
AWS 認定ソリューションアーキテクトプロフェッショナル問題集1

はじめに
AWSソリューションアーキテクトプロフェッショナルの問題集になります。全部で30問あり設問が終わったあと30問分の回答があります。10問までは問題だけ無料で閲覧可能です。実際の試験は75問あり、文章が長く試験時間も180分と1問にかけられる時間が短いです。この問題で慣れておくと合格に近づくことができると思います。本問題集が対応しているテストのバージョンはSAP-C01です。新しいバージョンのテストが出たら公開を停止する予定です。SAP-C02になったので、無料公開にします。
問題1
継続的デプロイのプロセスの中で、スナップショットから作成されたボリュームを持つ新しいAMIを使用して本番環境に展開される前に、アプリケーションは、I/O負荷パフォーマンスのテストをします。アプリケーションはインスタンスごとに1つのAmazon EBS プロビジョンドIOPSボリュームを使用し、一貫したI/Oパフォーマンスが必要です。 I/O負荷パフォーマンステストで再現性のある方法で正しい結果が得られるようにするには、次のうちどれを実行する必要がありますか?(1つ選択してください)
A. テストでI/Oブロックサイズがランダムに選択されることを確認する。
B. テストの前にすべてのブロックを読み込むことでEBSボリュームを初期化(事前ウォーミング)されていることを確認する。
C. EBSボリュームのスナップショットをバックアップから作成されていることを確認する。
D. EBSボリュームを暗号化されていることを確認する。
E. テストの前にスナップショットをバックアップから作成することでEBSボリュームを初期化(事前ウォーミング)されていることを確認する。
問題2
あるソリューションアーキテクトはAWSで標準的な3層からなるWEBアプリケーションを運営する会社で働いています。WEB層とAP層はEC2インスタンス、DB層はRDSです。同社は、ウェブ層とアプリケーション層をAPI GatewayとLambdaを使用したアーキテクチャに再設計しており、6ヵ月以内に新しいアプリケーションをデプロイする予定です。 ITマネージャーは、ソリューションアーキテクトに当面のコスト削減を依頼しました。信頼性を維持しながら、最も費用対効果の高いソリューションはどれですか?(1つ選択してください)
A. スポットインスタンスをWEB層に、オンデマンドインスタンスをAP層に、リザーブドインスタンスをDB層に使用する。
B. オンデマンドインスタンスをWEB層とAP層に、リザーブドインスタンスをDB層に使用する。
C. スポットインスタンスをWEB層とAP層に、リザーブドインスタンスをDB層に使用する。
D. リザーブドインスタンスをWEB層、AP層、DB層に使用する。
問題3
ある企業のWEBアプリケーションはVPCにデプロイしており、オンプレミス環境とIPsec VPN経由で接続されています。アプリケーションはオンプレミス環境のLDAPサーバに対し認証する必要があります。認証後、各ログインユーザはそのユーザ固有のS3キースペースのみにアクセスできます。これらの目的を満たすことのできる2つのアプローチはどれですか。(2つ選択してください)
A. 一時的なAWSの認証情報を取得しロールを引き受ける(AssumeRole)ために、IAM STSに対し認証するIDブローカーを開発する。アプリケーションは適切なS3バケットへアクセスするための一時的な認証情報を取得するため、IDブローカーをコールする
B. アプリケーションはLDAPに対して認証し、ユーザに関連づいたIAMロール名を取得する。それからアプリケーションはそのIAMロールを引き受けるためIAM STSをコールする。アプリケーションは一時的な適切なS3バケットへアクセスするための認証情報を使うことができる。
C. LDAPに対し認証するIDブローカーを開発し、フェデレーションされたユーザの認証情報を取得するためIAM STSをコールする。アプリケーションは適切なS3バケットへアクセスするためのフェデレーションされたIAMユーザの認証情報を取得するためにIDブローカーをコールする。
D. アプリケーションはLDAPに対し認証し、LDAPの認証情報を使いIAMにログインするためにIAM STSをコールする。アプリケーションはIAMの一時的な認証情報を使い適切なS3バケットへアクセスすることができる。
E. アプリケーションはLDAPの認証情報を使いIAM STSに対し認証する。アプリケーションはAWSの一時的な認証情報を使い適切なS3バケットへアクセスすることができる。
問題4
ドキュメント管理サービスを提供する会社がアプリケーションをAWSにデプロイし、無料会員とプレミアム会員の両方をサポートするようにビジネスモデルを変更しています。プレミアム会員は最大200GBのデータを保存でき、無料会員は5GBのみ保存できます。この会社は数十億のファイルが保存されると予想しています。すべての利用者には使用率が75%と90%に近づいたときに警告するようにする必要があります。無料会員とプレミアム会員をサポートするために、この会社はどのようにアプリケーションを設計しますか?
A. 会社はDynamoDBのユーザデータのカウンターを更新するためにSWF(Simple Workflow Service)のアクティビティワーカーを利用する。アクティビティワーカーはカウンターが適切な閾値を超えたらSESを使ってメールを送信する。
B. 会社は保存したファイルのサイズを管理するためのテーブルを持つためにRDSをデプロイする。アップロードサーバはユーザの使用容量を集計するためにクエリを投げ(最初にユーザで絞り、それからそれぞれのファイルサイズを検索する)、閾値を超えていたらSESを使ってメールを送信する。
C. 会社はコンテンツのサイズとファイル所有者の名前をS3のオブジェクトのメタデータとして記載する。その後、ユーザ毎のファイルサイズ合計を監視し、ストレージの閾値が超過した場合にSQS経由でメールを送信する処理を作成する。
D. 会社は1つは無料会員向けで、もう1つはプレミアム会員向けの2つのS3バケットを作成する。SWFアクティビティワーカーはデータが保存されているバケットの会員種別に応じたすべてのオブジェクトにクエリを投げストレージを集計する。アクティビティワーカーは必要に応じSNSを使ってユーザに通知する。
問題5
あなたはファイルが破損した場合に備えて、EC2インスタンス上にファイルレベルで復元できるようにする対応をしています。情報の損失が報告されてから15分以内に、EC2インスタンスで個々の失われたファイルを復元できる必要があります。許容されるRPOは数時間です。これをEC2インスタンスでどのように実行しますか?以下の選択肢から回答を選択してください。(1つ選択してください)
A. EBSボリュームからS3へファイルをコピーするジョブをcronで設定する。
B. 頻繁にEBSボリュームのスナップショットを取得し、EBSのスナップショットからボリュームを作成し、EC2インスタンスの別のマウントポイントにEBSボリュームをアタッチする。バックアップからファイルをコピーし新しいバックアップボリュームを参照するようにアプリケーションを切り替え、古いボリュームを削除する。
C. 頻繁にEBSボリュームのスナップショットを取得し、EBSのスナップショットからボリュームを作成し、EC2インスタンスの別のマウントポイントにEBSボリュームをアタッチする。新しいマウント先にある復元する必要のファイルをファイルシステムで参照し、バックアップボリュームからコピーする。
D. EC2の自動スナップショットを有効化し、単一ファイル障害時にEC2インスタンスを復元する。
問題6
会社がus-east-1とeu-west-1の2つのリージョンに3層のWebアプリケーションを展開しました。アプリケーションは、両方のリージョンで同時にアクティブでなければなりません。
アプリケーションのデータベース層は、us-east-1にマスター、eu-west-1にリードレプリカを持つ単一のAmazon RDS Auroraデータベースをグローバルに使用しています。両方のリージョンはVPNで接続されています。同社は、アプリケーションのすべてのコンポーネントがリージョン単位で障害が発生した場合でも、アプリケーションが引き続き使用可能であることを確認したいと考えています。
アプリケーションは最大1時間までは読み取り専用モードになっていることが許容されています。会社はリージョンごとに1つずつ、2つのRoute53のレコードセットを構成する予定です。会社は、要件を満たしながらアプリケーションのエンドユーザーに最小のレイテンシーを提供するために、どのように構成にする必要がありますか? (2つ選択してください。)
A. フェイルオーバールーティングを使いus-east-1をプライマリレコード、eu-west-1をセカンダリレコードとして設定する。WEBアプリケーションに対しHTTPヘルスチェックを設定し、us-east-1レコードセットに関連付ける。
B. 加重ルーティングを使いそれぞれのレコードに50の重みを設定する。それぞれのリージョンにHTTPのヘルスチェックを設定し、そのリージョンのレコードセットに関連付ける。
C. レイテンシーベースルーティングをそれぞれのレコードセットに使う。それぞれのリージョンに対しヘルスチェックを設定しそのリージョンに対するレコードセットに関連付ける。
D. us-east-1のヘルスチェックに対しCloudWatchアラームを設定し、eu-west-1のリードレプリカを昇格させるLambda関数を呼び出す。
E. us-east-1のDB障害に対し、eu-west-1のリードレプリカを昇格させるLambda関数を呼び出すRDSのイベント通知を設定する。
問題7
大規模な研究施設でのあなたの仕事は順調です。ナノテクノロジーに関する最新の研究の最前線にあり、あなたは非常に熱心に取り組んでいます。クラスタープレイスメントグループで実行されている9つのEC2インスタンスを持つインフラストラクチャのスケールアップを担当することになりました。これらの9つのインスタンスは初回起動時はすべて同時に起動され、想定通りに動作しているようです。グループに2つの新しいインスタンスを追加する必要があると判断しましたが、これを行おうとすると、「容量エラー」が表示されます。この問題を解決する可能性が最も高いアクションは次のうちどれですか?
A. クラスタープレイスメントグループのインスタンスを再起動させてから新しいインスタンスを起動する。
B. 新しいクラスタープレイスメントグループを作成し新しいグループで新しいインスタンスを起動させる。プレイスメントグループが同じサブネットにあることを確認する。
C. クラスタープレイスメントグループのインスタンス数の初期値は10のため容量制限の緩和を申請する。
D. すべてのインスタンスが同じサイズであることを確認して再度起動する。
問題8
fortune500に名を連ねる、ある企業は、Amazon S3の使用とハードウェアの追加を評価するTCO分析を行っています。その結果、すべての従業員に個人のドキュメントの保存にAmazon S3を使用するアクセス権が付与されることになりました。企業のADまたはLDAPディレクトリからのSSOを組み込み、各ユーザーのアクセスをバケット内の指定されたユーザーフォルダーに制限するには、次のどのソリューションを設定する必要がありますか? (3つ選択回答)
A. フェデレーションプロキシーかIDプロバイダーを作成する。
B. 一時的なトークンを作成するためにAWS STSを使用する。
C. バケットの各フォルダにタグを設定する。
D. IAMロールを設定する。
E. 会社のディレクトリに応じた、バケットのフォルダーにアクセスする必要のあるすべての従業員のIAMユーザを作成する。
問題9
あなたはクラウドおよびオンプレミスでアプリケーションインフラストラクチャの一部を管理するための新しいハイブリッドアーキテクチャを設計する会社のコンサルタントとして働いています。
インフラストラクチャの一部として、大量のデータを安定的にして転送する必要があります。 AWSへの低レイテンシで高い安定性のトラフィック送受信が求められています。同社は、コストを可能な限り低く抑えることを目指しており、主要な障害が発生した場合には低速のトラフィックでも許容しています。これらの要件を考慮して、ハイブリッドアーキテクチャをどのように設計しますか?以下のオプションから正しい答えを選択してください。
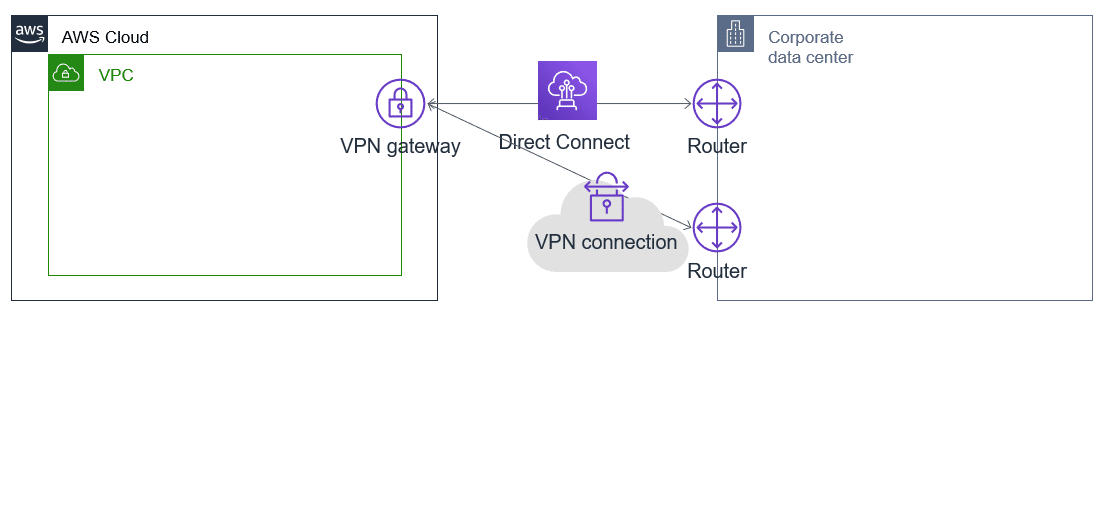
A. Direct Connectパートナーに依頼しAWSリージョンへDirect Connectを構築する。Direct Connectの障害に備え、バックアップとしてVPN接続を準備する。
B. プライベート接続のために安定的なネットワーク接続と低レイテンシーな2つのVPNトンネルを作成する。
C. サービスに組み込まれた自動フェイルオーバーとバックアップ回線を持つDirect Connectを構築する。
D. Direct Connectパートナーに依頼しAWSリージョンへDirect Connectを構築する。フェイルオーバーのために2つ目のDirect Connectを構築する
問題10
データセンターを持っているある企業は、できるだけ早くAWSへ移行したいと考えています。データセンターには、500MbpsのAWS Direct Connect接続と、完全に利用可能な独立した1GbpsのISP接続があります。ソリューションアーキテクトは、100TBのデータをデータセンターからAmazon S3バケットに転送する必要があります。データを転送する最も速い方法は何ですか?
A. Direct Connect接続を使いデータをS3バケットへアップロードする。
B. AWS Import/Exportサービスを使ってAWSへデータを送信する。
C. 複数のSnowballデバイスを使ってデータをアップロードする。
D. S3 transfer Accelerationを使ってS3バケットへデータを転送する。
問題11
ある会社がオンプレミス環境からAWSへのDirect Connect接続を構築しました。リンクアップしオンプレミス環境側からルートは広告されました。しかしVPCにあるEC2インスタンスからオンプレミス環境にあるサーバへ接続することができませんでした。次の選択肢のうち、この状況を解決できるものはどれですか。(2つ選択回答)
A. IPsec VPN接続をターゲットとしてルートテーブルへルートを追加する。
B. 仮想プライベートゲートウェイ(VGW)へのルート伝達を有効にする。
C. カスタマーゲートウェイ(CGW)へのルート伝達を有効にする。
D. routeコマンドを使ってすべてのインスタンスのルートテーブルを変更する。
E. インスタンスがあるVPCのサブネットのルートテーブルにオンプレミス環境への戻りの経路を追加する。
問題12
あなたは小さなスタートアップ企業のウェブサイトを構築しています。あなたはAWSにおける素晴らしいアーキテクチャであると考えているものを構築しており、この企業はそのことを評価しています。このサイトは画像収集サイトでCloudFrontを使って画像配信をします。ただし、クライアントは、CloudFrontのhttpsで動作するはずのこのコンテンツを提供するときにカスタムドメイン名が必要であると求めています。顧客の要求を達成するために何をする必要がありますか?以下のオプションから正しい答えを選択してください。
A. 独自のSSL証明書をRoute53でプロビジョン、設定し、CloudFrontディストリビューションに関連付ける
B. 独自のSSL証明書をIAMでプロビジョン、設定し、CloudFrontディストリビューションに関連付ける
C. ALIASレコードをRoute53でプロビジョン、設定し、CloudFrontディストリビューションに関連付ける
D. CloudFrontのためにOrigin Access Identity(OAI)を作成し画像が保存されているS3バケットのオブジェクトへのアクセス権を付与する
問題13
あなた組織は、レガシーシステムをAWSに迅速に移行し、ビジネスニーズに合わせて拡張できるように対応しています。既存のアプリケーションとそのコンポーネントの最適化は、これらの変更に対応する予算と時間がないため、対応できません。
ただし、これらのコンポーネントが移行された後、クラウドで適切に稼働されたら、システムをre-architectすることを計画しています。このシナリオで実行するのに最適な移行戦略は次のうちどれですか。
A. Rehost
B. Replatform
C. Repurchase
D. Refactor/Re-architect
問題14
お客様は、SSL対応のWebアプリケーションをAWSにデプロイしており、インスタンスのログインやAPIのコールができるEC2の管理者と、アプリケーションの秘密鍵を含むX.509証明書を管理するセキュリティ担当者のロールを分離したいと考えています。この要件を満たす構成オプションはどれですか?
A. ブートストラップでセキュリティ担当者が管理するCloudHSMから証明書を取得するようにWebサーバを設定する
B. セキュリティ担当者が所有するS3バケットに証明書をアップロードし、WebサーバのIAMロールによってのみアクセスできるようにする
C. 許可されたセキュリティ担当者のみに証明書へのアクセスを制限するために、Webサーバーのシステム権限を設定する
D. セキュリティ担当者のみに証明書保存先へのアクセスを許可するIAMポリシーを設定し、ELBでSSLを終端する
問題15
あるグローバル企業がミッションクリティカルなステートレスなアプリケーションをAWSへ移行したいと考えています。アプリケーションはz/OS上で動くIBM WebSphere(アプリケーションとインテグレーション用のミドルウェア)、IBM MQ(メッセージングミドルウェア)、DB2(データベースソフトウェア)から構成されています。ソリューションアーキテクトはAWS上にどうやってこのアプリケーションを移行しますか。
A. Auto Scalingを使ったELBの後ろのEC2インスタンスにWebSphereベースのアプリケーションをRe-hostする。IBM MQをEC2ベースのMQにRe-platformする。z/OS上のDB2はAmazon RDS DB2にRe-platformする。
B. Auto Scalingを使ったELBの後ろのEC2インスタンスにWebSphereベースのアプリケーションをRe-hostする。IBM MQをAmazon MQにRe-platformする。z/OS上のDB2をEC2ベースのDB2にRe-platformする。
C. アプリケーションをAWS Elastic Beanstalkを使いオーケストレートおよびデプロイする。IBM MQをAmazon SQSへRe-platformする。z/OS上のDB2をAmazon RDS DB2にRe-platformする。
D. AWS Server Migration Serviceを使いIBM WebSphereとIBM DB2をEC2ベースのソリューションへ移行する。IBM MQをAmazon MQにRe-platformする。
問題16
規制要件に対応するため、製薬会社は薬の治験実施後、データをアーカイブする必要があります。各治験は数千のファイルが作成され、圧縮後のファイルサイズは1~100MBほどです。いったんアーカイブされた後は、データはほとんどリストアされることはありません。リストアする必要があるときには、企業は条件に一致する特定のファイルをリストアするのに24時間の猶予があります。検索は数値によるファイルID、薬名、治験参加者名、データ範囲や他のメタデータによってできなければなりません。要件をみたすためにもっとも費用対効果が高いアーキテクチャはどれでしょうか。
A. 個々のファイルをファイルIDをアーカイブ名にしてGlacierに保存する。データをリストアするときに、検索条件に一致するファイルを見つけるためにGlacierに照会する。
B. 個々のファイルをS3に保存し、検索用のメタデータをマルチAZのRDSに保存する。一定期間経過後にGlacierにデータを移動させるためにライフサイクルルールを作成する。データをリストアするときに、検索条件に一致するファイルを見つけるためにRDSに照会し、対象のファイルをS3標準クラスに移動させる。
C. 個々のファイルをGlacierに保存し、検索用のメタデータをマルチAZのRDSに保存する。データをリストアするときに、検索条件に一致するファイルを見つけるためにRDSに照会し、DBから取得したファイルIDに一致するアーカイブファイル名を取得する。
D. 最初に、完了した1つの治験のすべてのファイルを圧縮した後に結合し、Glacierに1つのファイルでアーカイブする。通常のスナップショットを使用して、圧縮ファイルのバイトレンジを他の検索用メタデータとともにAmazon RDSデータベースに保存する。データをリストアするとき、検索条件に一致するファイルをデータベースに照会し、取得したバイトレンジからファイルをリストアする。
E. 個々の圧縮したファイルと検索用メタデータをS3に保存する。一定期間経過後にGlacierにデータを移動するライフサイクルルールを作成する。データをリストアしたいときに、検索条件に一致するファイルをS3バケットに照会し、S3標準クラスに戻すために低冗長化S3へファイルを取得する。
問題17
会社は人気のあるテレビ番組の投票システムを構築しており、視聴者は番組を見て、番組のウェブサイトにアクセスしてお気に入りの出演者に投票します。ショーの終了後、短期間でサイトに何百万人もの訪問者が訪れることが予想されます。訪問者は最初にAmazon.comの認証を使用してサイトにログインした後に投票します。投票が完了すると、ページに投票の合計が表示されます。
同社は、良好なパフォーマンスを維持しながらトラフィックの急速な流入を処理できるようにサイトを構築する必要がありますが、コストを最小限に抑えたいとも考えています。以下のどのデザインパターンを使用する必要がありますか?
A. CloudFrontとAuto ScalingするWebサーバを備えたELBを使用する。Webサーバは最初にLogin With Amazonサービスを使用しユーザを認証し、ユーザの投票処理を実行し、結果をマルチAZのRDSへ保管する。
B. CloudFrontとLogin With Amazonサービスを呼び出すJavascript JDKを設置したS3の静的Webホスティング機能を使い、ユーザを認証する。DynamoDBのテーブルへアクセスする権限をIAMロールから取得し、投票結果を格納する。
C. CloudFrontとAuto ScalingするWebサーバを備えたELBを使用する。Webサーバは最初にLogin With Amazonサービスを使用しユーザを認証し、ユーザの投票処理を実行し、アクセス権限をEC2インスタンスのIAMロールから取得し結果をDynamoDBのテーブルに格納する。
D. CloudFrontとAuto ScalingするWebサーバを備えたELBを使用する。Webサーバは最初にLogin With Amazonサービスを使用しユーザを認証し、ユーザの投票処理を実行し、アクセス権限をEC2インスタンスのIAMロールから取得し結果をSQSへキューイングする。複数のアプリケーションサーバがキューからデータを取得し集計結果をDynamoDBへ格納する。
問題18
ソリューションアーキテクトは、10個の既存のアカウントを持つマルチアカウント構造を設計しています。設計は、次の要件を満たしている必要があります。
・すべてのアカウントを1つのOrganizationに統合します。
・マスターアカウントとセカンダリアカウントからAmazon EC2サービスへのフルアクセスを許可します。
・セカンダリアカウントを追加するのに必要な労力を最小限に抑えます。
ソリューションは以下のどの手順の組み合わせ含めるべきでしょうか。(2つ選択してください)
A. マスターアカウントからOrganizationを作成する。マスターアカウントからセカンダリアカウントにinvitationを送付する。invitationを受領し、OUを作成する。
B. マスターアカウントからOrganizationを作成する。各セカンダリアカウントからマスターアカウントにjoin requestsを送付する。requestsを受領し、OUを作成する。
C. マスターアカウントとセカンダリアカウントの間でVPCピアリングコネクションを作成する。VPCピアリングコネクションのリクエストを受け入れる。
D. EC2のフルアクセスできるSCP(Service Control Policy)を作成し、OUにポリシーをアタッチする。
E. EC2のフルアクセスできるポリシーを作成し、ポリシーを各アカウントのロールにマッピングする。他のすべてのアカウントを信頼し、ロールを引き受ける。
問題19
あなたは、AWSの本番アカウントと開発アカウントを持つスタートアップ企業の管理者です。この時点まで、あなた以外の誰も本番アカウントにアクセスできませんでした。
開発アカウントには20人のユーザーがいますが、現在は本番アカウントでさまざまなレベルのアクセスを提供する必要があります。それらのうち10個は本番アカウントのすべてのリソースへの読み取り専用アクセスが必要で、5個はEC2リソースへの読み取り/書き込みアクセスが必要で、残りの5個はS3バケットへの読み取り専用アクセスのみが必要です。このタスクを達成するために、実務的およびセキュリティの観点から、次のオプションのどれが最良の方法でしょうか?(1つ選択してください)
A. 20のIAMユーザを開発アカウントから本番アカウントへコピーする。
B. アクセスが必要なリソースごとに暗号キーを作成し、必要なアクセスに応じてそれらのキーを各ユーザに提供する。
C. 本番アカウントに様々なレベルの必要な権限をつけた3つのユーザを新規に作成する。必要なアクセスレベルに応じて、20人のユーザごとに3つのアカウントのうち1つでログインするようにする。
D. 必要なアクセスレベルごとに違うポリシーをつけた本番アカウントの3つのロールを作成する。開発アカウントの各IAMユーザに権限を付与する。
問題20
ソフトウェア開発部門に本番、開発、およびテスト環境があり、各環境には他のAWSサービスとともに数十から数百のEC2インスタンスが含まれています。最近、UbuntuはOS上の重大な欠陥に対する一連のセキュリティパッチをリリースしました。これは緊急の問題ですが、これらのパッチにバグがなく、本番環境に対応できるという保証はまだないため、本番環境を除くすべての環境で、影響を受けるすべてのEC2インスタンスにすぐにパッチを適用する必要があります。本番環境のEC2インスタンスは、パッチが問題なく機能することを確認した後にのみパッチが適用されます。各環境には、満たす必要がある別のベースラインパッチ要件もあります。AWS Systems Managerサービスを使用して、最小限の労力でこのタスクをどのように実行する必要がありますか?
A. 環境とOSに応じて各インスタンスにタグを付ける。環境に応じたベースライン用のパッチを提供する複数のシェルを作成する。AWS Systems Manager Run Commandを使用し、EC2インスタンスをターゲットグループに設定し、各ターゲットグループに一致したスクリプトを実行する。
B. OSに応じて各インスタンスにタグを付ける。各環境ごとにAWS Systems Manager Patch Managerでパッチのベースラインを作成する。パッチグループを使い、タグをもとにEC2インスタンスをカテゴライズし、各パッチグループと一致したパッチベースラインのパッチを適用する。その後、Patch Complianceを使用して、パッチが正しくインストールされたことを確認する。 AWS Configを使用して、パッチと関連付けのコンプライアンス状態の変更を記録する。
C. 環境とOSに応じて各インスタンスにタグを付ける。Systems Manager Patch Managerで各環境のパッチベースラインを作成する。パッチグループを使い、タグにもとにEC2インスタンスをカテゴライズし、パッチベースラインと一致するパッチを各パッチグループに適用する。
D. 各環境のメンテナンス期間をAWS Systems Manager Maintenance Windowsで設定する。メンテナンス期間は日常業務に影響の内容に営業時間後に設定する。メンテナンス期間中にSystem Managerは各環境のEC2インスタンスに必要なパッチをインストールするcronジョブを実行する。その後、インスタンスを管理するSystem Managerで各環境がパッチがすべて適用され準拠していることを確認する。
問題21
企業は、フロントエンドとEコマース層を備えたEコマースプラットフォームを運営しています。両方の層はLAMPスタックで実行され、フロントエンドインスタンスは、AWSにも仮想的に提供しているロードバランサー機器の背後で実行されます。現在、運用チームはSSHを使用してインスタンスにログインし、パッチのメンテナンスや、その他の問題に対処しています。プラットフォームは最近、DDoS攻撃やSQLインジェクション攻撃を含む複数の攻撃の標的になっています。いくつかのWebサーバー上のSSHアカウントはディクショナリ攻撃は成功しています。
同社は、AWSに移行することで、Eコマースプラットフォームのセキュリティを改善したいと考えています。同社のソリューションアーキテクトは、次のアプローチを使用することを決定しました。
・既存のアプリケーションをコードレビューし、SQLインジェクションの問題の修正
・ウェブアプリケーションをAWSに移行し、最初からセキュリティパッチに対応した最新のAWS Linux AMIの活用
・AWS Systems Managerをインストールしてパッチを管理し、必要に応じてシステム管理者がすべてのインスタンスでコマンドを実行できるようにすること
高可用性を提供し、リスクを最小限に抑えながら、他のすべての同一の攻撃タイプに対処する追加の手順は何ですか?
A. 特定のIPからのSSHアクセスだけに制限するようにセキュリティグループを設定する。オンプレミスのMySQLをマルチAZのRDSへ移行する。AWSマーケットプレイスからサードパーティ製のロードバランサをインストールし、既存のルールをロードバランサに移行する。DDoS攻撃から保護するためAWS Shield Standardを有効にする。
B. EC2インスタンスへのSSHを無効にする。オンプレミスのMySQLをマルチAZのRDSへ移行する。負荷分散のためELBを活用しAWS Shield Advancedを有効にする。Amazon CloudFrontをWEBサイトの前段に追加する。ディストリビューションのAWS WAFを有効にしルールを設定する。
C. 特定のIPからのアクセスに制限した踏み台サーバからEC2インスタンスへSSHできるようにする。オンプレミスのMySQLをセルフマネージドEC2インスタンスへ移行する。負荷分散のためELBを活用しDDoS攻撃から保護するためにAWS Shield Standardを有効にする。Amazon CloudFrontをWEBサイトの前段に追加する。
D. EC2インスタンスへのSSHアクセスを無効にする。オンプレミスのMySQLをシングルAZのRDSへ移行する。負荷分散のためELBを活用する。CloudFrontをWEBサイトの前段に追加する。ディストリビューションのAWS WAFを有効にしルールを設定する。
問題22
会社には、オンプレミスに3層のWEBアプリケーションがあります。 Linux Webサーバーは、NASサーバー上に一元管理した共有ファイルを使いコンテンツを提供します。これは、コンテンツがさまざまな経路で1日に数回更新されるためです。既存のインフラストラクチャは最適化されておらず、負荷に応じてリソースをスケールアップおよびスケールダウンできるように、AWSに移行したいと考えています。オンプレミスとAWSリソースは、AWS Direct Connectを使用して接続されます。
会社は、コンテンツを更新し配信するプロセスを遅らせずに、ウェブインフラストラクチャをAWSにどのように移行できますか?
A. AWSのCLBの配下にEC2インスタンスの冗長構成をとります。コンテンツ用にEBSを使い、これらすべてのEC2インスタンスで共有します。このボリュームとNASで同期するようにジョブを設定します。
B. NASサーバのリプレイスのためにStorage Gatewayを使ってオンプレミスのファイルゲートウェイを作成し、AWSへコンテンツを複製する。AWS側では、同じStorage GatewayのバケットをWEBサーバのEC2インスタンスにマウントしコンテンツを提供する。
C. オンプレミス側にAmazon EFS共有を公開して、NASサーバーとして機能します。同じEFS共有をWebサーバーのEC2インスタンスにマウントして、コンテンツを提供します。
D. AWSでAuto ScalingグループとしてWEBサーバのEC2インスタンスを作成する。NASサーバからWEBサーバへコンテンツをアップデートする夜間プロセスを設定する。
問題23
開発チームは、サービスのデプロイに役立つ一連のAWS CloudFormationテンプレートを作成しました。
ネットワーク/VPCスタック、データベーススタック、踏み台ホストスタック、およびWebアプリケーション固有のスタック用のテンプレートを作成しました。各サービスは、少なくともネットワーク/VPCスタック、踏み台ホストスタック、Webアプリケーションスタックのデプロイが必要で、各テンプレートには複数の入力パラメーターがあるため、AWS CloudFormationコンソールからサービスを個別にデプロイすることが難しいです。
1つのスタックの入力パラメーターは通常、他のスタックの出力になります。たとえば、ネットワークスタックのVPC ID、サブネットID、およびセキュリティグループは、アプリケーションスタックまたはデータベーススタックで使用します。運用負荷とサービスのデプロイに渡されるパラメーターの数を減らすのに役立つアクションはどれですか?(2つ選択してください。)
A. 各サービス用の新しいCloudFormationテンプレートを作成する。各テンプレートに渡される多くのパラメータを削減するため、既存のテンプレートをクロススタック参照を使うように変更する。アプリケーションに必要な各スタックを新しいスタックからネストされたスタックとして呼び出す。AWS CloudFormationコンソールから新しく作成したサービススタックを呼び出し、以前必要だったパラメーターのサブセットを使い特定のサービスをデプロイする。
B. 各サービスの新しいポートフォリをService Catalogで作成する。サービスの構築に必要な既存のAWS CloudFormationテンプレートごとに製品を作成しする。Service Catalogで、そのサービス用のポートフォリオに製品を追加する。サービスをデプロイするために、特定のサービスポートフォリオを選択し、必要なパラメータを入力しポートフォリオを起動しすべてのテンプレートをデプロイする。
C. 各サービス用にCodePipelineワークフローを設定する。各既存のテンプレート用にデプロイアクションとしてCloudFormationを選択する。依存関係が確実に順守されるようにデプロイアクションが処理されるようにする。スタック間のパラメータを共有するために設定ファイルとスクリプトを使用する。サービスを起動するために、サービス名を選択して変更をリリースすることにより、特定のテンプレートを実行する。
D. AWS Step Functionsを使用して新サービスを定義する。各サービス用に新しいCloudFormationを作成する。各テンプレートに渡される多くのパラメータを削減するため、既存のテンプレートをクロススタック参照を使うように変更する。アプリケーションに必要な各スタックを新しいスタックからネストされたスタックとして呼び出す。サービス用テンプレートを直接呼び出すようにStep Functionsを設定する。Step Functionsコンソールでステップを実行する。
E. 各サービスの新しいポートフォリをService Catalogで作成する。各サービスのCloudFormationの新しいテンプレートを作成する。各テンプレートに渡される多くのパラメータを削減するため、既存のテンプレートをクロススタック参照を使うように変更する。各アプリケーションの製品を作成する。サービスのテンプレートを製品に追加し、各製品をポートフォリオに追加する。サービスを構築するのに必要なパラメータだけを使いポートフォリオから製品をデプロイする。
問題24
WEB-AP層とデータベース層からなる読み取り専用のニュースレポートサイトは、予測不能な大規模なトラフィックを受信するため、これらのトラフィックの変動に自動的に対応できる必要があります。これらの要件を満たすためにどのAWSサービスを使用する必要がありますか?
A. CloudWatchでモニターしたAuto Scalingグループに設定されたステートレスなインスタンスをWEB-AP層に使用する。WEB-AP層はElastiCache Memcachedを使って同期させる。RDSにリードレプリカを設定する。
B. CloudWatchでモニターしたAuto Scalingグループに設定されたステートフルなインスタンスをWEB-AP層に使用する。RDSにリードレプリカを設定する。
C. CloudWatchでモニターしたAuto Scalingグループに設定されたステートフルなインスタンスをWEB-AP層に使用する。マルチAZのRDSを使用する。
D. CloudWatchでモニターしたAuto Scalingグループに設定されたステートレスなインスタンスをWEB-AP層に使用する。WEB-AP層はElastiCache Memcachedを使って同期させる。マルチAZのRDS使用する。
問題25
ALB配下のEC2インスタンスでWEBアプリケーションが2つのAZにまたがりAuto Scalingグループで稼働しています。ロードバランサーはパブリックサブネットに、EC2インスタンスはプライベートサブネットに配置されています。それぞれのセキュリティグループがロードバランサーとEC2インスタンスに関連づいています。アプリケーションはプライベート仮想インターフェースを使った1Gbps AWS Direct Connectを経由してオンプレミスのデータセンターにあるデータベースからデータを読み込みます。そのデータセンターにある複数のアプリケーションもそのデータベースを参照します。アーキテクチャを改善する変更はどれでしょうか。
A. プライベート仮想インターフェースをパブリック仮想インターフェースに置き換える。
B. アプリケーションからオンプレミスのデータベースに接続する新しいAWS Lambdaファンクションを呼び出す。
C. データセンターとVPCにある仮想プライベートゲートウェイの間にVPN接続を追加する。
D. オンプレミスのデータベースをVPCのEC2インスタンスに移行する。
問題26
ある企業が開発チームごとにアカウントを作成し、合計200アカウントになりました。すべてのアカウントには、1つのリージョンに1つのVPCがあり、複数のマイクロサービスがあります。マイクロサービスはDockerコンテナで実行されており、他のアカウントのマイクロサービスと通信する必要があります。セキュリティチームの要件では、これらのマイクロサービスはパブリックなインターネットを通過してはならず、特定のインターナルなサービスのみが他の個々のサービスを呼び出すことを許可されている必要があります。
サービスに対して拒否されたネットワークトラフィックがある場合、送信元IPを含む拒否されたリクエストの内容をセキュリティチームに通知する必要があります。セキュリティ要件を満たしながらサービス間で接続を確立するにはどうすればよいですか?
A. VPC間でVPCピアリングを作成する。マイクロサービスを呼び出す許可されているセキュリティグループIDからのトラフィックを許可するようにインスタンスのセキュリティグループを設定する。ネットワークACLを適用しローカルVPCとピアリングしているVPCのトラフィックのみを許可する。各マイクロサービスのAmazon ECSのタスク定義で、awslogsドライバーを使ったログの設定する。CloudWatch Logsで、メトリックのフィルターを作成し、HTTP403のレスポンスの数によるアラームをオフにする。メッセージ数がセキュリティチームによって設定された閾値を超過したときのアラームを作成する。
B. CIDRのレンジが重複していないことを確認し、VGWを各VPCにアタッチする。各VGW間でIPsecのトンネルを構築し、ルートテーブルのルート伝播を有効にする。他のアカウントのVPCのCIDRレンジを許可するようにセキュリティグループを設定する。VPCフローログを有効にして、拒否したトラフィックについてはCloudWatch Logsのサブスクリプションフィルターを使用して確認する。IAMロールを作成し、各アカウントのAssumeRoleを呼び出す権限をセキュリティチームに付与する。
C. AWS EC2で動作しているサードパーティのマーケットプレイスのVPNアプライアンスを使用してトランジットVPCをデプロイする。これによりVPNアプライアンスと、リージョン内の各VPCに接続されたVGWの間のVPN接続を動的にルーティングする。ネットワークACLを適用しローカルVPCからのみトラフィックを許可する。マイクロサービスにセキュリティグループを適用し、VPNアプライアンスのトラフィックのみ許可する。各VPNアプライアンスにawslogsエージェントをインストールし、セキュリティチームがアクセスできるアカウントのCloudWatch Logsへログを転送するように設定する。
D. 各マイクロサービス用にNLBを作成する。NLBをPrivateLinkエンドポイントサービスにアタッチし、このサービスを使用するアカウントをホワイトリストに追加する。サービス利用者側のVPCにインターフェースエンドポイントを作成し、これにサービスを呼び出す権限のあるセキュリティグループを関連付ける。サービス提供側で、各マイクロサービスのセキュリティグループを作成し、特定のCIDRのレンジのみにサービスを許可するようにする。拒否されたトラフィックをCloudWatch Logsグループへ転送し、キャプチャするために、各VPCでVPCフローログを作成する。セキュリティチーム用アカウントでログデータをストリーミングできるようにCloudWatch Logsサブスクリプションを作成する。
問題27
AWS環境のコストをレビューするように求められました。この環境には、手動で管理されるリソースと、CloudFormation、OpsWorks、Elastic Beanstalkによって作成されたリソース、およびさまざまなLambda関数が混在しています。稼働中のリソースに影響を与えずに組織のコストを節約するには、次のうちどれを削除する必要がありますか?(2つ選択してください)
A. CloudFormationのスタックを削除する。これらはリソースが作成された後は使われない。
B. 未使用のElastic IP
C. 稼働していないAuto Scalingグループと起動テンプレートの削除
D. これ以上使われないことを確認した後、稼働中のインスタンスにアタッチしていないEBSボリュームを削除
問題28
ある組織は2つのEC2インスタンスを保有しています。1つ目は注文アプリケーションと在庫アプリケーションが稼働しています。2つ目はキューイングシステムが稼働しています。1年の特定の期間に、1秒間に数千の注文が発生します。キューイングシステムが停止したときにいくつかの注文が消えてしまいました。また、一部の注文が2度処理されたため、在庫アプリケーションで管理している商品の数が正しくありません。注文数の増加に対応するため何をするべきでしょうか。
A. 注文と在庫アプリケーションをAWS Lambda関数に配置する。注文アプリケーションはSQS FIFOキューにメッセージを入れるようにする。
B. 注文と在庫アプリケーションをECSコンテナに配置し、各アプリケーション用にAuto Scalingグループを作成する。それからマルチAZにメッセージキュー用サーバを構築する。
C. 注文と在庫アプリケーションをEC2インスタンスに配置し、各アプリケーション用にAuto Scalingグループを作成する。受注用にAmazon SQS標準キューを使用し、在庫アプリケーションに冪等性を実装する。
D. 注文と在庫アプリケーションをEC2インスタンスに配置する。受注内容をAmazon Kinesis Data Streamsに出力する。ストリームをポーリングするLambdaを作成し、在庫アプリケーションを更新する。
問題29
ある企業はユーザがレストランの評価をすることができるインタラクティブなWEBサイトの移行をサポートするため、あなたを雇いました。評価を更新するとWEBサイトで見ることができ、リアルタイムで反映されます。現在はまだあまり人気のないサイトですが、企業はあと数週間で急速に成長すると予想しています。企業はこのWEBサイトを高可用性な構成にしたいと考えています。現在のアーキテクチャは単一のWindowsサーバ2008 R2のWEBサーバとLinuxで稼働するMySQLデータベースで構成されています。両方ともオンプレミスのハイパーバイザ内にあります。パフォーマンスと高可用性を確保しつつアプリケーションをAWSへ移行するのにもっとも効率的な方法はどれですか?
A. WEBのファイルをus-west-1のS3バケットへ出力する。直接S3からWEBサイトをホスティングする。us-west-1aにマルチAZのMySQLのRDSを起動します。最新のMySQLのバックアップからRDSへデータをインポートする。Route53を使いELBのエイリアスレコードを作成する。
B. Windowsサーバ2008 R2のインスタンスをus-west-1bに2つ、us-west-1aに2つ起動する。オンプレミスのWEBサーバからWEBのファイルを各EC2のWEBサーバにコピーしS3をリポジトリとして使用する。マルチAZのMySQLのRDSをus-west-1aに起動する。最新のMySQLのバックアップからRDSへデータをインポートする。WEBサーバの前にELBを作成する。Route53を使用しELBのエイリアスレコードを作成する。
C. AWS VM Import/Exportを使用しWEBサーバのEC2 AMIを作成する。2つのWEBサーバをus-west-1aとus-west-1bで起動するようにAuto Scalingを設定する。マルチAZ MySQLのRDSをus-west-1bに起動する。最新のMySQLのバックアップからRDSへデータをインポートする。Route53を使用し、ホストゾーンとELBに対するAレコードを作成する。
D. VM Import/Exportを使用しWEBサーバのEC2 AMIを作成する。2つのWEBサーバをus-west-1aとus-west-1bで起動するようにAuto Scalingを設定する。マルチAZ MySQLのRDSをus-west-1aに起動する。最新のMySQLのバックアップからRDSへデータをインポートする。WEBサーバの前にELBを作成する。Route53を使用しELBに対するAレコードを作成する。
問題30
ソリューションアーキテクトはモバイル端末のプラットフォームで動く世界的に人気のあるゲームのための高可用性なインフラを構築する必要があります。アプリケーションはALB配下のEC2インスタンスで動いています。インスタンスはマルチAZ構成のオートスケーリンググループで動いています。DB層はマルチAZのMySQLのRDSです。アプリケーション全体はus-east-1とeu-central-1リージョンでデプロイされています。Route53はレイテンシーベースルーティングポリシーでトラフィックを2つのリージョンへトラフィックをルーティングするのに使われています。片方のリージョンが停止した場合に備え別のリージョンへフェイルオーバするようにRoute53には重み付けルーティングポリシーが設定されています。DRシナリオのテストの間、ec-central-1リージョンで動いているすべてのアプリケーションRDSへのアクセスをブロックしてから、Route53はすべてのトラフィックをus-east-1へ
自動的にフェイルオーバーしませんでした。どう変更したらus-east-1へフェイルオーバーするようになるでしょうか。(2つ選択してください)
A. us-east-1のALBへの加重レコードを100に、eu-central-1のALBへの加重レコードを60に設定する。
B. us-east-1のALBへの加重レコードを100に、eu-central-1のALBへの加重レコードを0に設定する。
C. レイテンシーエイリアスレコードのリソースのEvaluate Target Healthを両方のリージョンでyesに設定する。
D. DB層のヘルスチェックをするようにアプリケーションにURLを書く。
E. ポリシーのリソースに対するヘルスチェックの設定をすべて無効にし、両方のリージョンへの加重レコードを0に設定する。正常なリソースのリージョンのALBだけ加重レコードを100に設定する。
問題1回答
EBSボリュームは利用可能になるとすぐに最大のパフォーマンスを発揮しますが、スナップショットから作成された場合は、EBSボリュームはストレージブロックがS3からプルダウンされないとアクセス可能になりません。そのため、テスト前にすべてのブロックを読み込む初期化(事前ウォーミング)をします。
参考URL:Amazon EBS ボリュームの初期化
回答:B
問題2回答
リザーブドインスタンスもスポットインスタンスもオンデマンドインスタンスより割安で購入することができますが、それぞれ制約があります。
リザーブドインスタンスは1年か3年の契約になり、支払いも全額前払い、一部前払い、前払いなし、となっており3年契約の全額前払いが一番安いです。
スポットインスタンスは変動するEC2インスタンス価格に対し、入札価格を決め、EC2インスタンス価格が入札価格を下回ると購入できることができます。逆に入札価格がEC2インスタンス価格を下回るとEC2インスタンスが削除されてしまいます。そのため万が一止まってしまっても再実行が可能なシステムに向いています。
この問題では、WEB層とAP層は6ヶ月以内にサーバレスのAPI GatewayとLambdaへ移行するとあるので、ここでは最低でも1年契約となるリザーブドインスタンスは使えません。また、スポットインスタンスについても安定的にEC2インスタンスを使うことができないため不適切です。
DB層はAPI GatewayとLambda導入後も同じインスタンスを使い続けるので、リザーブドインスタンスにします。よってこれらの組み合わせであるBが正解です。
回答:B
問題3回答
外部で認証されたユーザーに対し、AWSのアクセスを許可することをIDフェデレーションといいます。代表的なIDフェデレーションの仕組みとしてSAML2.0がありますが、この設問ではSAMLについての記載がないためカスタムIDブローカーアプリケーションを作成してIDフェデレーションします。
大まかな処理の流れは以下のとおりです。
1. ユーザーはIDブローカーを経由してLDAPサーバで認証する
2. 認証後、IDブローカーはそのユーザー用に一時的な認証情報を取得するためにIAM STSをコールする
3. STSはあらかじめS3へアクセスできるポリシーを設定しておいた一時的な認証情報を払い出す
4. ユーザーは一時的な認証情報を使ってS3へアクセスする
図については参考URLをご参照ください。
よって、カスタムIDブローカーを作成するBと、アプリケーション自身でカスタムIDブローカーになるCが正解です。
AとEはLDAPに対し認証していないので誤りです。LDAPの認証情報を使ってIAMにログインするわけではないのでDも誤りです。フェデレーション関連の問題はややこしくて難しいですね。
回答:B、C
参考URL:カスタム ID ブローカーアプリケーションを作成するユーザーのフェデレーション
問題4回答
ユーザーの保有しているファイルのメタデータおよび合計ファイルサイズなどを管理するデータストアが必要で、DynamoDBは拡張性の観点よりこの要件にマッチしています。ユーザーがファイルを保存する処理をワークフロー化し、その中でDynamoDBのユーザー情報の合計ファイルサイズ(カウンター)を更新するアクティビティワーカーや、カウンターが閾値を超えたときにメールを送信するアクティビティワーカーを作成することで実現できるAが正解です。
B:数十億のファイルがあるということで、これらをRDSで管理するのは拡張性から望ましくなく、クエリのパフォーマンスの観点でも不適切です。
C:S3のオブジェクトにはkey-value形式のメタデータを設定することができます。メタデータはシステムメタデータとユーザ定義メタデータがありますが、メタデータをCLIなどで検索することができないですし、SQSから直接メールを送信できないため誤りです。
D:バケットに対し、集計処理を毎回実施するのは現実的ではありません。
回答:A
問題5回答
RTO15分、RPO数時間ということで、素早くリカバリできることが重要になります。必要なファイルのみ復元でき、この中では一番シンプルに復元が可能なCが正解です。
A:S3からファイルを復元するのは手間がかかりますし、ファイルサイズやファイル数に依存します。
B:アプリケーションの切り替えが発生するのでこちらも復旧時間がかかります。もともとあったボリュームを削除するのも適切ではないでしょう。
D:スナップショットはボリュームを作成するもので、EC2インスタンスの復元はできません。
回答:C
問題6回答
Route53でよく出るルーティング3種(レイテンシー、重み付け、フェイルオーバー)が出題されています。この問題の要件では両方のリージョンで同時にアクティブにする、とあるのでActive-Activeなフェイルオーバーにする必要があります。この場合にはフェイルオーバールーティングは使わず、レイテンシーか重み付けを使用します。また、エンドユーザーには最小のレイテンシーでアクセスできるようにする、とあるので、Cのレイテンシーベースルーティングが正解です。なお、この問題では問われていませんが、ヘルスチェックの結果を使いフェイルオーバーさせる場合には、「Evaluate Target Health」をYesに設定します。これによりルーティングする前に対象リージョンに正常なリソースがあるかどうかを判断します。
また、片方のリージョンのDBは読み取り専用のリードレプリカなので、DB障害時には1時間以内に更新可能なソースDBに昇格させる必要があります。RDSのイベント通知を使用しリードレプリカをソースDBへ昇格させる処理を実行すればよいのでDも正解です。
A:フェイルオーバールーティングはActive-Passiveで使用するので不適切です。
B:加重ルーティングでは最小のレイテンシーでのアクセスを実現できないので不適切です。
D:DB障害以外の障害でもヘルスチェックが異常になります。ソースDBがアクセス可能な状態でリードレプリカを昇格させる必要はありません。
回答:C、E
問題7回答
クラスタープレイスメントグループの説明です。
クラスタープレイスメントグループは、単一のアベイラビリティーゾーン内のインスタンスを論理的にグループ化したものです。プレイスメントグループは、同じリージョン内のピア VPC にまたがることができます。
(中略)
低ネットワークレイテンシー、高ネットワークスループット、またはその両方から利点が得られるアプリケーションや、ネットワークトラフィックの大部分がグループのインスタンス間で発生する場合は、クラスタープレイスメントグループが推奨されます。
プレイスメントグループ内に十分なリソースがない場合、インスタンスの起動に失敗することがあります。起動しているプレイスメントグループ内のインスタンスを停止した後、再度、起動することでプレイスメントグループが十分なリソースのあるハードウェアに移行される場合があります。
よって正解はAです。
回答:A
問題8回答
問題3と同じで、あらかじめロールを作成しておきます。ADやLDAPで認証した後にフェデレーションプロキシーやIDプロバイダーがIAM STSからロールの一時的な認証情報を取得します。その認証情報を使ってS3へアクセスします。正解はA、B、Dです。
C:バケットにタグを設定してもSSOには役に立ちません。
E:ADやLDAPを使ってSSOをする、とあるので、すべての従業員のIAMユーザを作成するのは不適切です。
回答:A、B、D
問題9回答
Direct Connectは低レイテンシーで高い安定性のトラフィックを提供する反面、費用は安くありません。一方インターネット上のIPsecVPNは費用は安いのですが、レイテンシーの問題や安定性の保証がありません。この問題では、通常時にはAWSとの通信は低レイテンシーで高い安定性を求めつつ、障害発生時にはそれらを担保する必要がなく、かつ、コストは抑えたいとあります。ですので、通常用にDirect Connect、バックアップ回線としてVPN接続を用いたAが正解です。なお、Direct ConnectとVPNは同じVGWを使ってオンプレミス環境へつなぐことで、通常時はDirect Connectが優先的に使われます。
参考URL:AWS Direct Connect 接続のバックアップとして VPN 設定する
回答:A
問題10回答
1Gbpsの回線でも100TBのデータを転送するのに10日以上かかります。ここではSnowballを使って転送するのが最適です。Snowballはマネジメントコンソールでジョブを設定すると、データセンターにデバイスが送付されデータを入力後AWSへ返送すると、S3にデータがアップロードされるサービスです。他にもSnowball Edge、Snowmobileという上位サービスもあります。
AWS Snowファミリー
A:Direct Connectを使用すると最低でも20日以上かかります。
B:Import/ExportサービスはSnowballの前身のサービスになり、Snowballを使用するほうがより高速で安価のため推奨されています。また、16TiBまでしかサポートされていないため不適切です。
D:S3 Transfer AccelerationはCloudFrontのエッジロケーションを使った、S3へデータを転送するサービスです。エッジロケーションに到着したデータは、最適化されたネットワークパスで S3 にルーティングされます。ですが、エッジロケーションまでは1Gbpsの回線を使う必要があるので10日以上かかるため不適切です。
回答:C
問題11回答
VPCの通信のトラブルシューティングでは、ルートテーブル、セキュリティグループ、ネットワークACLが問われます。オンプレミスとVPCの通信では、オンプレミス側のルーティングが頻繁に変わる場合にはVGWで受け取ったルート情報をVPC側のルートテーブルへ反映する必要があります。そのための設定がVGWのルート伝達(propagation)になります(B)。
インスタンスがあるサブネットからオンプレミス環境へのルートテーブルの設定も確認する必要があるのでEも正解です。
参考URL:VPCのルートテーブルの問題をトラブルシューティングする
A:この問題ではDirect Connectを扱っており、VPN接続ではありません。
C:CGWはオンプレミス環境側のエンドポイントのため、ルート伝達はCGWではなくVGWで設定します。
D:ここではOSのrouteコマンドは使用しません。
回答:B、E
問題12回答
CloudFrontはcloudfront.netドメインのSSL証明書は標準で利用可能ですが、カスタムドメインが必要な場合には、AWS Certificate Manager(ACM)から取得したSSL証明書か、インポートした証明書を使うことができます。インポート先ですが、AWSの推奨はACMですが、ACMでサポートしていないアルゴリズムやキーサイズの場合にはIAMへインポートします。よってBが正解です。
A:Route53で管理しているドメインのSSL証明書をACMで管理することはできますが、Route53でSSL証明書を設定することはできません。
C:ALIASレコードはELBやCloudFrontのURLの別名をつけるときに、Route53で設定するレコードです。SSL証明書とは関係がないため誤りです。
D:OAIは直接S3へアクセスできないようにするときに使う機能で、SSL証明書とは関係がありません。
回答:B
問題13回答
これは知識問題でクラウド移行における6つのRといいます。設問では、できるだけ時間をかけずに、AWSへ移行し適切に稼働してからRe-architectするとあるため、まずは既存のサーバーをそのままEC2インスタンスへマイグレーションを意味するRehostする必要があります。よって正解はAです。なお、6つの戦略は以下の通りです。

参考URL:ベストプラクティスと戦略
回答:A
問題14回答
EC2の管理者はEC2でSSLを終端している場合に、証明書にアクセスできることになります。ELBでSSLを終端すれば、ELBとEC2インスタンスの間の通信はHTTPになり、EC2が証明書へアクセスする必要がなくなるので、管理者が証明書にアクセスすることはできなくなります。
回答:D
問題15回答
これは消去法的にBになります。IBM製品を触ったことがないと、問題を見たときにギョッとしてしまいますが、RDSがDB2をサポートしていないということだけ覚えておけば答えは導き出せそうですね。
A:RDSはDB2をサポートしていません。
C:Aと同様RDSはDB2をサポートしていないです。
D:Server Migration Service(SMS)はDB2をサポートしていないです。SMSはオンプレミスのVMをAMIに変換しEC2インスタンスへ移行するように使用します。DBのデータの移行はDatabase Migration Serviceを使用します。一応DMSでDB2 LUW(LUWってなんだ・・・)をソースとしたマイグレーションもサポートしているようです。
回答:B
問題16回答
「一度アーカイブした後データがリストアされるケースは少ない」、「リストアするまでに時間的猶予がある」、「コストが安い」、といった時にはGlacierに保管することを検討します(この問題は全部Glacier使っていますが)。この設問では、Glacierに保存されているデータを検索する方法も問われています。
治験のメタデータをRDSで管理することで、各データを柔軟に管理することができ、検索も容易になります。また、Glacierの取り出し時にアーカイブの取得範囲を設定できるので、ファイルのバイトレンジをRDSで管理することで、必要なファイルのみを取り出すことができ、不要なファイルの取り出しに伴う料金を払う必要がなくなります。
A:Glacier Selectという機能で検索をすることはできますが、データは非圧縮のCSV形式である必要があります。
B:治験終了後、データはアーカイブをすると記載されているので、一定期間S3に保存せずにすぐにGlacierにアーカイブする必要があります。
C:マルチAZ構成のRDSでは、要件に対しコストが見合いません。
E:Bと同様S3はアーカイブに使う分には割高です。
回答:D
問題17回答
この設問の選択肢では、フロントサイドに大きな違いはなく、DBサイドのアーキテクチャに違いがあります。DynamoDBの前段にSQSを置くことで、DynamoDBのスループットを減らすことができ、コストを抑えることができます。
A:RDSは必要なパフォーマンスを出すにはコストがかかります。
B:アプリケーションから直接DynamoDBへ投票結果を書き込むには、高いキャパシティユニットを設定する必要があり、高いコストが発生します。Javascript SDKでWEB認証を使うことはできます。
C:Bと同様にDynamoDBが必要なパフォーマンスを出すためには、高いコストが発生します。
回答:D
問題18回答
この設問はAWS Organizationsの概念の理解、基本的な設定方法について問われています。
Organizationsにはすべての機能と一括請求機能という2つの機能セットがあります。すべての機能を有効にしているとSCP(Service Control Policy)やタグポリシーなどの高度な管理機能が使えます。
マスターアカウントでOrganizationを作成した後に、既存のセカンダリアカウントをOrganizationに含めるにはinvitationを送付し、セカンダリアカウント側でinvitaionを受諾します。OU(組織単位)を作成しセカンダリアカウントをそのOUに含めます。OUごとにSCPと呼ばれる権限ポリシーを適用することができ、SCPで設定した権限はOUに含めたルートアカウント、IAMユーザ、ロールに適用されます。この権限はAWSサービスやリソース、APIの利用などに関するものです。また、セカンダリアカウント側のIAMポリシーでサービス利用などを許可してもSCPで拒否していればSCPの拒否が有効(強い)になります。
よって正解はAとDです。
回答:A、D
問題19回答
あるアカウントのIAMエンティティ(ユーザ、グループ、ロール)が違うアカウントのリソースを操作するためには、クロスアカウントアクセスという機能を使用します。ここでは、開発アカウント(IAMユーザ)が本番アカウントのリソースを操作するのにクロスアカウントアクセスを使用します。クロスアカウントアクセスは本番アカウントでロールを作成し、開発アカウントのマネジメントコンソールでスイッチロールをすることで切り替えることができます。用途に応じて3つのロールを作成し開発アカウントの各IAMユーザに権限を付与すれば良いので正解はDです。
なお、スイッチロールはSTSのAssumeRoleを呼び出して実現しております。
A:20のアカウントを本番アカウントに作成するのは管理上手間がかかります。
B:暗号キーを提供しても別アカウントのリソースにアクセスはできません。
C:3つのユーザはシェアすることになるので、セキュリティの観点からよくありません。
回答:D
問題20回答
Systems ManagerのPatch Managerに関する問題です。Patch Managerでは、パッチベースラインとパッチ適用の設定があります。
パッチベースラインはOSの種類ごとにあり、どの重要度(Critical、Importantなど)のパッチをパッチのリリースから何日後に適用するか、というルールを決めます。また、パッチベースラインではそのパッチベースラインに紐づくパッチグループを設定することもできます。インスタンスに「Patch Group」というタグキーのタグをつけることで、パッチグループとインスタンスを紐づけることができます。
パッチ適用の設定はスケジュールと対象のインスタンスを決めます。対象のインスタンスはインスタンスにつけたタグやパッチグループを選択することができます。タグの場合は、タグが付いたインスタンスのOSの種類に従い、そのOS用のパッチベースラインが適用され、パッチグループの場合には、パッチグループに紐づいたパッチベースラインが適用されます。
この内容に一致した選択肢はCになります。
A:シェルの作成や、Run Commandを使う手間が発生するため不適切です。
B:先に本番環境以外にパッチを当ててから本番環境へ適用する、とあるのでタグ付けはOSタイプのみでなく、環境についてもタグ付けをする必要があります。
D:AWS Systems Manager Maintenance Windowsを使用して、パッチをあてることはできますが、設定や実装に多くの手間が発生します。
回答:C
問題21回答
設問にはSystems Managerでパッチの適用やコマンド実行をする方針にする、と記載があるのでEC2インスタンスのSSHは無効にします。マルチAZのRDSは高可用性につながります。また、AWS Shield Advancedを使ったELBの前段に、WAFを有効にしたCloudFrontディストリビューションを配置することはDDoS対策になります。
A:AWS Shieldはサードパーティ製のロードバランサをサポートしていないです。
C:セルフマネージドMySQLは高可用性ではありません。
D:シングルAZのRDSは高可用性ではありません。
回答:B
問題22回答
Amazon EFSはNASサーバとしてオンプレミス環境へ展開することができます。同じEFSをEC2インスタンスのWEBサーバでマウントしコンテンツを配信します。
以下はAmazon EFSの説明になります。
Amazon Elastic File System (Amazon EFS) は、AWS クラウドサービスおよびオンプレミスリソースで使用するための、シンプルでスケーラブル、かつ伸縮自在な完全マネージド型の NFS ファイルシステムを提供します。アプリケーションを中断することなくペタバイト規模にオンデマンドでスケールするよう設計されており、ファイルの追加および削除に合わせて自動で拡大および縮小されるため、拡張に合わせて容量をプロビジョニングおよび管理する必要がなくなります。Amazon Elastic File System (Amazon EFS) は、AWS クラウドサービスおよびオンプレミスリソースで使用するための、シンプルでスケーラブル、かつ伸縮自在な完全マネージド型の NFS ファイルシステムを提供します。アプリケーションを中断することなくペタバイト規模にオンデマンドでスケールするよう設計されており、ファイルの追加および削除に合わせて自動で拡大および縮小されるため、拡張に合わせて容量をプロビジョニングおよび管理する必要がなくなります。
A:EBSはEC2インスタンス間で共有することはできません。
B:Storage Gatewayはオンプレミス側にもストレージが必要になります。オンプレミスのストレージは負荷に応じて動的にスケールしないため要件に合いません。
D:コンテンツは1日に数回更新され、コンテンツはリアルタイムに配信したいため不適切です。なお、Auto Scalingで新しいEC2インスタンスが起動するタイミングでもコンテンツを取得する必要があります。
回答:C
問題23回答
CloudFormationでスタック間でパラメータを渡すことができ、これをクロススタック参照と呼びます。例えば、VPC作成用テンプレートでスタックを作成した後にEC2インスタンス作成用テンプレートでスタックを作成するケースでは、VPCスタックを作成するとVPC IDが決まり、これをEC2インスタンス作成用テンプレートに変数(スロススタック参照)として使用することができます。
Step Functionsを使用してテンプレートからスタックを作成することができます。
Service Catalogは開発チームのアジリティを持たせつつ、ガバナンスも確保するサービスになります。Service Catalogの製品は1つ以上のリソース(EC2インスタンスなど)を含むCloudFormationテンプレートをパッケージ化したものです。ポートフォリオは製品の集合体で、この単位でユーザに使用を許可設定をすることで、開発チームなどは環境構築をすばやく行うことができます。
A:クロススタック参照を使用し、パラメータを減らすことはできますが、呼び出し元のテンプレートでは、もともとのテンプレートで必要なパラメータを入力する必要があり、運用負荷は減っていません。
B:こちらも結局、パラメータを削減することはできていません。
C:設定ファイルやスクリプトを使って、スタック間のパラメータを共有することは、テンプレートの修正をするたびに設定ファイルなども変更する必要が出てくるため、よいやり方ではありません。
回答:D、E
問題24回答
Auto Scalingなインスタンスはいつ停止・削除してもいいように、インスタンス上に状態(ステート)を持たないようにアプリケーションを作る必要があります。このことをステートレスといいます。例えば、ニュースレポートサイトの利用者がサイトにログインし、その情報を特定のインスタンスでしか持っていない場合、このインスタンスがAuto Scalingによって削除されてしまうと、利用者はログインをし直さなければいけません。
RDSのリードレプリカは、読み取り専用のシステムのDB層では、トラフィック増に対し効果的に応答することができます。
よって正解はAです。
回答:A
問題25回答
このアーキテクチャはDBがオンプレミス、WEBアプリケーションがAWSにあるハイブリッド構成で、オンプレミス側には同じDBを参照する複数のアプリケーションがあるため、ハイブリッド構成は維持する必要があります。
選択肢Cでは、データセンターとVPC間にVPN接続を追加する、とあります。Direct Connectを冗長化する手段としてVPN接続を追加する方法があり、これはアプリケーションとDBの間の接続が高可用性になりアーキテクチャ全体の改善につながります。Direct Connectをアタッチしている既存の仮想プライベートゲートウェイとデータセンターの間にVPN接続を作成することで、Direct Connectのリンクが失われた時には自動でVPN接続にフェイルオーバーされます。
参考URL:AWS Direct Connect リンクが停止すると接続は失われますか?
A:VPCへ接続するためにはプライベート仮想インターフェースが必要です。パブリック仮想インターフェースはパブリックIPを使いDirect Connect経由でAWSのサービスへアクセスするのに使います。
B:Lambdaを使用してもあまり利点はありません。アーキテクチャが複雑になるだけです。
D:オンプレミス側に複数のアプリケーションがあるため、不適切です。
回答:C
問題26回答
VPCでアプリケーションを作成し、これをPrivateLinkを使ったエンドポイントサービスとして設定することができます。これによりパブリックなネットワークに出ることなくVPCのサービスを提供することができます。これらのPrivateLink経由でアクセスできるサービスは、AWSのサービス、別アカウントのサービスやマーケットプレイスのサービスでも設定できます。また、Direct Connect経由でオンプレミス環境からもアクセス可能です。サービス利用側はENIとIPアドレスを持った、インターフェース型のVPCエンドポイントをVPCに作成します。エンドポイントはプライベートIPを持つため、セキュリティグループを使ったアクセス制御をすることができます。
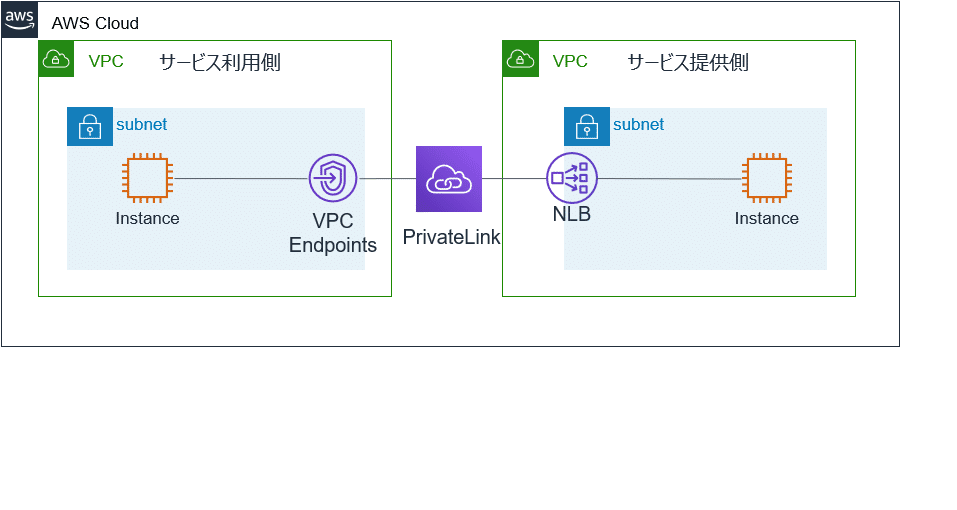
A:200のVPC間のピアリングは作成と管理が煩雑で、アーキテクチャが複雑になるため不適切です。
B:IPsec VPNはインターネットを通過しているため不適切です。
C:Bと同様にインターネットを通過するため不適切です。
回答:D
問題27回答
払い出されインスタンスに割り当てられていないElastic IPアドレスは請求対象になります(個人環境でハンズオンや動作確認したあとに、消し忘れありますよね)。EBSボリュームも請求対象になりますので、これ以上使用されていないことを確認した後削除するのはコストの節約になります。
A:CloudFormationのスタックはリソースそのものになりますので、削除するとリソースが削除されます。
C:Auto Scalingグループも起動テンプレートも定義情報ですので、コストは発生しません。
回答:B、D
問題28回答
増加する注文数を処理するためにAuto Scalingを備えたEC2インスタンスと、重複を防ぎ信頼性を確保するために冪等性を実装したアプリケーションでSQS標準キューからポーリングしている構成のCが正解です。
SQSの特徴をご確認ください。
A:SQS FIFOキューはスループットが要件を満たしていません。
B:メッセージキュー用のアプリケーションは拡張性を効力する必要があります。
D:注文と在庫用アプリケーションの拡張性が考慮されていません。
回答:C
問題29回答
選択肢BのS3にあるWEBのファイルを使って起動させる合計4台のEC2インスタンス、その前に配置したELBとマルチAZ構成のRDSで高可用性な構成と言えるでしょう。
A:サイトは動的コンテンツを使っているのでS3を使ったホスティングは不適切でしょう。また、ELBはどこに使うのでしょうか。。
C:ELBをWEBサーバの前に配置するという記載がありませんが、ELBのエンドポイントに対しRoute53はエイリアスレコードを作成する必要があります(CNAMEでも可)。
D:Cと同様にAレコードではなくエイリアスレコードを作成する必要があります。
回答:B
問題30回答
この設問はRout53を組み合わせたヘルスチェックの動作について問われています。RDSの正常性をチェックできていないため、フェイルオーバーに失敗しています。ALBはターゲットグループのヘルスチェックパスを元に正常かどうかを判断しているので、ヘルスチェックパスにリクエストが来たタイミングでアプリケーションはRDSにアクセスできることを確認するようにすれば、RDS異常時にALB自身も異常であることを通知できます。Route53がこの異常であることを評価する設定が「ターゲットの正常性の評価(Evaluate Target Health)」になります。よってCとDが正解です。
Route53の組み合わせについては、参考URLをご参照ください。また、読むに当たりRoute53の注意点としては以下の3点あります。
・Active-Passiveなフェイルオーバーは、フェイルオーバールーティングで設定する。
・Active-Activeなフェイルオーバーは、加重やレイテンシーで「ターゲットの正常性の評価」をつけることで実装できる。
・Route53のヘルスチェックはエイリアスレコードにはつける必要がない。例えばALBはインスタンスに対してヘルスチェックを行っているが、ALBのターゲットがすべてNGの場合には、ターゲットの正常性の評価を設定していればその結果をもとにRoute53は対象のALBへルーティングしない。
参考URL:複雑な Amazon Route 53 構成におけるヘルスチェックの動作
A:加重レコードを変更してもフェイルオーバーの動作には影響ありません。
B:Aと同様です。また、eu-central-1へは常にルーティングされなくなります。
E:この設定ではフェイルオーバーせず要件を満たしません。
この記事が気に入ったらサポートをしてみませんか?