
[PSPP/LibreOffice]多重比較

多重比較法
パラメトリック検定の分散分析や、ノンパラメトリック検定のラスカル・ウォリスのH検定やフリードマン検定といった、3群以上での差の検定では、全体としてどうかという検定は可能でも、実際にどれとどれの組み合わせに差があるのかというところまではわかりません。
では、個々の組み合わせでの差の検定は、t検定やマン-ホイットニーのU検定を行えばいいのかというと、単純に検定を繰り返しますと、第一種の過誤を冒す可能性が高くなってしまいます。たとえば、95%水準で検定を3回行うと、1-(0.95×3)=0.14、つまり14%になってしまいます。
そこで、
1.各組み合わせ間で、検定を行う。
2.過誤の可能際が高くなるので補正する。
という手順をとります。
この補正の方法には、色々あります。分散分析で一般的に用いられるのは「テューキー法」でしょう。
ここでは、「ボンフェローニ法」とその改良法である「ホルム法」を取り上げます。
検出力の点では、この2つよりも優れた方法はたくさんあります。
それでも、「ボンフェローニ法」と「ホルム法」を取り上げるのは、以下のような理由によります。
1.計算方法が簡単であること。
2.パラメトリック、ノンパラメトリックを問わない。
3.独立データでも対応のあるデータでもよい。
4.有意水準が守られていれば、2群比較の検定方法を問わない。
つまり、独立した3群以上の分散分析、対応のある3群以上の分散分析、クラスカル・ウォリスのH検定、フリードマン検定のいずれの場合でも――すなわち組み合わせ同士の検定が、独立したt検定、対応のあるt検定、マン-ホイットニーのU検定・ウィルコクソンの順位和検定、ウィルコクソンの符号順位和検定のいずれでも――用いることができます。
ボンフェローニ法
ボンフェローニ(Bonferroni)法は、極めて単純な補正法です。検定する組み合わせの総数がNの場合、各検定の有意水準をαからα/Nに変更します。逆に言えば、p値をN倍すればいいということです。
つまり、A・B・C・Dという4つの群があった場合、検定する組み合わせは、
A-B、A-C、A-D、B-C、B-D、C-D
の6つになります。よって、有意水準αからα/6に変更するか、あるいはp値を6倍します。
ただし、「第2種の過誤」=「実際には有意差があるのに有意差がないと判断してしまう誤り」を冒しやすくなるという問題点があります。したがって、p値が有意水準を超えた場合、「帰無仮説が採択される」ではなく、「帰無仮説の棄却が保留される」と考える方が妥当と言えます。
また、群の数が多くなるにしたがって有意になりにくくなる性質があるので、5つぐらいが限界とも言われます。
ホルム法
ホルム(Holm)法は、ボンフェローニ法を改良したもので、判定は少し緩くなります。ボンフェローニ法では、すべての組み合わせの検定に同一の有意水準を採用しましたが、ホルム法ではp値の大きさによって、有意水準が異なるのが特徴です。具体的な方法は以下の通りです。
1.最もp値が小さい組み合わせの有意水準をα/Nにします。
2.次にp値が小さい組み合わせの有意水準をα/(N-1)にします。
3.以下、k番目の組み合わせの有意水準をα/(N-(k-1) ) にしていきます。
p値が小さい順番に検定をしてきますから、ある順番の検定が有意でなくなれば、それ以下はすべて帰無仮説の棄却は保留されます。
当然ですが、p値の方を補正することも可能です。
1.最もp値が小さい組み合わせのp値をp×Nにします。
2.次にp値が小さい組み合わせのp値をp×(N-1)にします。
3.以下、k番目の組み合わせのp値をp×(N-k+1)にしていきます。
OpenOffic/LibreOfficeで求める。
ここでは、クラスごとのテスト得点のデータを用いて説明します。

このデータでは、群である「クラス」は互いに独立ですから、まず全体に対する検定としてクラスカル・ウォリスのH検定を、組み合わせごとの検定としてマン-ホイットニーのU検定を行います。

実際には、シンタックスで、
NPAR TEST
/K-W 得点 by クラス(1,4).
NPAR TEST
/M-W 得点 by クラス(1,2).
NPAR TEST
/M-W 得点 by クラス(1,3).
NPAR TEST
/M-W 得点 by クラス(1,4).
NPAR TEST
/M-W 得点 by クラス(2,3).
NPAR TEST
/M-W 得点 by クラス(2,4).
NPAR TEST
/M-W 得点 by クラス(3,4).
とまとめて書けばよいでしょう。
二つ目以降の「NPAR TEST」を取り、「.(ピリオド)」も最後だけを残すようにしても、同じ分析結果がでます。ただし、その場合、どの表が何の結果なのかが分かりにくくなるため、面倒でも上のように書いた方がいいでしょう。
分析の結果は以下のようになりました。
クラスカル・ウォリスのH検定の結果です。
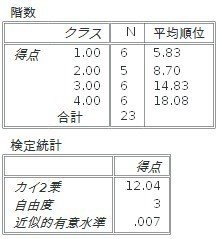
「階級」のところを見ると、クラスごとの人数(N)と平均順位が表示されています。この場合、クラスが上がるほど、平均順位が大きくなっていますから、得点は高くなっていると考えることができます。
次に、「検定統計」を見てみると、カイ2乗値が12.04、自由度が3(4群から1引いたもの)、有意水準(有意確率)が、0.007となっています。有意水準が0.05以下ですから、有意となり帰無仮説は棄却されます。つまり、この段階では、クラス間には得点差があるということになります。
マン-ホイットニーのU検定の結果を見てみましょう。




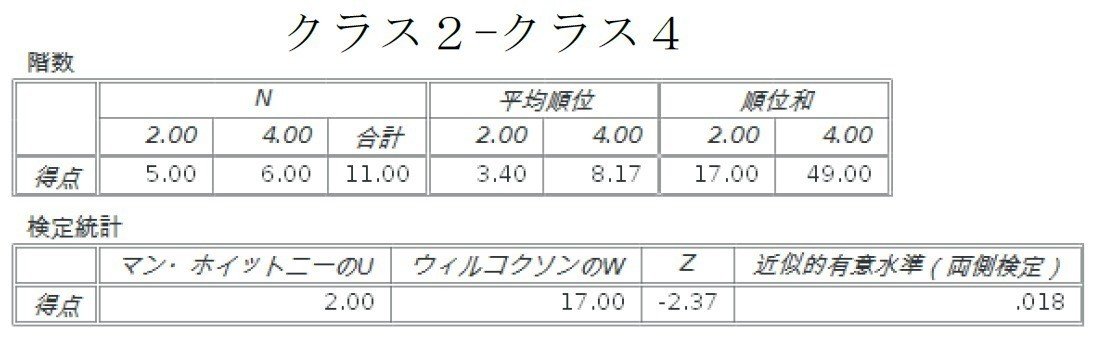

続いて、LibreOfficeでの作業に移ります。
■ボンフェローニ法
組み合わせ名とp値を順番に入力します。有意水準αも入力しておきます。ここでは5%水準で検定します。
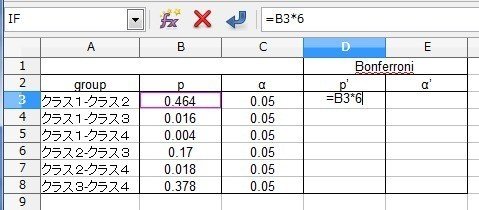
[D3]セルから[D8]セルで、ボンフェローニ法で補正したp’値を計算します。
[D3]セルに
=B3*6
と入力します。「6」は先ほど説明したように組み合わせの数です。[D4]セルから[D8]セルまではこれをコピーします。
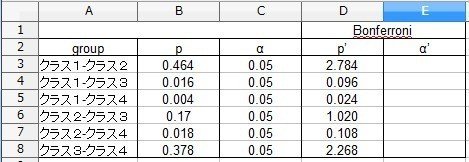
補正された値が計算されました。「クラス1-クラス4」の組み合わせが、P’=0.024となっており、0.05以下ですから有意と判断できます。
他の組み合わせは、すべて0.05よりも大きくなっていますから、有意とは言えません。
よって、「クラス1」と「クラス4」の間のみ、差が見られえると考えることができます。
次に、有意水準の方を補正してみましょう。この場合、すべての組み合わせで同じ値ですから、実際にはひとつだけ計算すれば済みます。
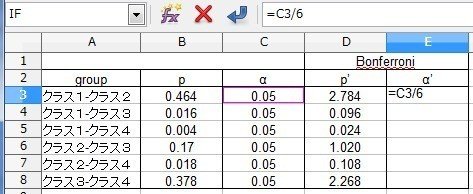
[E3]セルに、
=C3/6
と入力します。「6」は先ほど説明したように組み合わせの数です。
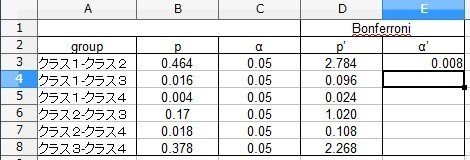
補正された有意水準α’は、「0.008」となりました。5%水準の「0.05」の代わりに、この「0.008」を基準にして判定を行います。
「クラス1-クラス4」の組み合わせが、P=0.004であり、有意水準を下回っています。
よって、帰無仮説が棄却されます。
■ホルム法
次に、ホルム法で補正値を求めてみましょう。

p値が小さい方から順位をつけるので、[F3]セルに、
=RANK(B3,$B$3:$B$8,1)
と入力し、これを[F4]セルから[F8]セルまでコピーします。
「1」から「6」まで順位がふられますので、これを使ってpとαの補正値を計算します。
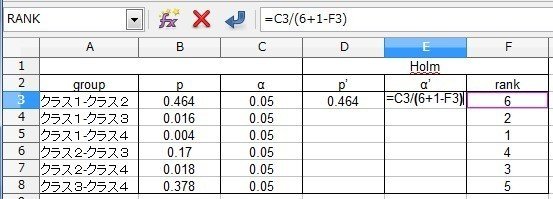
p値を補正します。
[D3]セルに、
=B3*(6+1-F3)
と入力します。これを[D4]セルからから[D8]セルまでコピーします。
同様に、αの補正は、[E3]セルに、
=C3/(6+1-F3)
と入力し、これを[E4]セルからから[E8]セルまでコピーします。
補正前のp値を用いる場合は、補正された有意水準α’と比較、補正されたp’を用いる場合は、補正前の有意水準αと比較します。
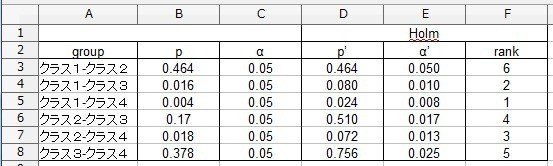
本来は、有意でなくなった時点で検定を保留しますから、実際には「rank」が「2」より大きくなる組み合わせは計算する必要がありません。
この場合でも、有意と判断できるのは「クラス1」と「クラス4」の組み合わせだけです。
※ここに挙げた、ボンフェローニ法、ホルム法、シダック法に加え、シェイファー(Shaffer)法とホランド・コペンハーヴァー(Holland-Copenhaver)法による補正ができるLibreOfficeCalcのファイルを作成しました。シェイファー法とホランド・コペンハーヴァー法で組み合わせ数の計算に簡易表を用いている都合で10群45組までしか補正できません。
この記事が気に入ったらサポートをしてみませんか?