MNTSQの契約書解析を支える技術

こんにちは!リーガルテックベンチャーのMNTSQの取締役をしている堅山と申します。
面接等で、そもそもリーガルテックってどんなタスクを解いているの?という疑問をいただくことが多いです。今回は、前回の記事に続き、MNTSQでどのような問題に取り組んでいるかを書こうと思います。
MNTSQでは、法律事務所向けに「法務デューデリジェンス」という業務を効率化するプロダクトを作っています。法務デューデリジェンスとは、M&Aなどをするにあたって、対象となる会社のリスクを法的な面から評価する作業です。具体的には会社の結んでいる契約書などの法的な効果を持つ書類をまるっと読み込んでリスクである内容をまとめていきます。ほとんどの契約書は紙で締結されていますので、これらをスキャンしてもらい、主にPDFなどでデータを受領します。ある程度のサイズの会社であればドキュメントの数は数千に達し、負荷のかかる作業です。多くの事務所では資料を紙に印刷し、分担して読み込んでいるようです。
印刷するとすごい量になることも多いらしいです

MNTSQは、主に以下の2つの点で、弁護士の負担を軽減しています。
1. 対象会社の契約書などをOCRし検索可能にすることで、今まで印刷して紙をめくって調べていた業務を効率化
2. さらにリスクのある可能性がある条項をリストアップし、ダブルチェック機能を提供
上記を実現するプロセスには多くのタスクが含まれ、NLPの総合格闘技的な構造になっています。いろいろなタスクがあることを知ってもらい、「契約書解析」に興味を持っていただけると嬉しいなと思っています。
なお、今後は、これらの技術を生かして、企業向けのプロダクトも作っていこうと思っているのですが、基本的な流れは同じです。
Step. 1 OCR & Correction
まず、PDFなどの契約書のスキャンデータをOCRし、テキストデータを読み取ります。が、OCRの性質上どうしても誤認識が発生し、下流のタスクに悪影響を与えることがあります。OCRの結果から、法務ドキュメントであることを利用して、さらに修正をかけていきます。ルールベースや、単純な単語頻度による修正を適用するだけでなく、BERTのようなニューラル言語モデルの活用を研究しています。
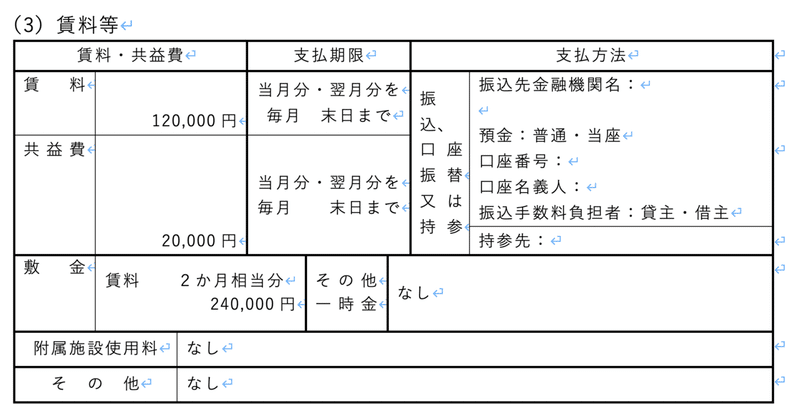
また、契約書には図や表が存在することもあります。予め処理する図表の構造が定まっている場合は対応できるのですが、一般の契約書は様々なフォーマットがあり、汎用的な対応方法はまだまだ検討中です。
割と簡単な表でこんな感じ・・・
また、契約書には手書きの部分があったりするので、場所を特定したりもしたりします。そこを本当は手書きの内容のOCRをできればよいのですが、ここはまだまだできていないところです。
契約書ってサインしたり、日付をその場で書いたりしますよね

Step. 2 契約書の分類
テキストが抽出できたら、内容の精査に入ります。「賃貸借契約書」や「秘密保持契約書(NDA)」など、契約書には様々な種類があります。そして、契約書の種類によって、書かれ方もリスクを見るべき観点も大きく違います。そこで、まず契約書の種類を分類します。
Step. 3 構造解析
さらに、契約書がどういう構造になっているのかを解析します。
普通の契約書はツリー構造をしています。例えば、以下の条では「乙は次の行為をしてはならない。」の下に、「①本件契約…」「②本件建物…」がぶら下がっています。このネストが数段になっている場合もあります。

こういった構造をテキストやレイアウトから推測しています。
さらに、以下の「第7条1項」のように他の条項へのリンクがついていたり、

「前条」のように相対的なリファレンスがついていたりします。

文レベルでは、代名詞の照応解析が必要であったり、文書レベルでは、付表がついていたり、別の契約書を参照用に挟み込んでいたり、他のタスクも実際の契約書は非常に複雑なので、構造解析タスクはまだまだやることがたくさんあります。
Step. 4 Named Entity Recognition
契約書の実態は紙なので、契約書を特定するときには紙に書かれている以下の情報を使います。ファイル名だけでなく、あの「賃貸借契約書」、どこだったかな〜と思いながらユーザーは検索をおこなったりするわけです。
1. タイトル
業務委託契約書
2. 契約当事者
甲 = A株式会社
乙 = B株式会社
3. 契約締結日
2020年2月10日
そこで、文からこれらの範囲を検出する必要があります。
検出すべき項目は契約書のタイプごとにたくさんあります。他にも例えば契約期間などを抽出しており、今この契約書が有効なのかどうかを判断できる場合に有用です。MNTSQでは検出できる項目を徐々に増やし、精度を上げています。ユーザーは検出項目を使って、数千の契約書から「株式会社Aと株式会社Bが結んでいる契約書の一覧」をみる、といった検索ができるようになっています。
さらに、ただ抽出するだけでなく、OCRや表記ブレを考慮する仕組みを作っています。OCRの結果、「MNTSQ株式会社」が「MNTSO株式会社」になったりすることがあります。同じ社名でも契約書によって微妙に書き方が違う(英文字でか書かれている場合とカタカナで書いてある場合がある等)場合があったりします。こういったNERしたEntityの名寄せにも取り組んでいます。
Step. 5リスク条項の検出
構造解析をおこなった結果から、危険な箇所を見つけていきます。危険な条項の例としては、「任意解約権」があります。任意解約権は、契約期間の途中でも契約を一方的に解除できる条項です。例えばあるメーカーを買収するとして、重要な販売契約について、相手が任意解約権を持っていたら、買収した途端にその契約が解除され、そのメーカーの収益が大幅に減少する、といったことも考えられます。MNTSQでは、このような買収者にとって危険な条項をいろいろチェックしています。
MNTSQでは特に、Recall(見逃さない率)を高めになるように目指しています。弁護士のダブルチェックとなることが重要ですので、多少間違えたものを拾っていても、網羅性が高くなるようにしています。
もちろんPrecisionをあげる方法もいくつか研究しており、例えば、係り受け解析を用いて、誰にとってリスクのある条項なのか?を分析しています。例えば、「乙は、甲に対して少なくとも30日前に解約の申入れを行うことにより、本契約を解約することができる。」という条項があるとします。この場合、買収する会社が「甲」なのであれば、任意解約権を行使されいつでも契約を解除されてしまう恐れがあり危険なのですが、買収する会社が「乙」なのであれば、自分が任意解約権を持つ側なので買収者にとってはリスクではありません。構文解析をすると、ここからは(乙は, 解約することができる)と言う係り受けを抽出でき、この情報を使って危険でない条項を出さないようにしてあげることができます。ただ、法務DDの場合は「乙」が誰で、それは買収する会社なのか、その取引相手側なのか、といったことを判定してあげる必要があるので、いろいろなタスクの精度を検証しつつ進めています。
契約書解析の目指すところ
契約書は普通の文に比べるとかなり文体が統制され、意味ができるだけ一意になるようになっており、NLP的な解析がやりやすいデータです。
一方で、どこまでいっても最終的に判断を行う人が不要になることはないなと実感しています。例えば、リスクのある条項が見つかったとして、それがどれくらい依頼者にとって重要なのかは、買収対象の企業のビジネスモデルであったり、依頼者が重視していることが何かで変わってしまうでしょう。
契約書解析の役割はあくまで、そのための判断材料をいかに高速に精度よく提供できるか、だと考えています。今までは時間をかけて紙をめくって調べていたことが、MNTSQによって効率化されることで、法務に関わる人々が、より重要な人にしかできない業務にフォーカスできるようなソフトウェアの開発を目指しています。
MNTSQでは、NLPの総合格闘技である契約書解析に一緒に取り組んでいただける機械学習エンジニアの方を募集しています。
この記事が気に入ったらサポートをしてみませんか?