです。インストールの過程で、多くのフォルダが作成され、大量のファイルがダウンロードされます。パスが短い方がトラブルが少なくなります。
「webui-user.bat」の実行
「<インストール先>/webui-user.bat」を実行してインストールを開始します。コマンド プロンプトが開き、インストールが始まります。
実は、『git』で『Web UI』を導入した時点では、インストールは完了していません。初回実行時に、必要なファイルをネットからダウンロードして環境を構築します。「続行するには何かキーを押してください」と出たら、キーボードのキーを押してコマンド プロンプトを終了します。
学習モデルの入手
学習モデル(model.ckpt)の入手は『Hugging Face』というサイトからおこないます。
Hugging Face – The AI community building the future.
https://huggingface.co/
『Stable Diffusion』本家の学習モデルには、いくつかバージョンがあります。現時点では、1.1、1.2、1.3、1.4、1.5、2.0、2.1 があります。私は、1.4の時点でゲームの素材を作りました。私の把握の範囲内で、各バージョンの違いを解説しておきます。
1.1~1.4は、基本的にバージョンが高いものを利用するとよいです。これらは、Stability AI社から出ています。1.5は、Runway社から出ています。『Stable Diffusion』の研究主体は、CompVisという大学の研究グループで、そこにStability AI社とRunway社が出資しています。そのせいで公開元が違います。1系統なら1.5を使えばよいです。
学習モデルは、いずれも4GB以上あります。時間のある時にダウンロードするとよいです。
また、以降のURLで出てくる学習モデルには、拡張子が「.ckpt」のものと「.safetensors」のものとがあります。「.ckpt」はチェックポイントファイル、「.safetensors」は「.ckpt」を改善した形式のファイルです。「.safetensors」安全性が高まり、高速な処理が可能になっています。
それでが学習モデルを入手しましょう。
1.4の学習モデルは以下で入手可能です。「sd-v1-4.ckpt」をダウンロードします。ファイルサイズは4.27GBです。
CompVis/stable-diffusion-v-1-4-original at main
https://huggingface.co/CompVis/stable-diffusion-v-1-4-original/tree/main
1.5の学習モデルは以下で入手可能です。「v1-5-pruned-emaonly.safetensors」をダウンロードします。こちらも4.27GBあります。
runwayml/stable-diffusion-v1-5 at main
https://huggingface.co/runwayml/stable-diffusion-v1-5/tree/main
2.0は、1系統の知見をもとに、新しく作られた学習モデルです。生成画像の精細さが増して、画像サイズも大きくなりました。その分、VRAMを多く利用するので、非力なグラフィックボードでは厳しいです。また、画像AIが苦手な手などがきれいに出やすくなっています。そして、さまざまなアスペクト比で破綻なく画像を生成できます。実写風の人体や、ワイドな景色などを作る際には優秀な結果を出せます。
本稿執筆時点では2.1が最新です。2.1の学習モデルは、以下で入手可能です。5.21GBあります。2.1では、画像の1辺が512ピクセルが基準となっているものと、768ピクセルが基準となっているものがあります。後者の方が、より多くVRAMを使います。VRAM 4GB環境なら、512ピクセル版を使った方がよいです。
画像の1辺が512ピクセルが基準となっているものは、以下のURLから入手可能です。
stabilityai/stable-diffusion-2-1-base at main
https://huggingface.co/stabilityai/stable-diffusion-2-1-base/tree/main
768ピクセルが基準となっているものは、以下のURLから入手可能です。
stabilityai/stable-diffusion-2-1 at main
https://huggingface.co/stabilityai/stable-diffusion-2-1/tree/main
emaとnonemaと書いたファイルがありますが、画像生成だけをおこなうならemaと書いた方でよいです。VRAM 4GB環境なら、512ピクセルの「v2-1_512-ema-pruned.safetensors」を選ぶとよいでしょう。こちらをダウンロードしてください。
以下、余談です。
『Stable Diffusion』の1.X系統では、誰かの画風をそのまま真似る行為などが批判されました。2.0は、こうした批判を避けるために制限がかけられました。公開後に、この制限に苦情が出て、若干ゆるめたのが2.1です。
こうした経緯がありますので、私の中ではリアルで精細な画像が欲しいなら2系統、特定画風の画像を作りたいなら1系統がよいのではないかと考えています。ゲームの素材という目的なら、1系統の方がよい結果が出る可能性もあります。また1系統の方がVRAMをあまり要求しないので、低スペックのグラフィックボードでも安定して動くという利点もあります。
学習モデルの配置
学習モデルをダウンロードしたら適切な場所に配置します。以下のフォルダに、ダウンロードしたファイルを配置します。
<インストール先>/models/Stable-diffusion/
2系統以降の場合は、さらに追加の作業が必要です。以下のページの「.yaml files for sd 2.x models」にある、対応したファイルの「config」をダウンロードします。
Dependencies · AUTOMATIC1111/stable-diffusion-webui Wiki
https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Dependencies#yaml-files-for-sd-2x-models
そして以下のフォルダ内にコピーします。さらにファイルの名前を「v2-1_512-ema-pruned.yaml」のように、「配置したファイル名と同じもの」にリネームします。
<インストール先>/models/Stable-diffusion/
<インストール先>/models/Stable-diffusion/v2-1_512-ema-pruned.safetensors
<インストール先>/models/Stable-diffusion/v2-1_512-ema-pruned.yaml
この「.yaml」ファイルを配置する作業は、いずれ不要になるかもしれません。2系統が中心になれば、デフォルトで対応するようになるかもしれません。
いずれにしても、最初は1つだけ学習モデルを配置して、最初の実行まで作業をした方がよいです。最初の起動を待たずにいろいろと入れて上手くいかなかった場合は、原因が分からなくなります。
『Web UI』では、実行後に学習モデルの切り替えができます。しかし、トラブルを避けるためにシンプルな構成でまずは試してください。
「webui-user-my.bat」の作成
実行用のバッチファイル「webui-user.bat」のコピーを作り編集します。以下のファイルをコピーして、同じフォルダに「webui-user-my.bat」を作ります。
<インストール先>/webui-user.bat
<インストール先>/webui-user-my.bat (コピーしたファイル)
そして「webui-user-my.bat」の「set COMMANDLINE_ARGS=」の行を「set COMMANDLINE_ARGS=--medvram --xformers」に書き換えます。
set COMMANDLINE_ARGS=
:: ↓
set COMMANDLINE_ARGS=--medvram --xformers「--medvram」がVRAMが少ない環境での設定です。これでも上手くいかない場合は「--lowvram」を試してください。
「--xformers」は省メモリーと高速化のための設定です。「--xformers」を設定すると、画像再生成時に若干画像が変わります。それを嫌う場合は、この設定を使わないようにしてください。
最終的に「webui-user-my.bat」は以下のようになります。
@echo off
set PYTHON=
set GIT=
set VENV_DIR=
set COMMANDLINE_ARGS=--medvram --xformers
call webui.bat「webui-user-my.bat」の実行
「webui-user-my.bat」を実行します。必要なファイルが不足している場合は、自動でネットからダウンロードとインストールをおこないます。「--xformers」の引数を設定していると、初回実行時に『xformers』用のファイルが導入されます。
「Running on local URL: http://127.0.0.1:7860」と出たら、Webブラウザー経由でアクセス可能になります。私の環境だと3~4分ぐらいでしょうか。「http://127.0.0.1:7860」をWebブラウザーで開きます。バッチファイル実行時に開いたコマンド プロンプトは閉じないでください。こちらが『Web UI』の本体です。
「Prompt」入力欄に単語を入力して「Generate」ボタンを押せば画像が生成されます。『Web UI』とコマンド プロンプトに、途中の進行状況が棒グラフで表示されます。
学習モデルを追加する
ダウンロードしたファイルを以下のフォルダに配置します。2系統の場合は「学習モデルの配置」を参考にしてyamlファイルを追加します。
<インストール先>/models/Stable-diffusion/
『Web UI』の一番上にある「Stable Diffusion checkpoint」の横にあるリロードボタンをクリックします。配置したファイルがドロップダウンリストに反映されます。ドロップダウンリストを開いて、配置した学習モデルが追加されていることを確認してください。
学習モデルを変更した場合は「Loadings...」と表示されて、しばらくの時間、読み込みを待機する必要があります。数分から10分以上の時間がかかるので、頻繁な切り替えには向いていません。
学習モデル(.ckpt or .safetensors 形式のファイル)は、本家以外でも作成・配布されています。2次元キャラクターを学習したものなど特定の用途に特化して学習したものが多数ネットで公開されています。ゲーム用の素材を作る場合には、こうした学習モデルを使い分けるとよいです。
以下に、いくつかの学習モデルを挙げておきます。アニメ系キャラ(2次元キャラ)に強いものです。逆に、キャラクター以外の画像(背景や品物)を作るのは、本家の学習モデルの方が上手くいきます。
naclbit/trinart_derrida_characters_v2_stable_diffusion at main
https://huggingface.co/naclbit/trinart_derrida_characters_v2_stable_diffusion/tree/main
上記は『AI Novelist/TrinArt』サービスで利用されていたものと同じモデルが公開されたものです。
hakurei/waifu-diffusion-v1-4 at main
https://huggingface.co/hakurei/waifu-diffusion-v1-4/tree/main
こちらもアニメ系キャラに強いです。
2次元系の学習モデルは、無断転載サイトの『Danbooru』を学習元としてよく使っています。これはタグの数が非常に多く、画像と単語の対応を取りやすいためです。非常に有用ですが、無断転載サイトを使用していることで問題視する人も多いです。
学習モデルについては、「Stable Diffusion モデル」で検索すると、リンクをまとめたページが多数見つかります。
VAEを追加する
これは特に必須ではありません。「VAE」は「Variational Auto-Encoder」の略で、「画像←→潜在変数(内部的なパラメータ)」の変換を行う部分です。この部分を差し替えることで画質を上げることができます。目や文字などが潰れにくくなる「VAE」が公開されています。
stabilityai/sd-vae-ft-ema · Hugging Face
https://huggingface.co/stabilityai/sd-vae-ft-ema
上記にある「VAE」は、「train steps」の数値が大きいほど精度が高いです。
入手した「VAE」は、以下のフォルダに配置します。
<インストール先>/models/vae/
そして『Web UI』の「Settings」タブの左列「Stable Diffusion」をクリックして、「SD VAE」で、配置した「VAE」を選びます。設定を変更していない場合は「Automatic」になっています。
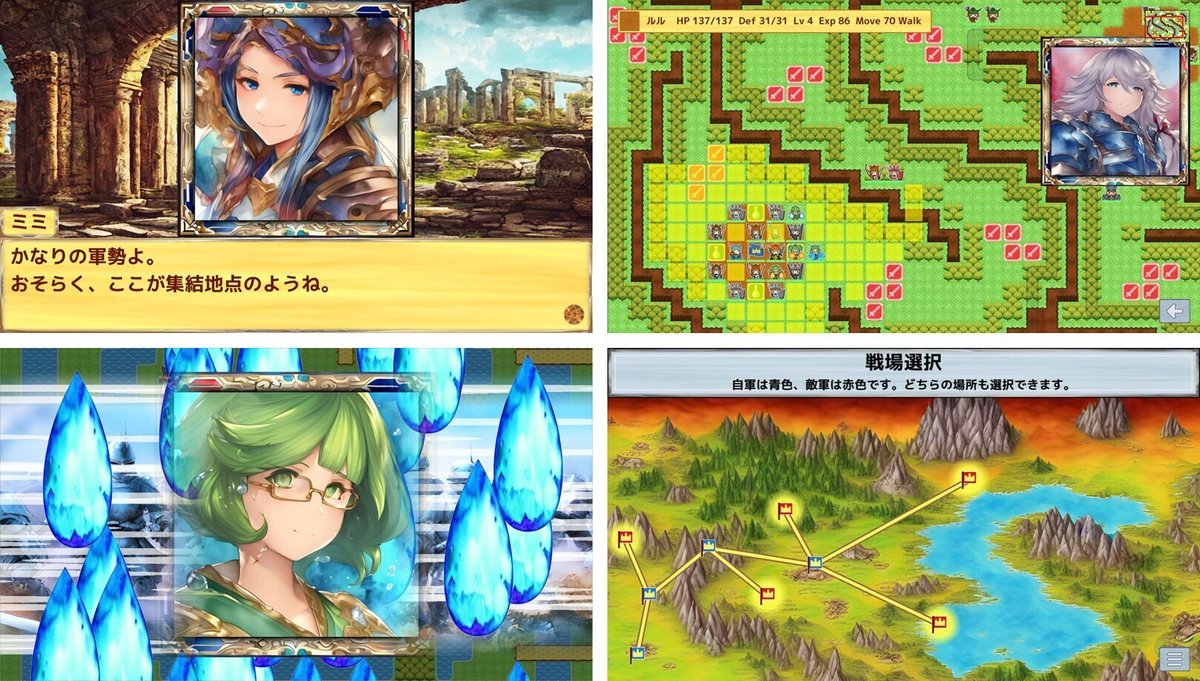
素材作成の目標
本稿では、様々なゲーム用の画像素材を作っていきます。最終的には以下のようなゲーム画面の素材を『Stable Diffusion』で作れることを目指します。
拙作『Little Land War SRPG』では、背景画像、キャラクター画像、武器や道具の画像、絵地図画像、ダイアログなどのUI部品を『Stable Diffusion』で生成しています。

(続く)
全体目次
★★★第1章 環境構築★★★【今ここ】
第2章 基礎知識
第3章 呪文理論
第4章 背景画像の生成
第5章 キャラクター画像の生成
第6章 キャラにポーズを付ける
第7章 キャラを学習させる
第8章 武器や道具の生成
第9章 絵地図の生成
第10章 UI部品のテクスチャの生成
※ 草稿をまとめて大幅増補したものを電子書籍で出しました。『Kindle Unlimited』ユーザーの方は無料で読めます。是非読んでください。
この記事が気に入ったらサポートをしてみませんか?