
#4 マネフォが実践する「MF on SSOT」な分析基盤の構成

マネーフォワード分析推進室でデータマネージャー(DRE、データ整備人)を担当しています。
今回は、マネーフォワードの管理会計/分析環境の屋台骨を支える分析基盤の構成(システムの詳細ではなくビジネスロジック)についてお話しします。マネーフォワードの分析基盤においては Single Source of Truth(以下SSOT)という概念に基づいてデータ品質を担保するよう取り組んでいます。
記事末尾に本連載の一覧をつけておりますので、あわせてご覧ください。
マネーフォワードの「データガバナンス」
分析推進室が扱うデータは、高度なスキルを持ったエンジニアのみならず営業やマーケターさらには経営者といった多くのユーザーが扱うことを想定したものです。幅広い層のユーザーにデータを適切に扱ってもらうため、以下のポイントを重視して分析基盤を構築しています。
・データは常に一元管理し定義や役割を明確にする
・データのニーズを明確にし不要・不明なデータを扱わない
・分析者がデータ保護やプライバシーといったリスクを考えなくても取り扱える状態にする
私たちはこれらをデータガバナンスと呼んでいます(一般的なデータガバナンスの定義とは異なる部分もあります)。私たちが考えるデータガバナンスは、データ管理を行う上で中核となる要素の集合でありデータ管理そのものではありません。
「SSOTなデータガバナンス」とは
本稿では、データガバナンスの中でも特にSSOTと密に関係する「データは常に一元管理し定義や役割を明確にする」という観点を中心にデータライフサイクル(収集, 保存, 整形・分析, 探索・可視化)に沿ってマネーフォワードの分析基盤構成を解説します。
SSOTな分析基盤をひとことで表すと「誰でも迅速かつシンプルにデータへアクセスし分析できる環境」です。よって、この環境を実現するための構成も必然的にシンプルなものになり、特殊なことや新規性のあることは行っていません。
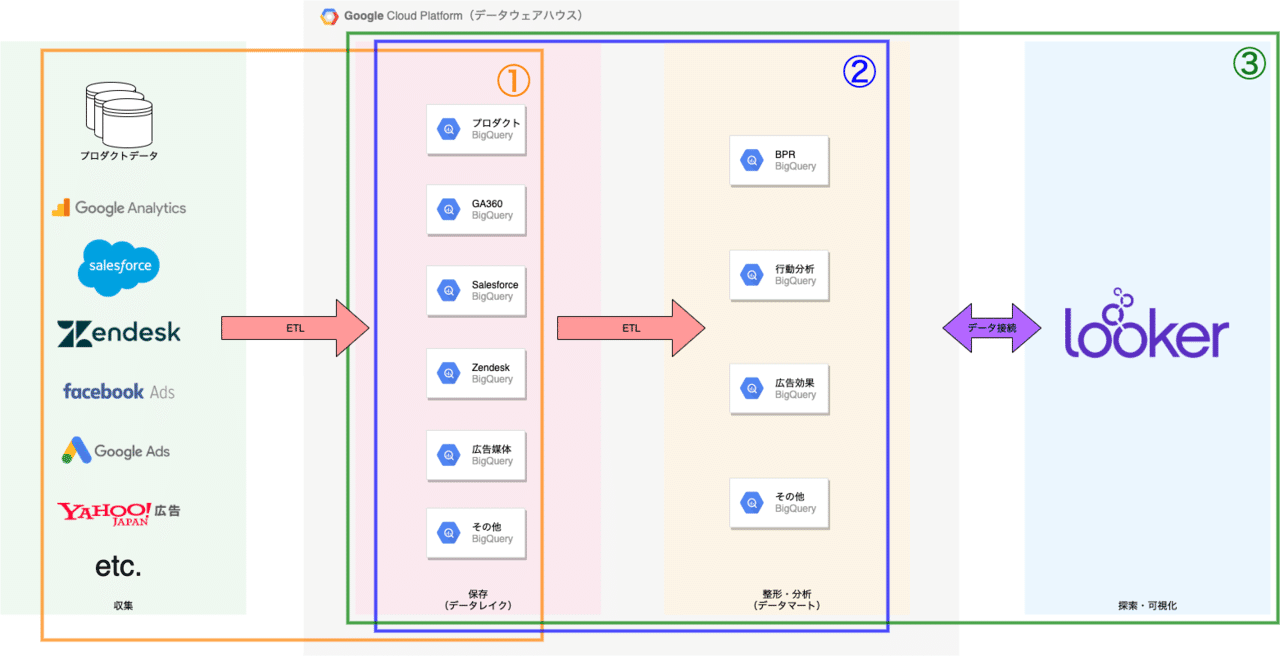
(構成図)
①データウェアハウスにあらゆるデータを保存する
構成図の①について解説します。分析基盤の中核を担うデータウェアハウスにBigQueryを採用しました。BigQueryにプロダクトデータやSaaSツールのデータを保存することで分析におけるシングルソースを実現しています。
マネーフォワードでは数年前から各プロダクト・サービスのMySQLで扱っているデータをEmbulkとDigdagを用いてBigQueryに保存しています。
EmbulkとDigdagを中心としたプロダクトデータの収集基盤は今後Apache Airflow(Cloud Composer)にリプレイスする予定ではありますがBigQueryに保存するという前提が変わることはありません。
Google アナリティクス 360、Salesforce、ZendeskなどのSaaSツールで取り扱うデータや広告媒体データについてもBigQueryに保存しています。データ保存手段は以下のとおりです。
・Google アナリティクス 360
→標準のBigQueryエクスポート機能
・Salesforce
→Fivetran(追加オブジェクトへの対応が不要でデータ同期の質が高いため採用)
・Zendesk・広告媒体データ等(APIによるデータ抽出が可能なツール)
→Apache Airflow(Operator、Hookなどを作成し適宜対応)
・Google 広告
→BigQuery Data Transfer Service
BigQueryにデータを保存する時点で個人情報などのセンシティブな情報を含むカラム(他のカラムと組み合わせることで個人を特定できるようなカラムを含む)を取り除き、分析者がプライバシーリスクを考慮することなく扱える状態にしています(CISOを筆頭とした数名のデータ管理責任者による持ち出しに関するレビューを必須とし、プライバシーリスクを取り除いています)。
プライバシーリスクになり得るデータのみ取り除いた、限りなく生に近いデータを保存した層を、私たちはデータレイクと呼んでいます。
※プロダクトやSaaSツールでデータを収集する際のデータ検証については本稿では扱いません。
②データマートをサイロ化させない
構成図の②について解説します。前述のデータレイク内のデータに対して整形・分析を行い保存する層をデータマートと呼んでいます。SSOTに基づきデータマートのサイロ化(情報が連携されず個々で独立してしまう状態)を防ぐ必要があります。
データの整形内容はBigQueryの標準クエリ構文で定義し、ワークフロー(データ更新順序などの依存関係とデータ更新スケジュールをまとめたもの)をApache Airflowで実行します。クエリによるデータ整形定義とワークフローは一つのレポジトリで一元的に管理され、分析推進室によるレビューを必須としデータマートのサイロ化を未然に防いでいます。
また、BigQueryと相性の良いData Catalogといったメタデータ管理サービスを利用し、ユーザーがデータウェアハウス上のあらゆるデータを一元的に把握出来るようにする取り組みも行っています。
③Looker(BIツール)による可視化・データ探索
構成図の③について解説します。マネーフォワードの分析基盤では可視化・データ探索ツールとしてLookerを導入しました。
前項までの内容は主にSQLのリテラシーを持つユーザーが対象でしたが、SQLのリテラシーを持たないユーザーが社内の大多数を占めています。こういったユーザーでも簡単かつ迅速にデータへアクセス出来るよう、分析推進室のBI担当を中心に前述のデータレイクやデータマートをLookerに接続し、LookMLと呼ばれるYAMLライクな言語でデータを定義しダッシュボードやエクスプローラを提供しています。
Lookerの導入により、定点観測する必要のあるデータやよく閲覧される定型的なデータをダッシュボード化しすばやく確認することができるようになりました(Slackへの定時レポート配信やSalesforceへのEmbedなども活用しています)。
リソース管理の透明性を高める
厳密なデータガバナンスを実現するには、データそのものだけでなくデータ以外のリソース管理の透明性も高めることを考慮する必要があります。
マネーフォワードではTerraformを利用しており、Google Cloud Platformプロジェクトのあらゆるリソース(プロジェクトの立ち上げから、IAMやBigQueryのデータセット等々の設定)をコード化し管理しています。たとえば、新たなユーザーにデータを閲覧できる権限を付与したい場合、リソースを管理するコードを修正しGitHub上でのレビューを経てTerraformで反映します。
これにより、Google Cloud Platformプロジェクトのリソースに対して「いつ・誰が・どのような」変更を加えたかといった情報の透明性を保っています。
また、ユーザーや分析基盤のクエリ実行状況についても、監査ログのエクスポート機能やBigQueryのINFORMATION_SCHEMAを活用し監視・可視化しています。
おわりに
データドリブンなビジネスの本質は分析にあると私たちは考えています。「誰でも迅速かつシンプルにデータへアクセスし分析できる環境」を整えるためには、データの持ち方・ETL・可視化の構成をなるべくシンプルにしブラックボックスが存在しない状態を作ることが重要です。私たちはSSOTという概念を軸にシンプルな分析基盤の構築に努めています。
これから本格的にデータ分析に取り組みたい方、これまでの分析基盤を改めたいと考えている方にとって参考になれば幸いです。
【連載一覧】
この記事が気に入ったらサポートをしてみませんか?