
LayerXにおけるLLM以降の業務自動化の世界とAi Workforce

先日Ai Workforceについて発表しました。エンタープライズ向けの文書処理業務をサポートするローコード・ノーコードツールと銘打っています。発表といっても、アプリケーション自体は限られたエンタープライズ企業のお客様のみに向けて展開している状況です。そのため、内容については良くわからないという方が多いものと思っています。
ですので今回はLLMの先に何を見ているのか、LLMと業務自動化ということについて書いてみようと思います。
ちなみに本件に関連してイベントも開催しますので皆様のご参加お待ちしております。
非構造化データの変換
世の中一般で扱われるデータ、特に今回のフォーカスである文書は、ソフトウェアが扱いやすいような形式のデータではありません。文字の羅列であって、「非構造化データ」であるといえます。LLM以前のソフトウェアにとっては、このデータは〇〇である、という意味が理解できないので、人間が意味のある「構造化データ」に変換する必要があります。
構造化データがあれば、例えば後段の業務で使うシステムにデータを連携したり、その後検索して別な業務でも活用するなどが実現しやすくなります。システムとシステムが繋がり、より効率的に業務が行えるようになります。例えばバクラクでは、構造化された請求データやクレカの支払データを会計ツールや銀行等のサービスと連携する仕組みを提供することで、よりよいUXを作ってきました。受け取った紙やPDF等の請求書をシステムと接続することで新しい価値を作っています。

こうした構造化する作業は、これまでMachine Learningにおいて専用のモデルを作ることで実現してきました。もちろん、専用の高精度で十分に速いモデルを作るにはコストが掛かります。これを許容できるのは、十分な市場規模があったり、かかっているコストの大きい領域に限られていました。例えばバクラクでは請求書という枚数や市場が相当に大きい一般的な領域に、専用のMLモデルを構築して提供する事業であると言えます。
LLMの登場は、この構造化を広く提供する契機となっています。Promptを変えることで多くのデータを構造化する能力をもつ汎用的なモデルであり、チューニングの容易さは革命的だと感じています。もちろん専用のモデルと比べればスピードや精度の面で劣る部分もあるかもしれませんが、モデルの高度化・効率化に伴い業務を実現するには十分と言える仕組みにもなりつつあると言えます。

以前のMLモデルと比べて、課題からモデルの構築までの距離が非常に短くなった、実装して実務で活かすまでの距離が相当に効率化されたのだと感じています。様々な、バラエティ富む業務が現実には存在しますが、そのそれぞれに適応したモデルを作るまでが、過去はデータを大量に集め、整理し、モデルを構築し、評価し、投入するプロセスが必要でした。一方で、LLM以降はPromptや元のデータの簡単な加工でも出来てしまうのは驚異的と言えます。これまでの機械学習的な取り組みのステップをだいぶ短縮しています。もちろん実業務においては精度評価等専門的な部分も残りますが。
要は「なんでも簡単に使いやすい形に加工するエンジン」として見たLLMは、プロダクト設計において大きな変化点なのではと感じています。
これまでの国内のLLM活用の流れ
一方で、国内におけるLLM活用、特にエンタープライズの世界に目を向けてみると、この1年ちょっとの間では法人版ChatGPTの取り組み、およびRAGを使ったPoCが多く見受けられました。
法人版ChatGPT、つまり社内でセキュアな環境でChatインターフェイスでLLMを使いたいというニーズは確かにあるのだと思います。実際私も日々の業務で相当な頻度でChatGPTやClaudeを触っていますが、もはや欠かせないツールになりつつあります。
またRAGは取り組みが、入口では容易なものと言えます。文書をセットし、質問に答える、というのは表面上は文書を分割して埋め込み表現を計算して何らかのVector Search Engineを通じて検索して回答を生成する、というのは取り組みがしやすく、一歩目では良いアウトプットに見えるものが手に入ったりします。
ですが、これらChatやRAGのような仕組みはあくまで一つのユースケースでしかありませんし、広くLLMの恩恵を受けるという意味では課題も大きいものだと感じています。機械学習の世界では散々議論されているものではありますが、Chatというインターフェイスの難しさ、そして検索の難しさという壁に突き当たります。
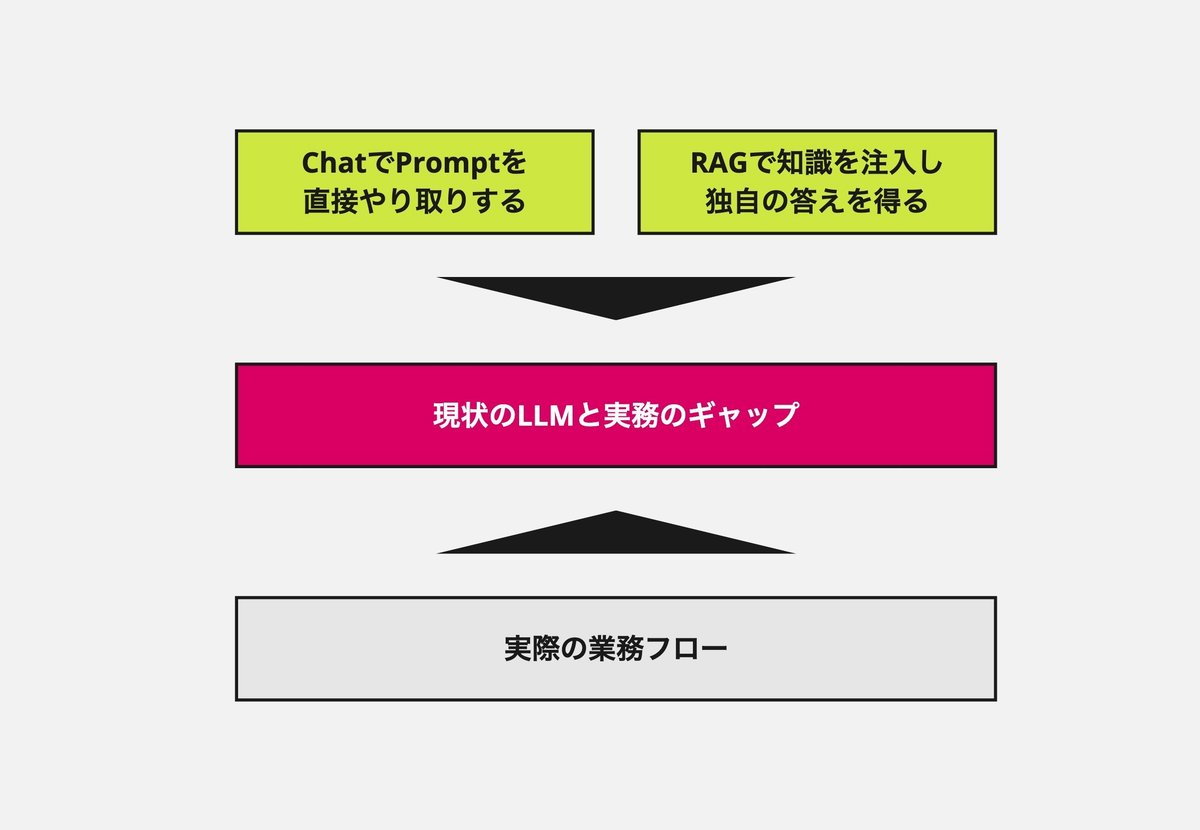
Chatインターフェイスは、LLMが良い回答を生成するにあたって必要とする「良いPrompt」のチューニング責任を一人ひとりの個別のユーザーに強いるインターフェイスです。そして良いPromptは誰もが即座に理解できるものとは言えず、どうしても個人のスキルに依存するところとなります。テンプレート機能などで緩和できる、とはいえ今度は乱立するテンプレートの問題にも突き当たります。結果として法人ChatGPTはMAUでみても導入から数ヶ月すると10~30%台まで低下しているというお話を我々自身も多く見聞きしました。
またRAGの背景にあるRetrieveは、Vector Searchで簡単に実装出来ているように見えて、その実はなかなか良い性能に到達しないケースが多いものです。そもそもユーザーの入力する質問は検索キーワードとして適切かという問題もあります。それに加え検索エンジンに登録されたファイルも、例えばマニュアルのVersion1とVersion2が同時に含まれていることによって、変更前の情報を取得してしまって誤った回答を作る、などデータの整理の難しさに突き当たることになります。その他情報検索には様々な考慮すべき点があり、非構造化データからのよいRetrieveは専門的なものとなります。
ですので、ChatもRAGもLLMの扱いに慣れてきた玄人には便利だが、万人向けではないといえます。
RAGの次、がもっと必要
一方で、参入のしやすさと短期的には売れるという背景もあってか、日本はChatGPTの登場以降、法人版ChatGPTがブームになり、そこにPrompt Template共有と簡単なRAGで社内文書からそれっぽい答えを作る、ところまでは進んできました。その次の取り組みで止まっている状況を多く見聞きします。ちなみに先日AWS Summitの展示会場を回っていましたが、RAGの文字だらけでした。多くはAmazon KendraとBedrockの組み合わせで作られているようですね。

ユーザーである大企業からはChatやRAGにチャレンジし、次どうしよう、という悩みをよく伺うようになってきました。RAGの次に挑んでいるソリューションもまだまだ少ない状況で、実務とのギャップは個別のAI系の受託プロジェクトとして、PoCで少しずつ埋められていこうとしてます。

ただし、LLMの特性から考えると、その適用範囲は非常に広いものになります。我々の見ている範囲でも、一つの企業で数十〜数百という活用ユースケースが出てくることもありました。実際に現場で考えうるユースケースの数を考えると、過去のAIプロジェクトの進め方だけでは全くスピードが足りないという課題もあるのではないでしょうか。たくさんのプロダクトが登場し、様々な領域で同時多発的に状況を変わっていく未来も願っていますが、現時点では全くプロダクトが足りていないようにも思います。
ちなみに海の向こうはWorkflow系ツールやバーティカルSaaS×LLMで新たな体験が多々生まれています。例えばDifyやBrex Empower。DifyはLLMに外部ツールを接続し、LLMの呼び出しやRAGなどを多段階で組み合わせて複雑なLLMでの処理を実現するサービスです。日本でもユーザーが増加しつつあるように見ています。またBrex Empowerは、AI・LLMをビジネスクレジットカードを中心とした経理向けサービスに組み込むことで経費精算等の自動化を目指しているようです。
Ai WorkforceはRAGとAgentの隙間
この「RAGの次」にあたるものの1つとして、実務で使える領域を目指したのがAi Workforceです。昨年LLMのR&Dを開始して早い段階でChatサービスはやらない、誰でもすぐ作れるものは事業にしないというのは決めていまして、正直結構悩みながらもチームと議論しながら現在のサービスに行き着いています。
Ai WorkforceはLLMに限らず様々なアルゴリズムモジュールを組み合わせつつ、文書業務で使えるWorkflowエンジンです。MLOps Platformというよりは愚直に業務に合わせたモジュールを組み合わせるもので、例えばIR資料を読んで、社内のデータベースに転機するべき内容を抽出し、整理するといったお仕事の中で活用いただけるものとなっています。他にも、社内稟議において、その稟議書の作成から評価であったり、過去の稟議データを整理して活用できるようにする、であったりと様々な文書処理に関するユースケースに対応可能です。
なぜ文書業務に絞っているかですが、それが多くの大企業や金融のような重い産業で共通した課題だったというのがあります。LayerXでは三井物産デジタル・アセットマネジメントという証券会社がグループにありますが、そこでは大量の文書を読み、整理し、共有するという業務がそこかしこに存在します。そこにはChat的インタラクションは不要で、ある程度型はあり人間にとっては単純労働的な業務が展開されています。
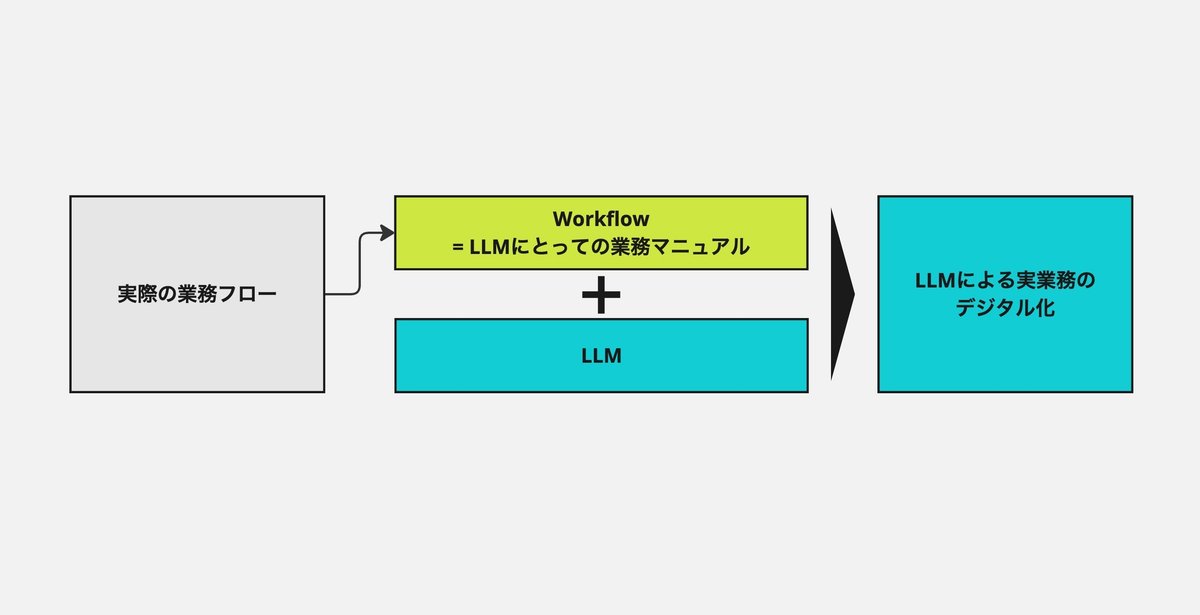
LLMのための業務マニュアル
ある程度型があるものの、これまで機械では処理できなかった、ないし専門のモデルを作るにはコストやデータ量が見合わず人間がこなしてきた業務を社内では「知的単純労働」と呼んでいます。こうした業務は業界問わず存在する、かつ個別性の強い業務でもあります。
この個別性をなるべく受け止め自動化する上で、LLMの性質、つまり多様なデータを構造化する力が生きていきます。業務の入力となる文書を、業務の方法に合わせて処理するこのステップをLLMに伝える事ができれば、多くの業務をデジタル化できるものと思います。
こうした仕組みを考えるとLLMに取り組んでいる方々の中からはエージェントの話が出てくるのではないかと思います。エージェントとは自律的に業務の方法をLLMが処理できるタスクに分解し、タスクを割り当て実行し、それを集約してアウトプットを作るエンジンのことです。例えばこの書類から稟議を上げてほしいと指示された場合に、稟議のルールをまず社内で探し、そのルールを分解しタスク計画を行いLLMを呼び出すなどしてアウトプットを生成する、という取り組みを自律的に行えるものがエージェントです。

私は未来にはLLMが自身でタスクを設計しこなす時代が来ると思っています。ただ、現段階のLLMの性能では、特にタスク計画までのステップで複雑な問題になるほどエラーが多い印象をもっています。計画ステップで一つでも誤ると後段のタスク実行で全く見当外れな答えを作ってくる可能性があります。

特に文書業務のようなアウトプットの型が決まっており構造化する必要がある場合、今は本当に型の決まった業務を自動で正確にこなすには精度が低いといえます。インターネットから記事を集めてそれっぽい文書を作る、というのは型がなくそれっぽい答えがすぐ作れますが、それ以上の自動化は難しいのが現状です。それっぽいアウトプットでよい知的に単純でない労働では役に立つ可能性もありつつ、我々がフォーカスする文書処理業務では正しい構造化が求められる以上使いづらいものになります。
この業務自動化において、Ai Workforceは現在とAgentの実現の隙間のプロダクトであるとも言えます。タスクの計画が難しい、であったり、アウトプットの精度に懸念が残ることを前提に置き、人の力とLLMを上手く組み合わせることでエージェントの誕生を待っています。沢山のモジュールを整えることによって、エージェントが上手く連携できる環境を作っているとも言えます。
LLMならではに挑戦したい
文書処理専門のワークフローエンジンを通じて、バクラクよりさらに広い単純な業務を自動化し、全ての経済活動のデジタル化に貢献していきたいと考えています。前述の通り、LLMによる業務の効率化範囲は非常に広いものです。そのデジタル化への活用・実現に向けては、お客様に直接我々がお届けするだけでなく、ユーザーである企業の皆様自身やAI系の受託プロジェクトや業務・システムコンサルティングを行っている企業の方々など、関わるすべての方々を加速していかねばと考えています。
ですので、Ai WorkforceはあくまでPlatformであり、ツール群として作り込んでいく汎用性高いプロダクトとして開発を続けています。LLMに仕事の仕方を教え、業務を高速にデジタル化へ進める新たなPlatformとして成長させていきたいと思っています。
そのうえで、プロダクトとしては、LLMやNLP系アルゴリズムの開発はもちろん必要ですが、どちらかと言うとお客様にLLM等のモジュールを使いやすくお届けするためのフロントエンド開発や、安定してタスクを処理するためのワークフロー基盤などのバックエンド開発、更にこれらのアーキテクチャを考え安定・安全に運用するためのSRE等のソフトウェア開発者をむしろ必要としています。
また、バクラクで我々が理解したのはUXの力でした。より良い使い勝手を作るという意味ではデザイナの存在が欠かせません。様々なお客様のセキュリティ要件に対応し、かつより良いAI-UXをお届けするプロダクトを実現するチームを目指したいと考えています。そのために現在各ポジションをオープンしていますが、本当にどこもかしこもやることだらけの新規事業です。
今後、なるべく早いタイミングでプロダクトをグローバルで展開していくことも検討しています。日本のエンタープライズ企業というのはグローバル企業であることも多く、その要件に追従していく意味でもグローバル展開は欠かせないものと思っています。
スタートアップ、LLM、グローバル、そういったキーワードに興味のある方、複雑なPlatform的プロダクトの開発にご興味のある方、その他LayerXにご興味のある方、ぜひカジュアルにお話させてください。
8/6にはLLMに関連したイベントも開催します。ご参加をお待ちしております。
AI・LLM事業部(Ai Workforce)採用情報
この記事が気に入ったらサポートをしてみませんか?