
デュエル・マスターズのカードリストをスクレイピングしてデータベース化する

2002/5に登場した「デュエル・マスターズ」は発売から今年で20周年になりました。20周年記念で先日、「デュエル・マスターズ超全集 20thパーフェクトBOX」という1000ページ近くもある本(ZOID付き)が限定8000部で小学館より発売されました。
また9/4から新番組「デュエル・マスターズ WIN」が放送開始、先週末にはアニメ内で使っているスタートデッキも発売など、少し盛り上がりを見せています。
発売20年にもなりますとカードの枚数も凄まじいことになっており、2022/9/17時点でパーフェクトボックスの大きさも納得の15140枚になるそうです(再販による重複を含みます)。このタカラトミーのページで全てのカードテキストと画像を見ることができます。
こちらのページではカード画像とテキストを公開しています。しかしこれだけの枚数になりますとwebで観るのも操作が増えますので、webページの内容をスクレイピングしてデータベースにまとめるプログラムをPythonで書きたいと思います。
なおタカラトミーのサイトポリシーにはこのように記載があります。
著作権について
当社ウェブサイトにある文章・画像・動画・ゲーム・商標・肖像等、(以下、「ウェブデータ」)に関する著作権とその他の権利は、当社または原著作者、その他の権利者のものです。企業等が非営利目的で使用する場合、個人的な使用を目的とする場合、その他著作権法により認められている場合を除き、ウェブデータは当社、原著作者、その他の権利者の許諾なく使用することは出来ません。
非営利、個人で楽しむ範囲であれば使用できるということで今回紹介させていただきました。他のトレーディングカードゲームで同様のことを行う際には個別にサイトポリシーがありますので、お読みになったうえで実施ください。
1. システム内容
webブラウザはGoogle Chromeを使います。このGoogle Chromeはchromedriverを追加することにより、プログラムからGoogle Chromeを操作できます。プログラム言語にはPythonを使い、chromedriverを通じて「カード画像」と「カードテキスト」のURLを入手します。入手した「カードテキスト」の内容をデータベースに書き込みます。
これらを満たすためにはパソコンに以下のソフトが必要となります。
Google Chrome
chromedriver
Python実行環境
DB Browser(SQLite)
プログラム・エディター
1-1. Google Chrome
Googleが提供するwebブラウザです。今回はこちらをプログラムで操作します。
1-2. chromedriver
Google Chromeをプログラムから操作するために必要なソフトウェアです。2022/9/17の段階ではバージョン104, 105, 106用のソフトウェアが提供されていますのでご自身のGoogle Chromeのバージョンを確認します。
Google ChromeのバージョンはGoogle Chromeを開いて「Google Chromeについて」を選択すると確認できます。バージョンを確認しましたら対応するバージョンのchromedriverをダウンロードしてください。Windows版は「chromedriver_win32.zip」です。ファイルを解凍すると「chromedriver.exe」というファイルがありますので適当な場所にコピーします。

1-3. Python実行環境
Python言語で書かれたプログラムを動作するときに必要な環境です。
2022/9/17時点の最新版はv3.10.7です。自身はPython v3.9.8を使っています。
ダウンロードしたインストーラーをダブルクリックしてInstall Nowを押せば良いのですが、以下の部分だけチェックを入れて環境変数PATHを自動登録しておきます。
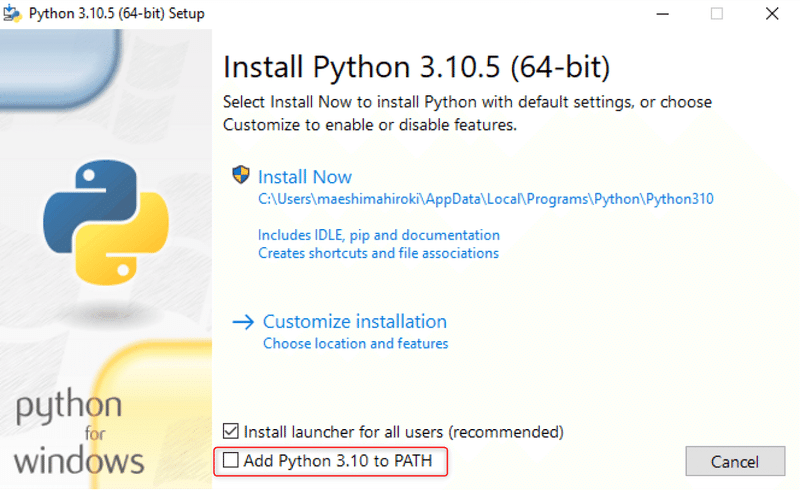
今回のプログラムでは以下のPythonライブラリーを追加で導入します。Python実行環境をインストールした後にコマンドプロンプトかWindows Power Shellから以下のコマンドを順番に実行してください。
pip install requests
pip install beautifulsoup4
pip install selenium
pip install chromedriver-binary1-4. DB Browser SQlite
データベースの設定、書き込んだ内容の確認に使います。今回はDB Browser for SQliteというアプリケーションでDuelmasters.db というデータベースを作成します。
設定するフィールドは以下の13個です。データ型はすべて文字列(Text)にしています。
cardname
packname
picturl
typetxt
civiltxt
raretxt
powertxt
costtxt
manatxt
racetxt
illusttxt
abilitytxt
flavortxt
こちらの内容を設定しました空のデータベースファイルは以下からダウンロードできます。
1-5. プログラム・エディター
プログラムの記述はメモ帳で行えますが、動作確認することを考えますとプログラム・エディターを使用した方が良いと思います。PythonであればPyScripter / Visual Studio / Visual Studio Code / Atomがあります。自身は使い慣れているPyScripterを使っています。
2. プログラムの動作概要
プログラムを作成する前に処理をまとめていきたいと思います。
カード検索を表示しますとカード画像が1ページにつき50枚表示されます。またカード画像をクリックしますと、カードテキストとカード画像が表示されます。(一部カード画像はクリック先で表示されません)
以上のことからカード検索を表示して、カード画像のリンク先の内容をデータベースに書き込んでいきたいと思います。
3. プログラムの処理
ここからは動作概要をプログラムに落としていきたいと思います。
3-1. カード検索のURLを解析する
カード検索がどのようになっているか確認したいと思います。実際に検索条件を変えずにwebブラウザで2ページ、3ページに切り替えてURLを確認してください。すると違いはURL内の「%22pagenum%22:%222%22」と「%22pagenum%22:%223%22」の太線部分の数字だと分かります。%22はASCIIコードで「"」を示しているため、上のURLであれば「"pagenum":"2"」、「"pagenum":"3"」を意味しています。つまり、こちらの数字を入れ替えたURLを作成すれば直接指定したページを表示できます。
そこで、値のみ変更したい部分を「{ }」とし、format関数に値(ここではi+1)を代入するループを書き、アクセスしたいカード検索のURLをリスト化します。これを実現するコードは以下の通りです。
この処理ですと、最初の「{ }」には1(0+1)が入ります。これを5回(range(5))繰り返すので最終的には1ページから5ページまでのURLがリスト変数urlに格納されます。
url = ['https://dm.takaratomy.co.jp/card/<省略>%22pagenum%22:%22{}%22<省略>'.format(i+1) for i in range(5)]3-2. カード検索のページ数だけ処理を繰り返す
上の処理でurlというリスト変数を作成しましたら、リスト変数に作成したURLの数だけページを見ていきます。以下のように「len(url)」とすればページ数だけ処理を繰り返すことができます。
for i in range (len(url)):3-3. Google Chromeとデータベースの開始と終了
カード検索ページにアクセスするためchromedriver.exeにアクセスします。こちらは配置したフォルダパスに書き換えます(driver_path = r"C:\***\chromedriver.exe")。カード検索のページをすべて解析し終わったら、Google Chromeを終了します。
データベースも同様にデータベースをカード検索ページを表示する前に開始し、カード検索ページの内容をデータベースに更新していきます。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
import time
import sqlite3
for i in range (len(url)):
# データベースを開く
conn = sqlite3.connect('Duelmasters.db')
# chromedriverからGoogle Chromeを起動する
# driver_pathにはchromedriver.exeを置いたパスを指定する
driver_path = r'C:\***\chromedriver.exe'
service = Service(executable_path=driver_path)
driver = webdriver.Chrome(service=service)
time.sleep(3)
# データベースを更新/終了する
conn.commit()
conn.close()
# chromedriverからGoogle Chromeを終了する
driver.close()3-4. chromedriverでカード検索ページを表示する
Google Chromeが立ち上がったあとに「driver.get()」命令でカッコ内に表示したいURLを指定しますとページが表示されます。今回は(1)でカード検索のURLをリスト変数urlに保存しましたので、こちらを使います。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
import time
# 指定ページのカード検索を表示する
driver.get(url[i])
time.sleep(3)
3-5. Google Chromeで表示したカード検索からカードテキストのURLを抜き出す
Google Chromeに表示された内容をBeautifulsoupというPythonライブラリーを使ってHTML情報で読み込みます。読み込んだHTMLファイルの中から抜き出したいHTMLタグを指定して、カードテキストのURLを抜き出します。対象のタグはGoogle Chromeで対象URLを表示して、このページをデベロッパーツールでHTMLを見ると特定しやすいと思います。今回はcardImageクラスをすべて抜き出します。

from bs4 import BeautifulSoup
# カード説明URLを得る
soup = BeautifulSoup(driver.page_source, 'html.parser')
cardlink = soup.find_all(class_='cardImage')3-6. Google Chromeにカードテキストを表示する
Beatifulsoupで抜き出したカードテキストの文字列はHTML形式のため、attrsライブラリーでテキストに変換します。変換したテキストにURLを加えててGoogle Chromeに表示します。このとき、あまり頻度高くページを表示しますとアクセス先のサーバーに負荷を掛けるため、「time.sleep(3)」で例えば3秒程度の間隔を空けてアクセスするようにします。
アクセスしたカードテキストのページのHTMLを再びBeatifulsoupで取得します。ここでは「ツインパクトカード」のように複数のカードテキストがカード1枚に含まれるケースを考慮できるようにします。
from bs4 import BeautifulSoup
import time
import re
detail_info = ('https://dm.takaratomy.co.jp'+ cardlink[i].attrs['data-href'])
driver.get(detail_info)
time.sleep(3)
soup = BeautifulSoup(driver.page_source, 'html.parser')
elems = soup.find_all('table')
cards = elems[0].find_all(src=re.compile('/wp-content/card'))3-7. 表示したカードテキストからデータベースに書き込む情報とカード画像のURLを抜き出す
カードテキストのHTMLを見ますと、表(table)で管理されており、ヘッダー(th)にカード名や項目名がリストで、データ(td)に各項目のデータがリストで入っていますので、これを抜き出します。またspanの中には商品のナンバリングされた型番が入っていますので、これもデータベースに書き込みます。
from bs4 import BeautifulSoup
elems_head = elems[i].find_all('th')
elems_packname = elems[i].find_all('span')
elems_data = elems[i].find_all('td')3-8. カードテキストの情報をデータベース書き込む
データベースにはあらかじめ以下のフィールドをDB Browser SQliteで設定します。カード名はthタグにあり、残りはtdタグにデータがあります。これをSQL文でデータベースに書き込みます。「ツインパクトカード」のように複数効果があるものは2番目以降のデータにはイラストレーターの欄がないので、これを考慮します。
cardname(カード名)
packname(商品ナンバリング)
picturl(カード画像URL)
typetxt(カードの種類)
civiltxt(文明)
raretxt(レアリティ)
powertxt(パワー)
costtxt(コスト)
manatxt(マナ)
racetxt(種族)
illusttxt(イラストレーター)
abilitytxt(特殊能力)
flavortxt(フレーバー)
またデータベースに重複したデータを書き込まないよう、データ追加前に既にカードが登録されていないか確認します。具体的にはカード名とカード種類が同じものがデータベースに登録されているか確認します。
import sqlite3
cur = conn.cursor()
# 既にデータベース登録済みのカード名はデータベースに登録しない
duplicate = cur.execute('select * from cardlist \
where cardname like ? \
AND typetxt like ?',
('%'+elems_head[0].text+'%','%'+elems_data[1].text+'%'))
# データベースにないカードのみ、データベースに登録し、画像を保存する
if duplicate.fetchone() is None:
sql = 'insert into cardlist (cardname, packname, picturl, typetxt, civiltxt,\
raretxt, powertxt, costtxt, manatxt, racetxt,\
illusttxt, abilitytxt, flavortxt)\
values (?,?,?,?,?,?,?,?,?,?,?,?,?)'
if len(elems_data) == 11:
data = (elems_head[0].text,
elems_packname[0].text,
picturl,
elems_data[1].text,
elems_data[2].text,
elems_data[3].text,
elems_data[4].text,
elems_data[5].text,
elems_data[6].text,
elems_data[7].text,
elems_data[8].text,
elems_data[9].text,
elems_data[10].text)
else:
data = (elems_head[0].text,
elems_packname[0].text,
picturl,
elems_data[1].text,
elems_data[2].text,
elems_data[3].text,
elems_data[4].text,
elems_data[5].text,
elems_data[6].text,
elems_data[7].text,
"-",
elems_data[8].text,
elems_data[9].text)
cur.execute(sql, data)
3-9. カード画像をPythonプログラムと同じパスに保存する
カードテキストに表示されているカード画像をパソコンに保存します。「os.path.basename」を実行することでURLからファイル名のみ取り出すことができますので、これを保存するファイル名とします。なお数枚ですが、プロモーションカードの一部にカードテキスト内にカード画像が表示されないものがあります。
import os
import requests
picturl = ('https://dm.takaratomy.co.jp' + cards[i].attrs['src'])
# 対象画像を保存する
filename = os.path.basename(picturl)
response = requests.get(picturl)
image = response.content
with open(filename, 'wb') as cardpict:
cardpict.write(image)4. 完成したPythonコード
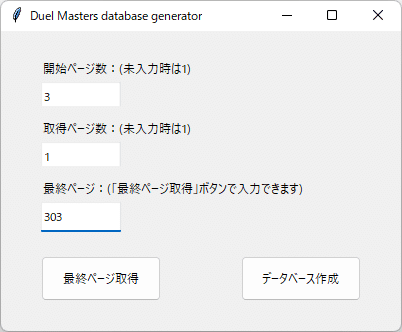
上の処理を組み合わせて、ループ処理を入れ、簡易的なGUIをtkinterで作成したのが以下のコードです。一通りの動きは確認できましたので紹介させていただきます。
使い方は開始ページにデータベース化したい開始ページ、取得ページは開始ページから何ページ分データベース化したいか指定します。最終ページは手打ち入力するか、「最終ページ取得」ボタンを押して自動入力します。
コードは以下の1点を変更してください。
「driver_path = r'C:\***\chromedriver.exe'」はchromedriver.exeを配置しているフォルダパスを指定してください。2ヶ所あります。
import os
import tkinter as tk
from tkinter import ttk
from tkinter import messagebox
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
import re
import time
import requests
import sqlite3
def update_database(conn, elems_head, elems_packname, elems_data, picturl):
cur = conn.cursor()
# 既にデータベース登録済みのカード名はデータベースに登録しない
duplicate = cur.execute('select * from cardlist\
where cardname like ?\
AND typetxt like ?',
('%'+elems_head[0].text+'%','%'+elems_data[1].text+'%'))
# データベースにないカードのみ、データベースに登録し、画像を保存する
if duplicate.fetchone() is None:
sql = 'insert into cardlist (cardname, packname, picturl, typetxt, \
civiltxt, raretxt, powertxt, costtxt, manatxt, racetxt, illusttxt, \
abilitytxt, flavortxt) \
values(?,?,?,?,?,?,?,?,?,?,?,?,?)'
if len(elems_data) == 11:
data = (elems_head[0].text,
elems_packname[0].text,
picturl,
elems_data[1].text,
elems_data[2].text,
elems_data[3].text,
elems_data[4].text,
elems_data[5].text,
elems_data[6].text,
elems_data[7].text,
elems_data[8].text,
elems_data[9].text,
elems_data[10].text)
else:
data = (elems_head[0].text,
elems_packname[0].text,
picturl,
elems_data[1].text,
elems_data[2].text,
elems_data[3].text,
elems_data[4].text,
elems_data[5].text,
elems_data[6].text,
elems_data[7].text,
"-",
elems_data[8].text,
elems_data[9].text)
cur.execute(sql, data)
conn.commit()
# カード画像をpythonファイルと同じパスに保存する
filename = os.path.basename(picturl)
response = requests.get(picturl)
image = response.content
with open(filename, "wb") as cardpict:
cardpict.write(image)
def find_card_information(conn,driver,cardlink,listcards):
for i in range(len(cardlink)):
if len(cardlink) != 0:
detail_info = ('https://dm.takaratomy.co.jp'+ cardlink[i].attrs['data-href'])
driver.get(detail_info)
time.sleep(3)
soup = BeautifulSoup(driver.page_source, 'html.parser')
elems = soup.find_all('table')
cards = elems[0].find_all(src=re.compile('/wp-content/card'))
# カードテキスト内のループ(ツインパクトカードなど)
for j in range (len(elems)):
elems_head = elems[j].find_all('th')
elems_packname = elems[j].find_all('span')
elems_data = elems[j].find_all('td')
# カードテキストに画像が存在しない場合はカード一覧から参照する
if not cards:
picturl = ('https://dm.takaratomy.co.jp' + listcards[i].attrs['src'])
else:
picturl = ('https://dm.takaratomy.co.jp' + cards[0].attrs['src'])
# カードテキスト内に複数の画像が存在する
if len(elems) == len(cards):
picturl = ('https://dm.takaratomy.co.jp' + cards[j].attrs['src'])
update_database(conn, elems_head, elems_packname, elems_data, picturl)
def btn_click_lastpage():
# 最終ページを確認する
# chromedriverからGoogle Chromeを起動する
driver_path = r'C:\***\chromedriver.exe'
service = Service(executable_path=driver_path)
driver = webdriver.Chrome(service=service)
time.sleep(3)
url = 'https://dm.takaratomy.co.jp/card/'
driver.get(url)
soup = BeautifulSoup(driver.page_source, 'html.parser')
lastpagebtn = soup.find_all(class_='nextpostslink')
lastpage = lastpagebtn[0].attrs['data-page']
time.sleep(3)
driver.close()
lastpage_data.delete(0, tk.END)
lastpage_data.insert(tk.END,lastpage)
def btn_click_generate():
startpage = startpage_data.get()
tgtpage = tgtpage_data.get()
lastpage = lastpage_data.get()
if startpage == '':
startpage = '1'
if tgtpage == '':
tgtpage = '1'
if lastpage == '':
lastpage = '303'
if (int(startpage) + int(tgtpage)) >= int(lastpage):
messagebox.showerror('ページ数指定エラー', '最終ページは' + lastpage +
'です。開始ページと取得ページ数を見直してください。')
else:
# カード一覧の全URLを作成する
url = ['https://dm.takaratomy.co.jp/card/?v=%7B%22suggest%22:%22on%22,\
%22keyword_type%22:%5B%22card_name%22,%22card_ruby%22,\
%22card_text%22%5D,%22culture_cond%22:%5B%22%E5%8D%98%E8%89%B2%22,\
%22%E5%A4%9A%E8%89%B2%22%5D,%22pagenum%22:%22{}%22,\
%22samename%22:%22show%22,%22sort%22:%22release_new%22%7D'
.format(i + int(startpage)) for i in range(int(tgtpage))]
# カード一覧のページ数のループ
for i in range (len(url)):
conn = sqlite3.connect('Duelmasters.db')
# chromedriverからGoogle Chromeを起動する
driver_path = r"C:\***\chromedriver.exe"
service = Service(executable_path=driver_path)
driver = webdriver.Chrome(service=service)
time.sleep(3)
# 指定ページのカード一覧を表示する
driver.get(url[i])
time.sleep(3)
# カード説明URLを得る
soup = BeautifulSoup(driver.page_source, 'html.parser')
cardlink = soup.find_all(class_='cardImage')
listcards = soup.find_all(src=re.compile('/wp-content/card'))
# カード一覧内のカード枚数のループ
find_card_information(conn,driver,cardlink,listcards)
conn.close()
driver.close()
root = tk.Tk()
root.geometry('400x300')
root.title('Duel Masters database generator')
# 開始ページ数ラベル
startpage_lbl = ttk.Label(root, text='開始ページ数:(未入力時は1)',
width='', state='normal')
startpage_lbl.place(relx=0.1, rely=0.05, relheight=0.15, relwidth=0.8)
# 開始ページ数テキスト
startpage_data = ttk.Entry(width=20)
startpage_data.place(relx=0.1, rely=0.17, relheight=0.1, relwidth=0.2)
# 取得ページ数ラベル
tgtpage_lbl = ttk.Label(root, text='取得ページ数:(未入力時は1)',
width='', state='normal')
tgtpage_lbl.place(relx=0.1, rely=0.25, relheight=0.15, relwidth=0.8)
# 取得ページ数テキスト
tgtpage_data = ttk.Entry(width=20)
tgtpage_data.place(relx=0.1, rely=0.37, relheight=0.1, relwidth=0.2)
# 最終ページ数ラベル
lastpage_lbl = ttk.Label(root, text='最終ページ:(「最終ページ取得」ボタンで入力できます)',
width='',state='normal')
lastpage_lbl.place(relx=0.1, rely=0.45, relheight=0.15, relwidth=0.8)
# 最終ページ数テキスト
lastpage_data = ttk.Entry(width=20)
lastpage_data.place(relx=0.1, rely=0.57, relheight=0.1, relwidth=0.2)
# 最終ページ取得ボタン
btn_gen = ttk.Button(root, text='最終ページ取得',
command=btn_click_lastpage)
btn_gen.place(relx=0.1, rely=0.75, relheight=0.15, relwidth=0.3)
# データベース作成ボタン
btn_gen = ttk.Button(root, text='データベース作成',
command=btn_click_generate)
btn_gen.place(relx=0.6, rely=0.75, relheight=0.15, relwidth=0.3)
root.mainloop()
この記事が気に入ったらサポートをしてみませんか?