
[RKWard]検定力分析

検定力
t検定や分散分析などの統計的検定を行う場合、設定した有意水準よりもp値が小さい場合に、データに「有意な差がある」と判断されます。しかし、p値はサンプルサイズが大きくなれば小さくなる性質のものなので、必然的にサンプルサイズが大きい場合には有意になりやすいことになります。
そのため、有意な結果を得るために大きなサンプルサイズにするという本末転倒な事態に陥ったりもします。
そのため、サンプルサイズの影響を除外して検証する方法として効果量が推奨されるようになっています。
統計的検定において結果の良し悪しを左右する要因は、「サンプル・サイズ(n)」「有意水準(α)」「効果量(es)」「検定力(power)」の4つだと言われます。
有意水準は一般に5%に設定されることが多いですが、これは単純に言えば、百回中五回は推定に誤りがあるということです。この誤りの5回の検定結果に引っかかってしまうと、実際には有意差がないのに有意差があったと判断してしまうことになります。これを「第1種の過誤」と言います。
「第1種の過誤」があるということは、当然「第2種の過誤」もあるわけで、これは実際には有意差があるのに有意差がないと判断してしまう誤りです。この誤りの確率はβで表され、β=0.20が望ましいとされます。有意水準よりも基準が緩やかなのは、「第2種の過誤」の方が「第1種の過誤」よりも罪が軽いと考えられているからです。
検定力は、1-βで定義される値で、有意差を正しく検出できる確率のことです。β=0.20が望ましいわけですから、一般的に検定力は0.80に設定されます。
検定力分析
統計的検定の結果を左右する「サンプル・サイズ(n)」「有意水準(α)」「効果量(es)」「検定力(power)」は互いに関係しているため、たとえば検定力は、
![]()
のように「サンプル・サイズ(n)」「有意水準(α)」「効果量(es)」の関数で表すことができます。これを、
![]()
とすると、サンプルサイズを示すことができます。
これによって、たとえば、分析に用いたデータの検定力を求めたり、検定力を満たすサンプルサイズを求めたりすることができます。これを検定力分析と言います。
検定力分析には、大きく分けると、結果が出てしまった検定の検定力を確認する事後分析と、データを集める前に必要なサンプルサイズを求める事前分析があります。
事後分析では、式1を用いて、αに通常は0.05、nに分析に用いたデータのサンプルサイズ、esにサンプルから求めた効果量を代入して、「効果があって実際にそれが検出できる確率」である検定力を求めることができます。
事前分析では、式2を用いて、αに通常は0.05、powerに通常は0.8を代入する。es はサンプル収集前の段階では未知ですから、研究の目安として示されている値を代入します。たとえば、t検定の場合、効果量dは効果中程度で0.5、効果大で0.8とされていますから、効果大を期待する場合は0.8を代入します。
これによって、必要な最小のサンプルサイズが計算されます。
再検査の際には、αに通常は0.05、powerに通常は0.8、サンプルから求めた効果量を代入することで、必要なサンプルサイズを計算することができます。
「G*Power」による分析
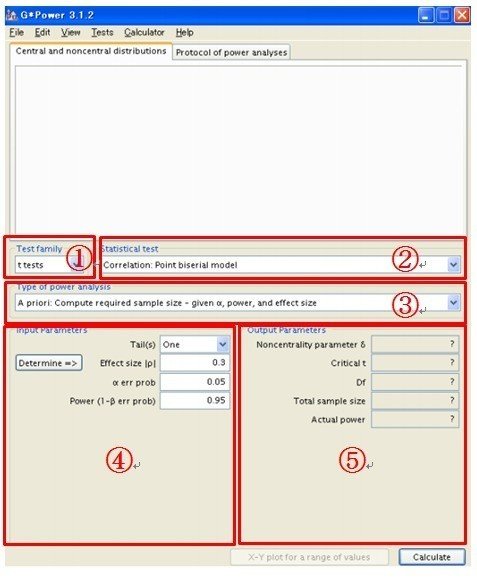
「G*Power」は、ハインリッヒ・ハイネ大学デュッセルドルフ校の実験心理学研究所が開発・公開している検定力分析ソフトです。検定力分析の定番とされており、水本・竹内(2010)や札幌学院大学の葛西俊治氏による「検定力分析ソフト G*Power について」など、使い方の解説が多く見られますので、詳細はそれらをご覧ください。ここでは、簡単にメイン画面の説明だけにとどめておきます。
①は「Test family」で、ここで検定手法を選択します。メニューは以下のようになっています。
Exact:Fisherの直接法など
F test:分散分析
t test:差のt検定
χ2 test:カイ2乗検定
Z test:ノンパラメトリック検定
②は「Statistical test」で、検定手法の詳細を選択します。
「t test」の場合、ここで
Correlation…:相関係数
Means:…(matched pairs):対応のあるt検定
Means:…(two groups):2標本t検定
Means:…(one sample case):1標本t検定
Generic t test:包括的なt検定
を選ぶことができます。
「F test」は、同様にここで一元配置分散分析(被験者間/被験者内)、二元配置分散分析(被験者間/交合計画)などを選択できます。
③は「Type of power analysis」で、求めるパラメータを指定します。
A priori:…:事前分析で必要なnの大きさを算出
Compromise:…:αとβの比を指定
Criterion:…:αを求める
Post hoc:…:事後分析で結果の検出力を算出
Sensitivity:…:事後分析で効果量を算出する
④は「Input parameters」で、③で指定した算出パラメータ以外を指定します。
Tail(s):片側検定、両側検定の指定。通常は両側検定(two)を選択
Effect size:効果量。
α err prob:有意確率。通常は0.05、または0.01で良い
Power(1-β err prob):検出力。デフォルトでは0.95だが、通常は0.8でよい
検定手法によっては、これ以外のパラメーターがある場合もあります。
「Calculate」ボタンを押すと、⑤に算出されたパラメーターが表示されます。
「RKWard」の起動と画面
「R」をエンジンにした統計ソフト「RKWard」でも、検定力分析が行えるので、ここではその方法を紹介してみたいと思います。
「RKWard」を起動すると、データセットをどうするか訊ねられるのですが、検定力分析をする場合には、データはなくてもかまわないので、データセット無しで先に進み、メニューから検定力分析を実行して問題はありません。

・[Analysis]→[Power Analysis]をクリック。
して、分析に移ることが可能です。
分析は、下のような画面で各種指定を行います。

①の「Statistical Method」で検定手法を指定します。「Select a method」が、「G*Power」の「Test family」に相当し、それ以下の部分が、「Statistical test」と「Input parameters」の一部に相当します。
選択できる検定手法は以下の通りです。
t-Test of means:t検定
Correlation test:相関分析
Anova(balanced one-way):一元配置分散分析
General liner model:一般線形モデル(回帰分析など)
Chi-squared test:カイ2乗検定
Proportion tests:比率の検定
Mean of normal distribution(known variance):母分散が既知のZ検定
また、選択した検定手法によって、入力できる項目は変化します。
Number of Group:標本(群)の数で、ANOVAのときに有効になります。
Sample:標本についてで、t-TestとProportion testsのときに有効になります。選択できるのは以下の通りです。はじめの2つは両手法に共通です。
Two samples(equal size):サンプルサイズが等しい2標本
Two samples(different size):サンプルサイズが異なる2標本
Single sample(test against constant):
基準に対する1標本(t-Testのとき)
Paired samples:対応のある標本(t-Testのとき)
One sample:1標本(Proportion testsのとき)
Using test hypothesis:仮説の指定。具体的には、検定の両側・上側・下側を指定します。Anova、General liner model、Chi-squared testでは有効ではありません。
Two-sided:両側検定
First is greater:上側片側検定
Second is greater:下側片側検定
Provided effect size:使用する効果量を指定します。ANOVAのときのみ有効になります。
Cohen's f:Cohenのf
Eta squared:イータ2乗
②の「Target measure」は算出するパラメーターの指定です。
Power of test:検定力
Sample size:サンプルサイズ
Effect size:効果量
Significance level:有意水準
Parameter count:変数の数
③の「Known measures」で、既知のパラメータを指定します。②で指定した算出パラメーターはグレーアウトしてしてできなくなります。当然ですが、①②の指定によって、パラメーターは若干ことなります。主なパラメーターは、
Power:検定力
Sample size:サンプルサイズ
Effect size:効果量
検定手法によって、どの効果量を用いるかが表示されます。Two samples(different size)のt-Testの場合はfirstとsecondを別に入力します。
Significance level:有意水準
また、General liner modelのときには、Sample sizeの代わりに、
Degrees fo freedom for numerator:分子の自由度(df1)
Degrees fo freedom for denominator:分母の自由度(df2)
となり、Chi-squared testのときには、Sample sizeの下に、
Degrees fo freedom:自由度(df)
が追加されます。
指定し終えて、「Submit」ボタンを押せば、結果が出力されます。
一番下の「Code Preview」は、Rスクリプトが表示されているので、「R」を使い慣れている人以外は気にする必要はありません。「Code Preview」の右の「×」をクリックするか、チェックボックス「Code Preview」のチェックをはずして、閉じておいてもかまいません。
チェックボックス「Preview」にチェックを入れると、「Submit」ボタンを押さなくても、右にプレビューが開いて、結果を確認することができます。
なお、「RKWard」は、検定力分析にRのpwrパッケージを使っているのですが、二元配置分散分析の検定力分析はできません。分析できる検定手法の幅広さでは、さすがに専用ソフト「G*Power」の方が優れています。
以下、具体例を紹介しますが、事前分析と事後分析では、事前分析の方がより重要なので、事前分析だけをを取り上げることとします。
「RKWard」のによる分析①~t検定の事前分析
たとえば、独立した2標本(群)のt検定で、各標本(群)のサンプルサイズが等しい場合に、必要なサンプルサイズを求めてみましょう。
まず、「Statistical Method」で、「サンプルサイズが等しい独立した2標本(群)のt検定」で「両側検定」を設定します。

・[Select a method]で[t-Test of means]を選択。
・[Sample]で[Two samples(equal sizes)]を選択。
・[Using test hypothesis]で[Two-sided]を選択。
次に、事前分析でサンプルサイズを求めるので、「Target measure」で算出するパラメーターを「サンプルサイズ」に設定します。

・[Parameter to determine]で[Sample size]を選択。
最後に、「Known measures」で、既知のパラメーターを設定します。この場合は事前分析ですから、既知とはいってもあらかじめ分かっているデータは存在しないので、どの程度を期待するかという問題になります。

・[Power]を「0.8」に設定。通常は「0.8」でかまいませんが、「G*Power」のように、「0.95」などでももちろん問題ありません。
・[Sample size]は算出するパラメーターなので、グレーアウトしてしてできなくなっています。
・[Effect size]を「0.5」に設定。これは中程度の設定ですから、より厳密な分析を期待する場合は「0.8」にしてもかまいません。目安が分からない場合、部レヴューを表示する設定にしておくと、結果とともに効果量の目安が表示されるので、それを参考にして設定しなおせば大丈夫です。
・[Significance level]を「0.05」に設定。有意水準は通常「0.05」を用いますが、「0.01」などの依り厳しい基準でも、もちろんかまいません。
「Submit」ボタンを押すと、結果が表示されます。基本的にプレビューと同じものです。

最初の表に、nの値が「63.76561」と表示されていますから、必要なサンプルサイズは64ということになりますが、「Note:n is number in *each* group」とあることに注意してください。このnは標本(群)あたりのサンプルサイズなので、2標本(群)で合計128が必要な全体のサンプルサイズとなります。
一番下は、先ほども触れた効果量の目安です。
「RKWard」のによる分析②~一元配置分散分析の事前分析
たとえば、3標本(群)の一元配置分散分析で、必要な各標本のサンプルサイズを求めてみます。
まず、「Statistical Method」で、「サンプルサイズが等しい独立した3標本(群)の一元配置分散分析」を設定します。

・[Select a method]で[ANOVA(balance one-way)]を選択。
・[Number of groups]に「3」と入力。
・[Provided effect size]で[Cohen’s f]を選択。これは好みの問題なので、[Eta squared]つまりイータ2乗るでも問題はありません。
次に、事前分析でサンプルサイズを求めるので、「Target measure」で算出するパラメーターを「サンプルサイズ」に設定します。

・[Parameter to determine]で[Sample size]を選択。
最後に、「Known measures」で、既知のパラメーターを設定します。

・[Power]を「0.8」に設定。これはt検定の場合と同様です。
・[Sample size]は算出するパラメーターなので、グレーアウトしてしてできなくなっています。
・[Effect size]を「0.25」に設定。これは中程度の設定ですから、より厳密な分析を期待する場合は効果大の「0.4」にしてもかまいません。目安が表示されるのはt検定の場合と同じですが、「Cohen’s F」のみで、「Eta squared(イータ2乗)」の目安は表示されません(イータ2乗の場合、中程度は0.06、大は0.14となります)。
・[Significance level]を「0.05」に設定。これもt検定と同様です。
「Submit」ボタンを押すと、結果が表示されます。基本的にプレビューと同じものです。
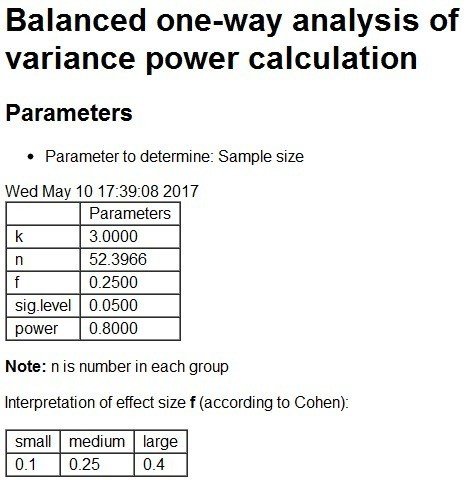
最初の表に、nの値が「52.3966」と表示されていますから、必要なサンプルサイズは53ということになりますが、t検定同様、「Note:n is number in *each* group」とあることに注意してください。このnは標本(群)あたりのサンプルサイズなので、3標本(群)で合計159が必要な全体のサンプルサイズとなります。
ちなみに、効果量をイータ2乗=0.06で分析した場合、サンプルサイズnは「51.3263507」となり、微妙に異なった結果となります。
「RKWard」のによる分析③~カイ2乗検定の事後分析
ある質問を男女それぞれ20名に対して行った結果、男性では7名が賛成、13名が反対だった。一方、女性では10名が賛成であった。

このデータについてカイ2乗検定を行ったところ、効果量は0.15だった。
まず、「Statistical Method」で、カイ2乗検定に設定します。

・[Select a method]→[Chi-squared test]を選択。
カイ2乗検定では、「Statistical Method」で選択できるのは、ここだけです。
次に、事後分析で検定力を求めるので、「Target measure」で算出するパラメーターを「検定力」に設定します。

・[Parameter to determine]で[Power of test]を選択。
最後に、「Known measures」で、既知のパラメーターを設定します。

・[Degrees of freedom]を「1」に設定。2×2のクロス表になりますから、(2-1)×(2-1)=1で自由度は1となります。
・[Sample size]に「40」と入力。ここは標本(群)ごとではなく、合計ですから「40」になります。
・[Effect size]に「0.15」と入力。「Cohen’s w」が指定されていますが、基本的にはφ=クラメールのV=Cohenのwですから、先の分析結果をそのまま入力します。
・[Significance level]を「0.05」に設定。これもt検定と同様です。
「Submit」ボタンを押すと、結果が表示されます。基本的にプレビューと同じものです。

上から、既知の数値である効果量(w)、サンプルサイズ(N)、自由度(df)、有意水準(sig.level)が並び、最後に検定力(power)が示されています。
このデータの場合、検定力は0.158ですから、「第二の過誤」を犯さない確率が16%ほどということですから、かなり低いということができます。
では、再検査にはどの程度のサンプルサイズがあれば良いのかというと、
「Known measures」で、[power]を「0.80」に、[Effect size]を検定結果の「0.15」にして、[Sample size]を算出すればいいわけです。
この場合、効果量が小さいので、サンプルサイズは合計でN=348.8382、つまり349名の被験者が必要ということになります。
この記事が気に入ったらサポートをしてみませんか?