
DIfy最新版(v0.7.3)でチャットフローを使い画像生成ツールを比較してみました ---その3 生成画像の比較

はじめに
Difyはワークフロー形式でアプリ機能を組み立てる事ができます。
ワークフローは機能を持ったブロックを左から右方向に連結していって全体のアプリとしての機能を発現させるのですが、そのブロックの一つに、ツールというのがあります。
ツールは、主に他社の開発した機能を引用するのに使えます。たとえばGoogleの検索機能や、Perplexityの検索機能なども、APIを通じてツールとして組み込み使えるようになっています。ちなみに後者は、v0.7.3でリリースされました。
このようなツール群の一種に画像生成AI機能があります。これらについて、前々回で4社のツールをピックアップしました。
また、前回、Stable AIのツールを例に、画像生成ツールの使い方の基本形を示し描画できることを示しました。
今回は、各社の生成画像を同じプロンプトによる描画結果を基に比べてみたいと思います。
3. 各ツールの画像生成例とパラメータの設定について
ということで、以下に、各ツールの画像生成例を示します。
前回からの続きということで、3章からのスタートです。
画像生成ツールのお話ですので、まずは、生成画像を見比べてみるのが一番かと思います。
3-2. 各ツールの画像生成の結果
比較として、私のブログによく登場する黒魔女ベラドンナと白魔女フィオナ用の同じプロンプトを用いました。
他にも、比較用としては、子猫のジェイド君とかスポーツカーとか、文字をいれてみるとか、色々ありますが、まずは大雑把に傾向を見てみたいと思います。
また、各ツールの冒頭に今回の設定画面を示します。場合によっては、簡単にパラメータの設定値についての解説をつけ、さらに生成画像についてはコメントをいれます。
このコメントは、過去、Leonardo.AIで同じプロンプトで色々画像生成した経験に基づく主観です。
ところで、この各ツールの生成結果は、Dify自身の頻繁なバージョンアップと共にツールも都度改良されていますので変わる可能性があります。
今回のは、v0.7.3におけるアウトプットの結果です。
今回の検証用の画像生成には、前回ご紹介した、チャットフローを使いました。このように、色々なツールの設定値を変えた結果を連続して出力するには結構便利でした。
3-1-1. Dall-E3 by Open AI
これには、E2とE3の2つのツールがありますが、Dall−E3の結果を示します。E2は、生成結果を比べてみましたが、生成画像のレベルが低く、現時点では不要かと思います。
画質は、HDとStanndardがありますが、HDを選択します。
また、Image Styleとして、Naturalと、Vividがあるので、両方それぞれ示します。
3-1-1-1. Dall-E3ツールの設定画面

注:上記の図で、青い枠で囲んだNumber of Imagesは、現在1しか設定できません。ちなみに他のツールで、2以上を設定できるのもありますが、Difyの回答ノードは、1つしか出力できません。
デバッグすると、複数枚数の設定の場合、画像生成ツールの出力には、それぞれ複数出力されていますが、回答ノードは最後のしか出力できないようです。
回答ノードのある種のバグと言えるかと思います。
3-1-1-2. Dall-E3ツールの生成画像の例
Natural ベラドンナ

Naturalと言いながら、なかなかの迫力です。結構ユニークな画像です。イラスト系でしょうか。
Vivid ベラドンナ

Vividは、抽象度が増すような設定なのでしょうか。抽象絵画的なイメージです。緻密に描かれており、描画能力の欠如した結果得られるぼんやりとした生成結果ではありません。結構ユニークです。
もちろん、出力結果は都度違いますので、なにがでてくるか、お楽しみ、でしょうか。
参考として、同じプロンプトの違う例を次に示します。

どうやら、このプロンプトについては、Vividは割合抽象的な画像生成結果を出力するようです。また、黒魔女を述べているプロンプトの本質を理解しているように見えます。
Ntural フィオナ

この結果には、少し驚きました。他のツールは、このプロンプトの場合、どちらかというと若い清楚な雰囲気の白魔女を描くのですが、この画像生成結果は結構熟練した白魔女のイメージです。また、おとぎ話の映画のワンシーンのような印象の、背景の細部もよく描かれた画像です。
先ほどのNaturalのベラドンナとの画像の対比は、ドラマ的です。なにやら童話的なわかりやすいストーリーができそうです。
Vivid フィオナ

ViVIdのこの結果は、先ほどのベラドンナのVividの傾向とはかなり異なり、ある意味、リアル画像に近い画風です。このツールのVividは、プロンプトによる違いがかなり出やすいような設定なのかもしれません。プロンプトの工夫次第ということでしょうか。
Dall-E3はあまり使ったことがないのですが、初期よりもかなり進化しているのではないでしょうか。先程のもそうでしたが、さすがOpenAIという印象的な画像です。
ここでは、 Naturalとは異なり、若々しい貴婦人のような白魔女を描いています。
さらに、白魔女は、白い衣装が多いのですが、ライトの影響でしょうか、描写が黄色がかっており、それもまた印象的です。袖口などから衣装は本来白いようです。杖の光の反射を示すリアルさの追求の結果とも言えるかもしれません。
3-1-2. Stable Diffusion by Stability AI
これは、ツールとして同社のv2betaのモデルのcore, SD3, SD3turboの3種類選択できます。
それぞれについて画像生成してみました。
3-1-2-1. Stable Diffusionツールの設定画面の例

このSDの設定画面でユニークなのは、Negative Promptに始めから設定が入っていることです。内容は好ましくない画像が出ないような工夫のようです。
また、モデルは選べますが、それ以上の画像用の設定はありません。唯一画像のアスペクト比が設定できます。
3-1-2-2. Stable Diffusionツールの生成画像の例
Core ベラドンナ

このプロンプトでは、記載はしてないのですが、なぜか手先から炎を出すことがよくあります。ある意味、この結果は典型的です。なお、この場合、指先もキチンと5本描写されています。
また、背景も、ダークで緻密。鳥なども描きこまれています。細かな描写力を感じます。
Core フィオナ

全体に先のベラドンナ同様、リアル系のイラストと言う画風です。このプロンプトの場合、SDXL系では、この結果と同様に背景に月がよく描かれます。これも、月がそれらしく見えます。背景が緻密です。本モデルはv2Beta系ですが、v1のSDXLの雰囲気を感じます。ただ、表情の傾向がやや異なるようです。
SD3 ベラドンナ

このモデルの場合、どちらかというとリアル系の画像生成の傾向のようです。ただ、この絵から、黒魔女を連想するのは難しいですね。映画のカットのようです。映画的シーン生成の設定がなされているのかもしれません。
SD3 フィオナ

やはり、顔がリアル系に描かれるように設定されているようです。この場合、背景のぼかしも効果的です。ボケさせてはいますが、背景がちゃんと描かれているのがわかります。
これも、Dall-E3と同様、プロンプトの設定の影響が大きく出るタイプかもしれません。例えばプロンプトでリアル画像生成を強調すれば、それなりのリアリティーを出してくるように思われます。
SD3turbo ベラドンナ

なぜか、この絵は、モノクロで出力されました。イラスト系ですが、細部が良く描きこまれています。黒魔女、という設定には、ある意味合致しています。
さらに、同じプロンプトでもう一枚。

通常は、このように着色されたパタンが出力されます。リアルっぽいイラストです。描写は緻密で、細かい白い点々は、炎の火の粉のイメージでしょうか。
でも、これも帽子以外、黒魔女っぽくはないですね。映画のシーン的かと。
SD3turbo フィオナ

かなり細かく緻密な描写のイラスト画風です。SD3のレベルの高さがかいま見えます。
背景も、ごまかさず、立体的によく描きこまれています。
なぜか、月が2つです。リアルさよりも幻想的なイメージの表出にウェイトがおかれている結果かもしれません。
3-1-3. Stable Diffusion by Silicon Flow
3-2-3-1. Stable Diffusionツールの設定画面の例

Guidance Scaleは、通常20以下、4-10の範囲で設定します。アプリや他の設定によっては、この設定で、画像が大きく変化します。通常7-8程度が標準です。このパラメータは、プロンプトの影響度を反映します。
Num Inference Stepsは、10-30程度が推奨されます。20が標準です。サンプラーのサンプリング回数で、多いほど緻密になりますが、あまり多いと生成時間が長くなります。
3-2-3-2. Stable Diffusionツールの生成画像の例
SDXL ベラドンナ

比較的典型的な、SDXL系の生成結果です。このプロンプトの場合、手首の先から炎を出すことが多いのですが、指先は描かれていません。この画像の表現は荒い印象で、全体にぼやっとしています。
現時点では、相対的に画像生成能力が低いという印象を受けます。
SDXL フィオナ

割合典型的なSDXL系の画像生成に見えます。イラスト系です。このプロンプトの場合、犬や狼、うさぎや狐などの野生動物が生成されることが多く、この画像もそうなっています。
全体にぼんやりしているのが、このシーンの描写には合っています。画質は、古い画像生成AIの印象を受けます。さきほどのSDcoreの結果と比べると大きな差を感じますが、これはモデルの世代の差というよりも当社がSDXLを使いこなせていないため、ということのように思えます。
SD3 ベラドンナ

向かって左側の頭部の画像生成が、崩れているように見えます。サンプリングが不完全なのではないかと考えられます。サンプラーがちゃんと働いていないような印象です。
同じ条件でもう一枚示します。

向かって左側(右手)手の描写が不完全。左側(右手)は、描写が破綻しており、右側は、手が複数(3本?)あります。もちろんプロンプトにそのような設定はありません。まぁ、魔女ですから何でもOKなんですが。
全体に画像生成が不完全で、一時、悪い意味で話題になったSD3の初期バージョンではないかと思われます。背景もわかりにくい描画です。
開発途上という印象で、現時点での完成度は相当低いと感じます。
SD3 フィオナ

カラーリングが、割合はっきりとした3原色系のような色使いの印象を受けます。またグラデーションをあまり感じません。これらは設定者の好みかもしれません。
全体に、Stable AIの各モデルとベースが同じ系列とはちょっと思えないような低レベルという印象です。
3-1-4. Flux by Silicon Flow
3-1-4-1. FLUXツールの設定画面の例
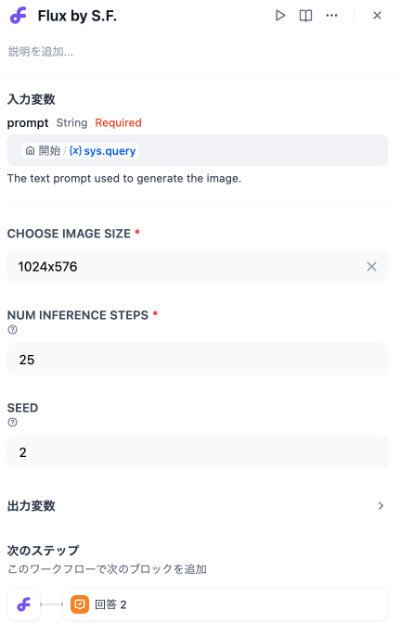
このツールには、画像に影響するパラメータは設定されていません。
3-1-4-2. FLUXツールの生成画像の例
ベラドンナ

向かって右(左手)指が6本あります。先ほどの当社のSD3よりはかなりマシですが、表情の悪辣さはDall-E3の方が感じます。一方、細部が良く描かれています。
これは、プロンプトの何らかのキーワードで、アメリカンコミック的な出力になっているのかもしれません。
フィオナ

手前の人物像は、細部まで、緻密によく作られているという印象を受けます。人物に比べ、背景がやや雑ともいえますが、この場合は、それが効果的かもしれません。Fluxの優れた描画能力が垣間見えるようです。
なお、同じ条件で画像生成したところ、他とは異なる結果を得ました。
シード値が同じだと、このツールは全く同じ画像を生成します。少し驚きです。
なお、下記は、異なるシード値の同じプロンプトの例です。本ツールは、Dall-E3などとは異なり、似た傾向の画像を生成しました。

確かにSeed値は、Consistency(一貫性)のためのパラメータですが、通常の画像生成AIの場合、複数の枚数を描かせると他のパラメータが自動的に変わるような設定をされているため、これまで示したように全く異なる画像を生成するのが普通です。このツールの場合は、その他のパラメータは不変のようです。
これが、Fluxの一般的な設定方法なのか、Silicon Flowの設定方法なのかは、現時点では不明です。
3-1-5. Novita AI Text to Image by Novita AI
3-1-5-1. Text to Imageツールの設定画面の例
このツールは設定項目がとても多く、3分割して示します。
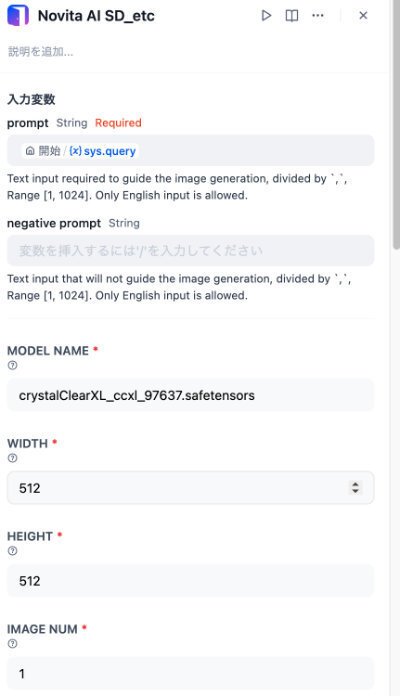


それぞれのパラメータで画像は大きくかわりますので、下記の例は、参考データです。
3-1-5-2. Novita.AI / Text to Imageツールの生成画像の例
参考 SDXL ベラドンナ

参考 SDXL フィオナ

共に画像生成速度が極めて遅く、かなり問題となるレベルです。これは、512✕512の画像ですが、この解像度が事実上限界のようです。ちなみに他社は、1024✕1024以上の解像度をらくらくクリアします。
他社並みの解像度にすると、長く待たされた上に、タイムアウトで生成不可となります。
この遅さは、許容しがたいレベルで、そのような意味でも、これは参考データです。
このSDXL系のモデルの生成結果は、通常のSDXLのイラストの傾向ではありますが、クオリティは、残念ながら、かなり低レベルという印象です。
そもそも低解像度の画面ということもあるのか、ベラドンナの表情が平板で、フィオナは、表情が描かれていません。
生成画像結果のまとめ
Dify の v0.7.3で提供されている画像生成ツールを使って、同じプロンプトで得られる画像を比較してみました。
その結果、各社でかなり大きな違いがあることがわかりました。
また、Dall-E3以外の基本モデルは、SD系またはFluxですが、基本モデルが同じでも、その生成結果の傾向と質がかなり異なりました。
現時点で、画像生成ツールとして実用的に使えそうなのは、OpenAIのDall-E3と、Stability AIのStable Diffusionの2つです。これらは、Difyで初期から提供されている画像生成ツールでもあります。
また、最近リリースされたSilicon FlowとNovita.aiの画像生成ツールは、 SiliconFlowのFlux以外は、現時点では完成度が低く、実用レベルにはまだ至っていないようです。また、Fluxもよりチューニングが必要そうです。
今後の進化が期待されます。
Dall-E3とStable Diffusionでは、それぞれプリセット値やモデルが複数設定できますので、画像生成用のツールのバリエーションとしては、全体で、2+3=5種類から選択可能です。それぞれ、生成される画像の画風などが異なります。
また、プロンプトによって、それらの画像の傾向そのものも大きく変わる場合もありますので、画像生成用のプロンプトをコントロールしながらLLMで向上させることで、より用途や目的に沿った画像が比較的簡便に得られる可能性が高いと思われます。
Difyは、条件文とともに各社の先端のLLMを組み合わせることもできるので、プロンプト生成の機能を追加することで、アプリ全体の性能向上が期待できそうです。
この記事が気に入ったらサポートをしてみませんか?