
【非エンジニア向け】Amazonの新着本の各種データを収集してSpread Sheetに書き込み自動化

今回紹介するPythonプログラムを扱えるようになれば、Amazonから提供されているデータの範囲でなら大抵のことができるようになります👏
とくに普段Amazonを使ってせどりをしたり、新着の商品をチェックして紹介しているブロガーの方は、Amazonの商品データ取得と管理を自動運用できるようになれば、売り上げ増も目指せると思うので、オススメです。
****** 注意 ******
この記事は公開後1日間は無料で、その後有料記事となります。
他のプログラミングチュートリアル記事も公開後1日間は無料になるので、無料で読みたい方は、noteのフォローをオススメします( ・v・)b
フォローはこちらから → https://note.mu/virtual_surfer
# 1. はじめに
こんにちは。仮想サーファー(@virtual_techX)です!
プログラミングチュートリアル記事を半年近く書けていませんでしたが、手が空いてきたので、記事の更新を再開します。
今回は、「【非エンジニア向け】Amazonの新着本の各種データを収集してSpread Sheetに書き込み自動化」という記事です!
それでは最初に、今回のチュートリアルでできるようになることを簡単にまとめておきますね。
できるようになることは?
このチュートリアルを終え、最終的にできるもののイメージがコチラ。

「Python プログラミング」に関連する本をAmazonのデータを収集してSpread Sheetに自動更新させています。
(上の画像をクリックするとSpread Sheetに飛びます。)
検索するキーワードを変えれば、Amazon上のどんなデータでも自動Spread Sheet集計できるようになります( ´ v ` )b
以下、今回のチュートリアルでできるようになることです。
・Amazonの商品データをプログラム(API)で取得する
・Amazonの人気ランキング、価格などのデータを(API)で取得する
・プログラムでSpread Sheetに書き込みする
・Amazonのデータを定期的にSpread Sheetに書き込む処理を自動化するプログラムをHerokuにデプロイする
「Amazonのデータを自動で集計したい!」となったときにめちゃくちゃ重宝するプログラムを紹介します( ・v・)/
どんな人に読んでもらいたい?
こちらのnoteは、プログラミングほとんどやったことないけど、Amazonのデータ収集を自動化・効率化したい!という方向けのコンテンツになっています。
・エンジニアじゃないけど、Amazonのデータ収集を効率化したい。
・プログラミングは少しProgateやコードをコピペして動かしたことあるくらいだけど、実践的な・日常で使えるプログラムを書いてみたい。
上のいずれかに該当する方に読んでもらいたいと思っています!
「プログラミングは絶対にやりたくない!」という方や、「Amazonのデータなんて興味ない!」という方は、このチュートリアルを読み進めても無駄になってしまうので、これ以上読み進めない方がいいです。
このチュートリアルで具体的に何が学べるの?
この記事では、AmazonでPython本のデータを検索してSpread Sheetに毎日自動追加していってくれるプログラムを実装します。
上のリンクのSpread Sheetがアウトプットイメージです。
このチュートリアルを通して学べるプログラミング技術は以下のものです。
① Pythonの基本的なプログラミング
② Amazon Product Advertising APIへのアクセス・操作(Amazonの商品データの取得)
③ Amazonの商品のデータを自分の望むようにSpread Sheetに集計するプログラムを組む
④ Herokuへアプリケーションのデプロイ(自動で③が動くようにする)
チュートリアルの最後④まで進めることで、Amazonの欲しいデータを収集するのを完全自動で定期的に動くよう設定することができます。
④までは、プログラミング経験があまりない方だと4~5時間程度、プログラミング経験がある方だと1~2時間程度で進められる想定です。
読む前に必要な準備はある?
・MacのPC
・インターネットに接続できる環境(このnoteが普通に読めていればOK)
・Amazonのアカウント
・個人で運営しているブログやnoteやWebサービス
上に書いているもの以外、事前の準備は必要ありません。
すべてチュートリアル内の情報だけで完結できるように設計しています。
このチュートリアルではAmazon Product Advertising APIというAmazonのAPIサービス(Amazonのデータ活用などをすることができるサービス)を利用するのですが、そのサービスの利用登録の際に、個人で運営しているブログやnoteやWebサービスが必要となります。
ちなみに、プログラミングの知識が少しでもあると読み進めていく中で理解が早いと思うので、ProgateのGit、Command Line、Pythonの内容を軽くやってみると良いです。

(画像:Progateのコース選択画面)
何の役に立つの?
Amazonの商品データ収集を自動化したい時に活用できます。
以下、今回のチュートリアルをすることでできるようになることの例。
・Amazonのデータ収集を自動化して、自分の買いたい商品が値下げされたらLINEに通知してくれるプログラムを作成する。
・Amazonの人気商品のオススメツイートを自動でしてくれるTwitter Botを開発する。
・ブログで紹介する新着本の候補リストを自動でSpread Sheetに出力し続けるプログラムを作成する。
...などなど。
今回のチュートリアルをやり終えることで、上にあげたもの以外でもAmazonのデータを使ったWeb上での作業を効率化することができるので、発想次第でできることはかなり増えます。
# 2. チュートリアル実践
それでは、チュートリアルに入っていきます!
Pythonの実行環境の準備
今回はPythonというプログラミング言語でプログラミングをしていくので、まずは、Pythonを実行することができる環境を準備していきます。
****** 注意 ******
すでにPythonを実行できる環境がある方は、「Amazonの商品データにアクセスできるようになる」の箇所まで読み飛ばしてください。
①Terminalの用意
Finder > Applications > Terminalと遷移し、Macに標準で搭載されているアプリケーションTerminalを開きます。
Terminalって何?という方は、命令文を打ち込むことでパソコンを操作できる便利ツールだと捉えるとよいです。
上の画像のように黒い画面(Terminal)に命令文を打ち込んでいくことで、プログラムやPCに操作をさせることができます。
試しに、$マークの後ろに「$ echo Pythonのチュートリアルなう!」と打ち込んで、(Enterボタンを押して)命令文を実行してみてください。

「Pythonのチュートリアルなう!」という文章が表示されたはずです。「echo」という命令文は、「その後に続く文章をTerminalに表示する」という命令文を意味するので、このように文章を表示することができました。
②Homebrewのインストール
Terminalを使う準備ができたら、次にPythonを使用できるように準備していきましょう。まずは、PythonをTerminalで簡単にインストールできるように、Homebrewというものをインストールします。
先ほどと同じように、Terminalの$マーク以降の場所に次の命令文を入力します。「$ /usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"」

「Press RETURN to continue or any other key to abort」と表示されたら、Enterボタンを押してください。また、「Password:」と表示されたら、いつもパソコンにログインする時に使っているパスワードを入力してください。
これによって、Homebrewがインストールされます。
Homebrewのインストールが成功したかどうかは、「$ brew -v」というHomebrewのバージョンを確認する命令文を打ち込むことで確認できます。
試しに「$ brew -v」と打ち込んでみましょう。

上の画像のように、「$ brew -v」と打ち込んで、「Homebrew 1.7.6」のようにバージョン番号が表示されればインストール成功しています(バージョン番号は異なる場合があります)。
③Pythonのインストール
最後に、Pythonを使えるようにインストールしていきます。
pythonのバージョンは、3のもの(2018年10月現在で最新版)をインストールします。
これまでと同じように、「$ brew install python3」と打ち込みます。

ぼくはすでにPythonをインストールしているのでErrorとなっていますが、初めてPythonを利用する場合はインストールが成功したような表示がされるはずです。
これで自分のPC環境にPythonがインストールされたはずです。 このPythonを簡単に使えるようにするため、パスの設定をしておきましょう。
Terminalに「$ open ~/.bash_profile」と打ち込みます。
上記の命令文を打ち込むと、「.bash_profile」という名前のファイルが開かれます。

開いたファイルに、「export PATH=/usr/local/bin:$PATH」という文章をコピペして、ファイルの変更を保存します(「command」ボタンと「S」ボタン同時押しで保存するショートカットおすすめです)。
「command + S」は、Macでファイルの保存をしたい時によく使うショットカットキーです。
ファイルの保存ができたら、ファイルを閉じ、再びTerminalに戻り「$ source ~/.bash_profile」という命令文を打ち込みます。
以上によって、Terminalで「$ python」と打ち込むことで、Pythonを動かせるようになりました。

入力できる場所が「>>> 」という表示になっていれば、Pythonが起動できています。
試しに、「>>> 1 + 1」と入力して、Enterを押してみてください。

上の画像のように「2」と表示されていればOKです!
ここまでで、Pythonを動かせる準備は終了です!
まずは第一段階クリアですね。
Amazonの商品データにアクセスできるようになる
Pythonを実行できる環境も整ったので、早速AmazonにアクセスしてAmazonの商品データを取得したいっ!...ところですが、プログラム経由でデータを取得できるようになるために必要な設定があるので、それをまずは終わらせましょう。
****** 注意 ******
すでにAmazon Product Advertising APIにアクセスすることができる方は、「Amazonで本データを取得してみる」の箇所まで読み飛ばしてください。
Amazonの商品データにアクセスするためには、以下の手順が必要です。
・Amazonアソシエイト・プログラムに登録する。
・Amazon Product Advertising APIの認証情報を取得する。
それでは、順を追って進めていきましょう。
①Amazonアソシエイト・プログラムに登録する。
Amazonアソシエイトに登録していない場合はAPIを利用することができないので、まずは以下のリンクからAmazonアソシエイトに無料登録します。
Amazonアカウントにログインすると、Amazonアソシエイト・プログラムの画面が表示されるので、「無料アカウントを作成する」というボタンをクリックします。
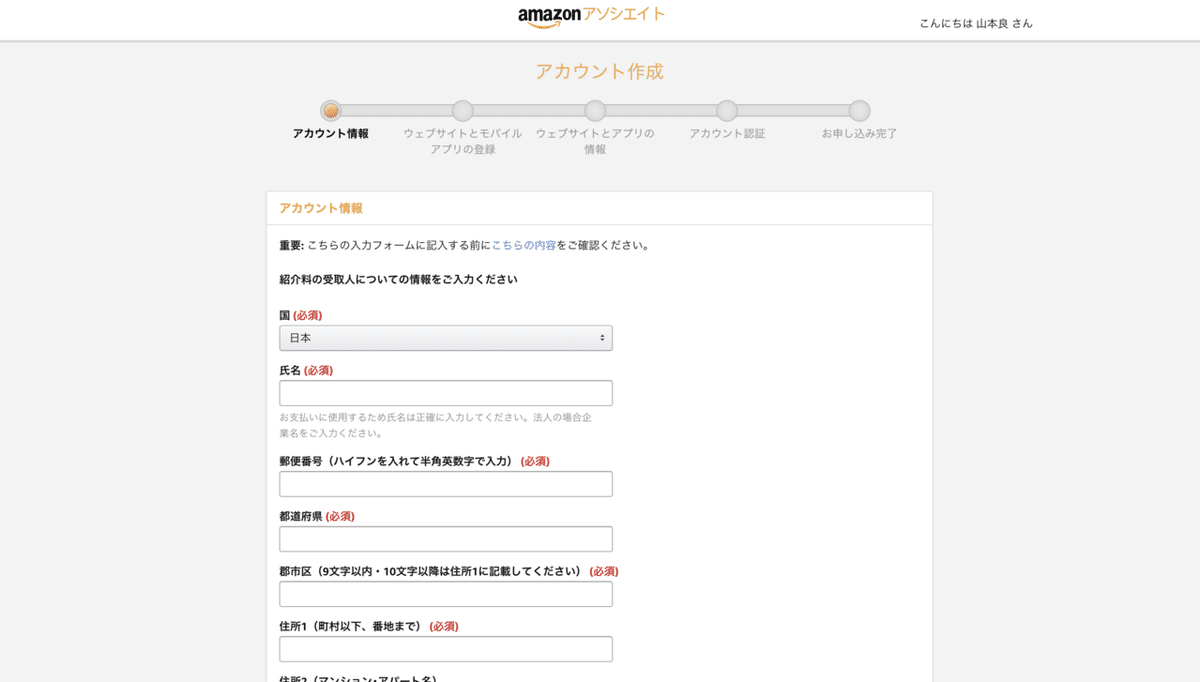
アカウント作成画面に遷移するので、必須項目を入力していきます。
次の画面でウェブサイト情報の入力欄があるので、ここに自分のnoteやブログやWebサービスのURLを入力します。
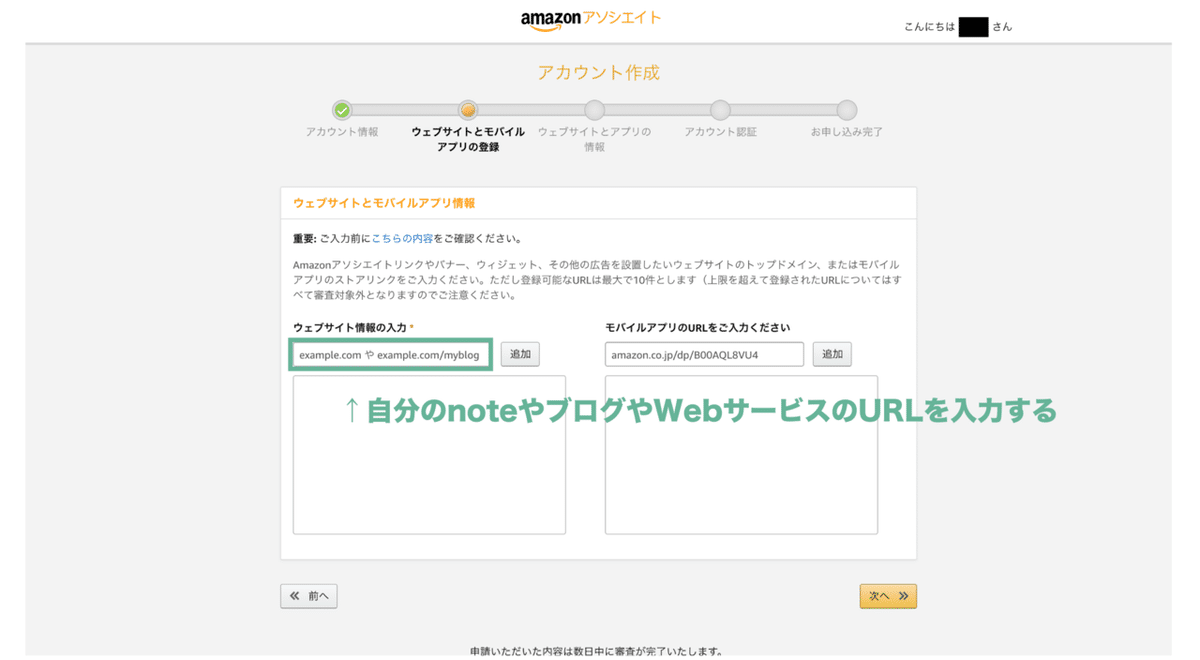
Amazonアソシエイト・プログラムは、Amazonの商品を紹介するプログラムなので、どんなサイトやサービスで利用されるのかを入力して欲しいということですね。
僕は自分のブログがあるのでブログのURLを入力して登録しました。
もしもブログもnoteもやっていないという方は、アソシエイト・プログラムに登録することができないので、無料ではてなブログアカウントを開設するなり、noteのマイページを作成して登録すると良いと思います。
※記事がほとんどないと、この後のアソシエイト登録の審査でNGになるかもしれないので、記事がある程度ある状態にしておきましょう。(ぼくは15件くらい記事がある段階で初めてAmazonアソシエイト登録をして、審査OKになりました。)
次の画面で、ウェブサイトに関しての詳細情報を入力していきます。

次の画面で、アカウントの認証(本人確認)を行います。

本人確認が完了し、登録が完了したらAmazonで審査が行われるのを待ちます。
審査結果はAmazonに登録したメールアドレスに送信されてくるので、待ちましょう(数日待つ場合もあるようです)。
②Amazon Product Advertising APIの認証情報を取得する。
Amazonアソシエイト・プログラムの登録完了のメールが届いたら、Amazonアソシエイト画面にアクセスします。
Amazonアソシエイト画面が開きます。

「ツール」というタブをクリックし、「Product Advertising API」をクリックしてください。

認証キーの管理という箇所の「認証情報を追加する」ボタンをクリックします。
ボタンをクリックすると次の画面で、「アクセスキー」と「シークレットキー」が表示されているので、それぞれメモしておきます。
※この認証情報を使って、Amazonはあなたからのアクセスであることを確認するもので、漏れてしまうと悪用される恐れがあるので、他人には知られないようにしておきましょう。
以上で、Amazonにプログラムでアクセスする(APIでリクエストを送る)ための準備が完了しました。
Amazonで本データを取得してみる
手始めに、先ほど用意したアクセスキーなどを利用して、PythonでAmazonの本データを取得してみます。
Amazonのデータにアクセスするためのライブラリのインストール
まずは、bottlenoseとbeautifulsoup4というライブラリをインストールします。
Terminalで「$ pip install bottlenose」と「$ pip install beautifulsoup4」を打ち込んで、実行する。
$ pip install bottlenose
$ pip install beautifulsoup4ちなみにbottlenoseは、Amazonのデータにアクセスするときに使う便利なプログラムで、beautifulsoup4はAmazonから取得したデータから自分の欲しいデータを取得する際に便利なプログラムです。
下のコマンドを実行してbottlenoseとbeautifulsoup4のバージョンが表示されれば、インストールできています(表示されているバージョン番号は違っても大丈夫です)。
「$ pip list | grep -e bottlenose -e beautifulsoup4」と打ち込んで、ライブラリがインストールできているか確認する。
$ pip list | grep -e bottlenose -e beautifulsoup4
beautifulsoup4 4.7.1
bottlenose 1.1.8
Amazonのデータにアクセスしてみる
ライブラリがインストールできていることが確認できたら、get_amazon_book.pyという名前のPythonファイルを作成し、以下のようなコードを書いて実行してみましょう。
get_amazon_book.py
import bottlenose
from bs4 import BeautifulSoup
# 以下3つの値は自分の認証情報で書き換える。
ACCESS_KEY = 'xxx'
ACCESS_SECRET_KEY = 'xxx'
ASSOCIATE_TAG = 'xxx'
REGION = 'JP'
AMAZON = bottlenose.Amazon(ACCESS_KEY, ACCESS_SECRET_KEY, ASSOCIATE_TAG, Region=REGION)
# Amazonで検索するキーワード
KEYWORD = 'Python'
def get_amazon_book():
response = AMAZON.ItemSearch(Keywords=KEYWORD, SearchIndex="Books", ItemPage=1, Sort='price',
MinimumPrice=800, ResponseGroup='Medium,SalesRank')
soup = BeautifulSoup(response, "lxml")
print('soup: ' + str(soup))
get_amazon_book()「xxx」となっている箇所は、前に用意した自分のAmazon APIへのアクセスキーとシークレットキーで書き換えます。
ファイルを作成できたら、このファイルを実行してみます。
「$ python get_amazon_book.py」と打ち込んで実行します。
$ python get_amazon_book.py
soup: <?xml version="1.0" ?><html><body><itemsearchresponse xmlns="http://webservices.amazon.com/AWSECommerceService/2013-08-01"><operationrequest><httpheaders><header name="UserAgent" value="Python-urllib/3.7">...</content><islinksuppressed>0</islinksuppressed></editorialreview></editorialreviews></item></items></itemsearchresponse></body></html>上のような「soup: ...」という長い文字列が表示されていればOKです。
簡単にプログラムの内容を説明しておきますね。
import bottlenose
from bs4 import BeautifulSoup
# 以下3つの値は自分の認証情報で書き換える。
...「import bottlenose」や「from bs4 import BeautifulSoup」という箇所は、ファイル内の処理でライブラリを使えるように書いています。
...
REGION = 'JP'
AMAZON = bottlenose.Amazon(ACCESS_KEY, ACCESS_SECRET_KEY, ASSOCIATE_TAG, Region=REGION)
# Amazonで検索するキーワード
...「AMAZON = bottlenose.Amazon(ACCESS_KEY, ACCESS_SECRET_KEY, ASSOCIATE_TAG, Region=REGION)」の箇所で、Amazonにアクセスしてデータを取得するための準備をしています。
def get_amazon_book():
response = AMAZON.ItemSearch(Keywords=KEYWORD, SearchIndex="Books", ItemPage=1, Sort='price',
MinimumPrice=800, ResponseGroup='Medium,SalesRank')
soup = BeautifulSoup(response, "lxml")
print('soup: ' + str(soup))
get_amazon_book()「def get_amazon_book():」は、メソッドを定義しています。「def xxx():」という書き方でメソッドと呼ばれる一連の処理のまとまりを定義できます。ここでは、Amazonの本のデータを取得してTerminalに表示するという一連の処理をメソッド化しています。
最後に「get_amazon_book()」と書くことで、メソッドを実行しています。
「response = AMAZON.ItemSearch(Keywords=KEYWORD, SearchIndex="Books", ItemPage=1, Sort='price',
MinimumPrice=800, ResponseGroup='Medium,SalesRank')」という箇所でAmazonにアクセスしてデータを取得しています。どのようなデータが欲しいのか以下の条件を指定しています。
・「Keywords=」...Amazonで検索するキーワード
・「SearchIndex=」...何を検索するか
・「ItemPage=」...何ページ目を取得するか。最大10件分しかデータが取得できないので、ここを1,2,3...と変えることでデータを取得していく。
・「Sort=」...並び替え条件。ここでは「price」と指定して価格の安い順に指定している。
・「MinimumPrice=」...検索結果に含める商品の最低価格
・「ResponseGroup=」...どのデータを取得するか
どのような条件のどの商品のデータが欲しいかは、プログラムのここをいじればOKです。
Amazonの欲しいデータだけを出力する
今のプログラムではAmazonから取得した全てのデータをTerminalに出力してしまっているので見づらいですね。
get_amazon_book.pyを以下のように修正して、本の主要なデータだけを出力するようにしましょう。
get_amazon_book.py
import bottlenose
from bs4 import BeautifulSoup
# 以下3つの値は自分の認証情報で書き換える。
ACCESS_KEY = 'xxx'
ACCESS_SECRET_KEY = 'xxx'
ASSOCIATE_TAG = 'xxx'
REGION = 'JP'
AMAZON = bottlenose.Amazon(ACCESS_KEY, ACCESS_SECRET_KEY, ASSOCIATE_TAG, Region=REGION)
# Amazonで検索するキーワード
KEYWORD = 'Python'
def get_amazon_book():
response = AMAZON.ItemSearch(Keywords=KEYWORD, SearchIndex="Books", ItemPage=1, Sort='price',
MinimumPrice=800, ResponseGroup='Medium,SalesRank')
soup = BeautifulSoup(response, "lxml")
titles = soup.find_all('title') # タイトル
asins = soup.find_all('asin') # アマゾンの商品コード
sales_ranks = soup.find_all('salesrank') # 売り上げランキング
urls = soup.find_all('detailpageurl') # アフィリエイトリンク
publication_dates = soup.find_all('publicationdate') # 掲載日
release_dates = soup.find_all('releasedate') # 出版日
for i in range(len(titles)):
print('タイトル: {}\nAmazon商品コード: {}\n売り上げランキング: {}\n商品詳細URL(アフィリエイトリンク): {}\nAmazon掲載日: {}\n出版日: {}\n'
.format(titles[i].text, asins[i].text, sales_ranks[i].text, urls[i].text, publication_dates[i].text, release_dates[i].text))
get_amazon_book()
「soup.find_all('title')」のように書くことで、BeautifulSoupを使って「<title>速習 Python 3 中: オブジェクト指向編</title>」のように「<title>」タグで囲まれている要素を全て取得できます。
さらに「.text」と書くことで、<title>タグの中の「速習 Python 3 中: オブジェクト指向編」という文字列だけを取得可能。
「$ python get_amazon_book.py」を実行してみます。
$ python get_amazon_book.py
タイトル: 速習 Python 3 中: オブジェクト指向編
Amazon商品コード: B01N04UBYI
売り上げランキング: 2448
商品詳細URL(アフィリエイトリンク): https://www.amazon.co.jp/%E9%80%9F%E7%BF%92-Python-3-%E4%B8%AD-%E3%82%AA%E3%83%96%E3%82%B8%E3%82%A7%E3%82%AF%E3%83%88%E6%8C%87%E5%90%91%E7%B7%A8-ebook/dp/B01N04UBnId=AKIAJFY7GRZ73UOUD62Q&tag=myblogsite03a-22&linkCode=xm2&camp=2025&creative=165953&creativeASIN=B01N04UBYI
Amazon掲載日: 2016-11-06
出版日: 2016-11-06
...ファイルを実行するとPythonに関する本のデータがずらっと10件分表示されます。
以上で、Amazonのデータを取得し、欲しいデータだけを取り出すことができるようになりましたね。
Amazonにアクセスしてデータを取得することができるようになりましたが、Terminalに表示するだけだとデータを蓄積・分析していくことができません。そこで、データを比較的簡単に蓄積でき、分析もしやすいGoogleのSpread Sheetにデータを蓄積していく方法を紹介していきます!
Spread Sheetにアクセスできるようになる
まずは、プログラムでSpread Sheetにアクセスできるようになるための準備をしていきます。
****** 注意 ******
すでにプログラムでSpread Sheetにアクセスできる方は、「Amazonの本データをSpread Sheetに書き込む」の箇所まで読み飛ばしてください。
①Spread Sheet APIの用意
まずは、Spread Sheetにプログラムから書き込みを行うために、Sheet APIを使えるように設定していきます。
まずは、GoogleのAPIを管理するためのサイト(Google Cloud Platform)にアクセスします。
Google Cloud Platformにアクセスする。
Google Cloud Platformにアクセスしたら、上の画像のようにプロジェクトを作成をクリック
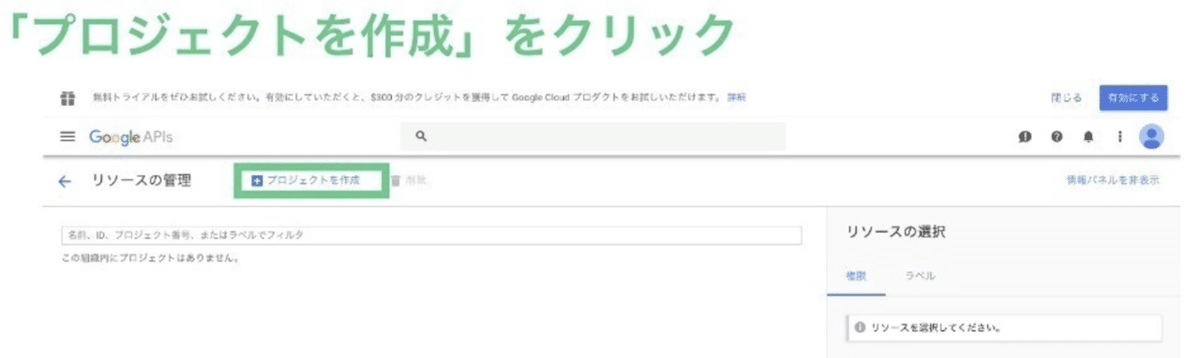
次の画面で、適当なプロジェクト名をつけて、保存をクリックする。

先ほど作成したプロジェクトが選択されている状態で、Google Drive APIを検索し、クリックする。

遷移先の画面で、「有効にする」をクリックする。

上の画像の「管理」の部分が「有効にする」になっているはずです。
「認証情報を作成」をクリックする。

Google Drive APIを有効にするをクリックした後の遷移先の画面で、「認証情報を作成」をクリックします。
任意のサービズアカウント名で、役割は「編集者」、キーのタイプは「JSON」を選択し、「作成」をクリックする。

サービスアカウントキーの作成をします。
ダウンロードされたJSONファイルを開く。

JSONファイルがダウンロードされるので、そのファイルを開いてみます。

ファイルを開くと、認証情報が記載されていることがわかります。このファイルに書かれている認証情報を後ほど使うので、このJSONファイルは消してしまないように注意しましょう。
Google Sheets APIの「有効にする」をクリックする。
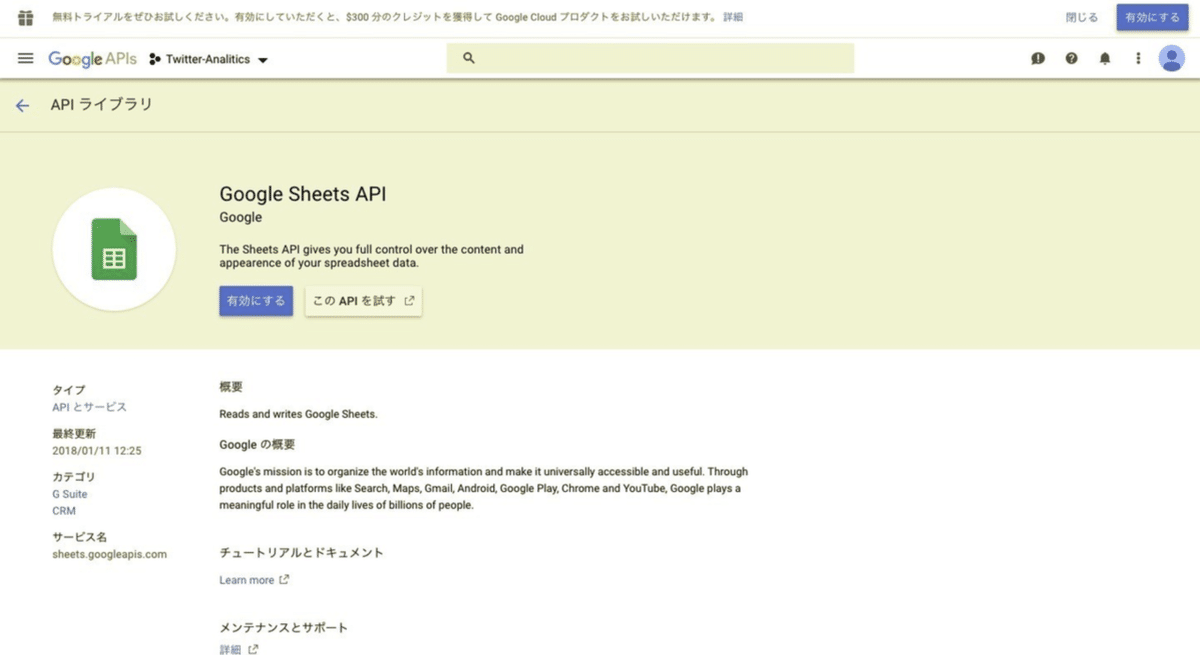
同じように「Google Sheets API」も検索し、「有効にする」をクリックして有効にしておきましょう。
以上でGoogle Cloud Platformの設定は完了です。
②Spread Sheetに書き込んでみる
ここからは、先ほど設定したSheet APIを利用して、プログラムからGoogle Spread Sheetに書き込みをしていきます。
新しいスプレッドシートを作成する。

先ほどGoogle Cloud Platformで設定をしたときに使っていたアカウントで、新しいSpread Sheetを作成します。
先ほど設定した際にダウロードしたJSONファイルを再度開き、「"client_email": "xxxxxx"」の行のxxxxxxの箇所をコピーする。

Spread Sheetに読み書きする権限を与えるため、Client Emailの値をコピーします。
ファイル > 共有をクリックし、編集権限を与えるユーザーの設定ウィンドウを開く。

編集権限を与えるユーザーの設定欄に、Spread Sheetの先ほどコピーしたメールアドレス「xxxxxx」を貼り付け、「保存」をクリックする。

これで、プログラムからAPI経由でSpread Sheetにアクセスして読み書きすることができるようになりました。
次に、プログラムの実装をしていきます。
$ pip install gspread
$ pip install oauth2client「$ pip install gspread」と「$ pip install oauth2client」を実行する。
まずは、gspreadとoauth2clientというライブラリをインストールします。これらを利用することで簡単にSpread Sheetに読み書きすることができるようになります。
次に、先ほどダウンロードしたJSONファイルを、「spread_sheet_credential.json」というファイル名に変更し、次に作成する「sheet_test.py」というファイルと同じディレクトリに移動させてください。(ディレクトリが同じ前提で、認証情報が書かれたJSONファイルにアクセスするようなコードにしているためです。)
「spread_sheet_credential.json」と「sheet_test.py」を同じディレクトリにある状態にする。

「sheet_test.py」には、以下のようなコードを書きます。
sheet_test.py
# coding=utf-8
import gspread
from oauth2client.service_account import ServiceAccountCredentials
CREDENTIAL_FILE_NAME = 'spread_sheet_credential.json'
SCOPE_URL = 'https://spreadsheets.google.com/feeds'
# ↓アクセスしたいSpread SheetのID
GID = 'xxxxx'
# ↓アクセスしたいSpread Sheetのシート名
SHEET_NAME = 'シート1'
def access_to_sheet(gid):
credentials = ServiceAccountCredentials.from_json_keyfile_name(CREDENTIAL_FILE_NAME, SCOPE_URL)
client = gspread.authorize(credentials)
return client.open_by_key(gid)
sheet = access_to_sheet(GID)
worksheet = sheet.worksheet(SHEET_NAME)
worksheet.update_acell('A1', '書き込みテストだよ')「sheet_test.py」を作成し、上記のコードを書き、「xxxxx」を書き換える。
「アクセスしたいSpread SheetのID」は、Spread SheetのURLの「https://docs.google.com/spreadsheets/d/xxxxx/edit#gid=0」のxxxxxの部分で書き換えてください。

これでSpread Sheetに書き込む設定とプログラムができました。「sheet_test.py」を実行してみましょう。
「$ python sheet_test.py」を実行する。
$ python sheet_test.py
実行してどこでもエラーがおきなければ、Terminalには何も表示されません。

Spread Sheetには、目論見通りA1のセルに「書き込みテストだよ!」と書き込まれています!
これでSpread Sheetに書き込みをすることができるようになりました。
*「$ python sheet_test.py」を実行してエラーになる場合と対処法*
①"status": "PERMISSION_DENIED"と表示される
→Google Cloud PlatformのSheet APIもしくはDrive APIの「有効にする」がうまく設定できていない可能性があります。再度Google Cloud Platformにアクセスして、Sheet APIとDrive APIの設定が有効になっているか確認してみてください。
②「No such file or directory: 'spread_sheet_credential.json'」と表示される
→ダウンロードしたJSONファイルのファイル名が「spread_sheet_credential.json」に変更できていること、同ファイルと「sheet_test.py」が同じ階層にあることを再度確認してみてください。
Amazonの本データをSpread Sheetに書き込む
Spread Sheetに書き込みができるようになったので、Amazonから取得したデータをSpread Sheetに書き込んでみましょう。
まずは、Spread Sheetの1行目を以下の画像のSpread Sheetのようにします。(1行目の内容を例と揃えることは必須ではなりませんが、揃っている前提でプログラムを進めます。)

Spread Sheetが用意できたら、以下のような処理をするコードを書いていきます。
・Amazonの特定のキーワードの本のデータを収集する
・Spread Sheetにまだ書き込まれていないかどうか判定する
・Spread Sheetにまだ書き込まれていない場合はデータを追加書き込みする
「collect_amazon_books.py」というファイルに、以下のようなコードを書きます。
※ファイルは、「spread_sheet_credential.json」と同じディレクトリに作成してください。
collect_amazon_books.py

この記事が気に入ったらチップで応援してみませんか?