Amazon Personalize を利用したレコメンドシステムの構築

はじめまして!
株式会社 POL にてエンジニアをしております山田高寛です。
最近は株式会社 POL で運営している、理系学生に特化した採用サービス LabBase のインフラ構成の Kubernetes への移行をこそこそとやっております(こちらも後日記事化します!)。
今回、この LabBase にて Amazon Personalize を使ったサーバーレスなレコメンドシステムの検証を実施したのでその過程を紹介します。
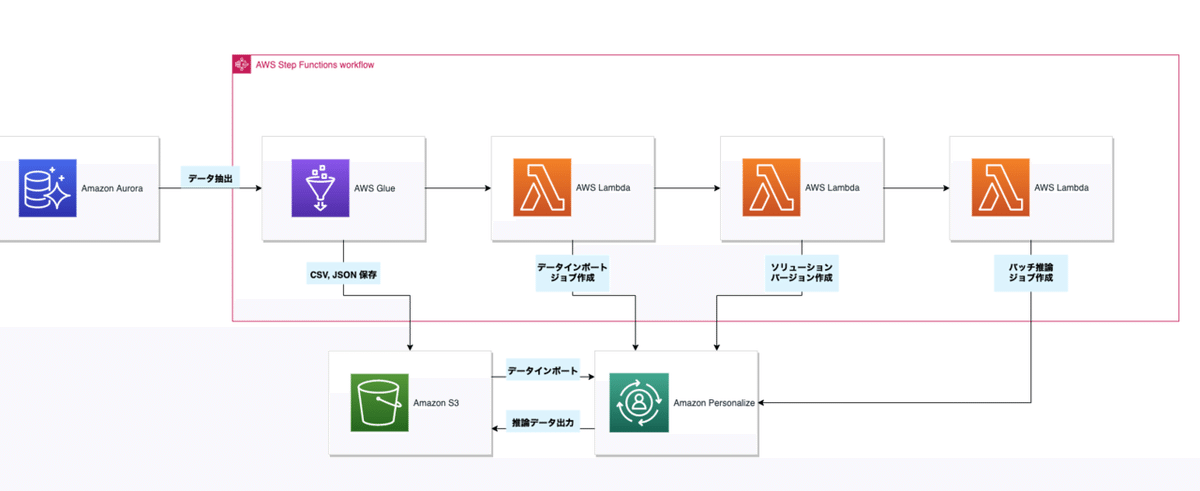
Amazon Personalize とは
AWS が提供しているレコメンドシステムのマネージドサービスです [1]。
学習用のデータを用意するだけでレコメンデーションモデルの構築からレコメンドシステムのデプロイまでを実施できます。
Amazon Personalize を利用するのに必要な学習データは以下の 3 種類です。
・User データ
・Item データ
・User-item interaction データ
※ User-item interaction データは必須ですが、User データと Item データは任意項目です。
User データはレコメンドを受けるデータ、Item データはレコメンドの対象となるデータです。
User-item interaction データは User が Item に対して実施した過去の行動データとなります。
Amazon Personalize では上記 3 種類のデータを CSV 形式を、更に推論時に用いる入力データは JSON 形式である必要があります。
LabBase では Amazon RDS 上にデータがあるため、そこから Amazon Personalize に沿った CSV 形式または JSON 形式のデータを変換する処理を作成しなければなりません。
今回は AWS Glue を用いて Amazon RDS から CSV 形式または JSON 形式でデータを抽出しました。
AWS Glue による ETL 処理
AWS Glue を使うことで Apache Spark ジョブをサーバレスに実行可能です。
Apache Spark ジョブは Python または Scala にて記述できますが、今回は Python (PySpark) を利用しました。
AWS Glue にて Amazon RDS からデータを読み出すには、
1. DynamicFrame で Amazon RDS 上のテーブルデータを取り出す
2. DynamicFrame (DataFrame) を変換・結合して最終的に出力する形式に沿った DynamicFrame (DataFrame) を作成する
3. DynamicFrame (DataFrame) を Amazon S3 に CSV, JSON として書き出す
といった順番で ETL 処理を実施します。
DynamicFrame とは AWS Glue にて用意された Apache Spark の拡張機能であり、Apache Spark の DataFrame の拡張版です。
DynamicFrame では実施できない変換処理がある場合、以下のように toDF() 関数を利用して Apache Spark の DataFrame に変換できます。
# dyf: Glue DynamicFrame
# df: Apache Spark DataFrame
df = dyf.toDF()1. DynamicFrame で Amazon RDS 上のテーブルデータを取り出す
下記のように create_dynamic_frame_from_options 関数を使うことで Amazon RDS 上のテーブルデータを取り出すことができます。
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.dynamicframe import DynamicFrame
sc = SparkContext.getOrCreate()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
src_jdbc = glueContext.extract_jdbc_conf(connection_name='db_connection')
df = glueContext.create_dynamic_frame_from_options(
connection_type=src_jdbc['vendor'],
connection_options={
"url": src_jdbc['url'] + "/labbase",
"user": src_jdbc['user'],
"password": src_jdbc['password'],
"dbtable": tablename
}
)2. DynamicFrame (DataFrame) を変換・結合して最終的に出力する形式に沿った DynamicFrame (DataFrame) を作成する
変換
Amazon Personalize ではインポートするデータにおいて、必須となるフィールドが指定されています。
例えば、User データの場合、USER_ID が必須フィールドとなります。
従って、データベースのカラム名が Amazon Personalize で指定している必須フィールドではない限り、カラム名を変換しなければなりません。
DynamicFrame の場合は RenameField クラスを利用して以下のように実施できます。
# dyf1: 変換前の DynamicFrame
# dyf2: 変換後の DynamicFrame
dyf2 = RenameField(dyf1, "id", "USER_ID")DataFrame の場合は下記のようにできます。
# df1: 変換前の DataFrame
# df2: 変換後の DataFrame
df2 = df1.withColumnRenamed("id", "USER_ID")DynamicFrame の変換は参考資料 [2] に、DataFrame の変換については参考資料 [3] にまとまってあります。
結合
等価結合の場合は以下のようにテーブル同士を結合できます。
dyf1 = glueContext.create_dynamic_frame_from_options(
connection_type=src_jdbc['vendor'],
connection_options={
"url": src_jdbc['url'] + "/labbase",
"user": src_jdbc['user'],
"password": src_jdbc['password'],
"dbtable": table1
}
)
dyf2 = glueContext.create_dynamic_frame_from_options(
connection_type=src_jdbc['vendor'],
connection_options={
"url": src_jdbc['url'] + "/labbase",
"user": src_jdbc['user'],
"password": src_jdbc['password'],
"dbtable": table2
}
)
joined_dyf = Join.apply(dyf1, dyf2, 'id', 'user_id')JOIN type を LEFT や RIGHT にしたい場合は Apache Spark の DataFrame の join() 関数を利用します。
df1 = dyf1.toDF()
df2 = dyf2.toDF()
joined_df = df1.join(df2, df1.id == df2.user_id, how='left')結合した結果の DynamicFrame (DataFrame) のカラムを確認したい場合は printSchema() 関数を使用します。
joined_df.printSchema()
# 出力
# root
# |-- USER_ID: long
# |-- NAME: stringprintSchema() 関数は DynamicFrame だけでなく、DataFrame でも使用可能です。
3. DynamicFrame (DataFrame) を Amazon S3 に CSV, JSON として書き出す
DynamicFrame の変換・結合などで作成した DynamicFrame を CSV 形式で S3 バケット上に書き出すには下記のようにします。
# output_dyf: 書き出す DynamicFrame
output_dir = 's3://aws-glue-temporary-ap-northeast-1/output_dir/'
glueContext.write_dynamic_frame.from_options(
frame=output_dyf,
connection_type="s3",
connection_options={"path": output_dir},
format="csv"
)CSV の形式 (カンマ区切りにするか、ヘッダーを書き込むか) などを調整可能です [4]。
もし、途中で Apache Spark の DataFrame を利用している場合は fromDF() 関数を利用して、DataFrame から DynamicFrame へと変換してから書き込みを実施します。
# output_df: 書き出す DataFrame
output_dyf = DynamicFrame.fromDF(output_df, glueContext, "output")
output_dir = 's3://aws-glue-temporary-ap-northeast-1/output_dir/'
glueContext.write_dynamic_frame.from_options(
frame=output_dyf,
connection_type="s3",
connection_options={"path": output_dir},
format="csv"
)また、format を "csv" から "json" に変更することで JSON 形式で書き出すことができます。
Amazon Personalize でのレコメンド結果の取得
AWS Glue を用いて Amazon Personalize の学習に必要なデータが準備ができたので、まずは手動にてレコメンド結果を取得します。
レコメンド結果を取得するには以下のような流れにて実施します。
1. Amazon Personalize 上でデータをインポートする
2. Amazon Personalize で学習 (ソリューション、ソリューションバージョンを作成する)
3. レコメンドデータを推論させる
Amazon Personalize では「リアルタイム推論」もしくは「バッチ推論」の 2 種類の推論方法があります。
リアルタイム推論は料金が時間制であり、今回はリアルタイムでの推論が不要なためバッチ推論を使用します。
実際の手順は AWS ドキュメントの [5] に図付きで記載されているため、詳細は省略します。
以下では手順の流れと、Tips やハマリポイントを紹介していきます。
1. Amazon Personalize 上でデータをインポートする
スキーマの作成
Amazon Personalize では学習データをインポートさせる前に、以下のような Apache Avro という JSON に似た形式に沿って、インポートするデータのスキーマを事前に定義してあげる必要があります。
{
"type": "record",
"name": "Interactions",
"namespace": "com.amazonaws.personalize.schema",
"fields": [
{
"name": "USER_ID",
"type": "string"
},
{
"name": "ITEM_ID",
"type": "string"
},
],
"version": "1.0"
}基本的には CSV の形式とデータ型に合わせて、fields の値を書き加えるだけで良いですが、Apache Avro の形式を間違えた場合 AWS コンソール上でたまにエラーが出てスキーマを読み込んでくれない場合があります。
コンソール上のエラー文ではどこの箇所にエラーが出ているのかわからないので、参考資料 [6] にある Apache Avro の Validator を利用することでどの箇所がおかしいのか確認できます。
データのインポート
ドキュメント [5] のトレーニングデータをインポートするの手順に従って、読み込む S3 のパスを指定します。
これを User データ、Item データ、User-item interaction データと繰り返していき、データセットグループを作成します。
2. Amazon Personalize で学習 (ソリューション、ソリューションバージョンを作成する)
データをインポートできたらインポートしたデータでモデルを作成します。
それにはまず、Amazon Personalize 上ではソリューションを作成する必要があります。
ソリューションには、利用するデータや利用するルゴリズム (レシピと呼ばれます)とそのパラメータ、もしくは AutoML の ON/OFF、HPO (ハイパーパラメータの最適化) の ON/OFF を指定します。
こだわりがない限りは、AutoML と HPO を ON にするのが良いと思われます。
ソリューションを作成したらソリューションバージョンを作成することで学習させてモデルを作成します。
モデルの学習は並列に学習が実施されるみたいで、コンソール上に出てくるトレーニング時間と実際に経過する時間は一致しません。
3. レコメンドデータを推論させる
バッチ推論を実施する場合はマネジメントコンソールの左側、ナビゲーションペインで [Batch inference jobs] を選択して、[Create batch inference job] からバッチ推論ジョブを作成します。
バッチ推論ジョブの作成時には、
・ソリューションとバージョン
・推論結果数 (最大 1000 まで)
・推論の入力データの S3 パス (JSON 形式)
・推論結果データを出力する S3 パス
を指定します。
バッチ推論ジョブが完了したら作成時に指定した S3 パス上に、下記のような各行が JSON 形式で書き出されます。
{"input":{"userId":"4638"}, "output": {"recommendedItems": ["296", "1", "260", "318"]}, {"scores": [0.0009785, 0.000976, 0.0008851]}}Step Functions を用いた再学習・バッチ推論ワークフローの作成
サービスの利用者の行動は時間共に変化していき、サービス上のデータも変化・更新されていきます。
それに追従するために Amazon Personalize で作成したモデルも更新されたデータセットにて都度再学習させる必要があります。
手動で ETL や Amazon Personalize でデータインポート、モデルの学習をするのは運用コストが高くなるため、今回は AWS Step Functions で自動で再学習とバッチ推論を定期実行するワークフローを作成しました。
このワークフローでは下記のことを実施します。
1. Glue ETL ジョブをトリガーして Amazon Personalize の学習・推論に必要な CSV, JSON データを書き出す
2. Lambda でデータインポートジョブを作成
3. Lambda でソリューションバージョンの作成
4. Lambda でバッチ推論ジョブを作成して S3 にレコメンドデータを CSV で出す
AWS Step Functions について
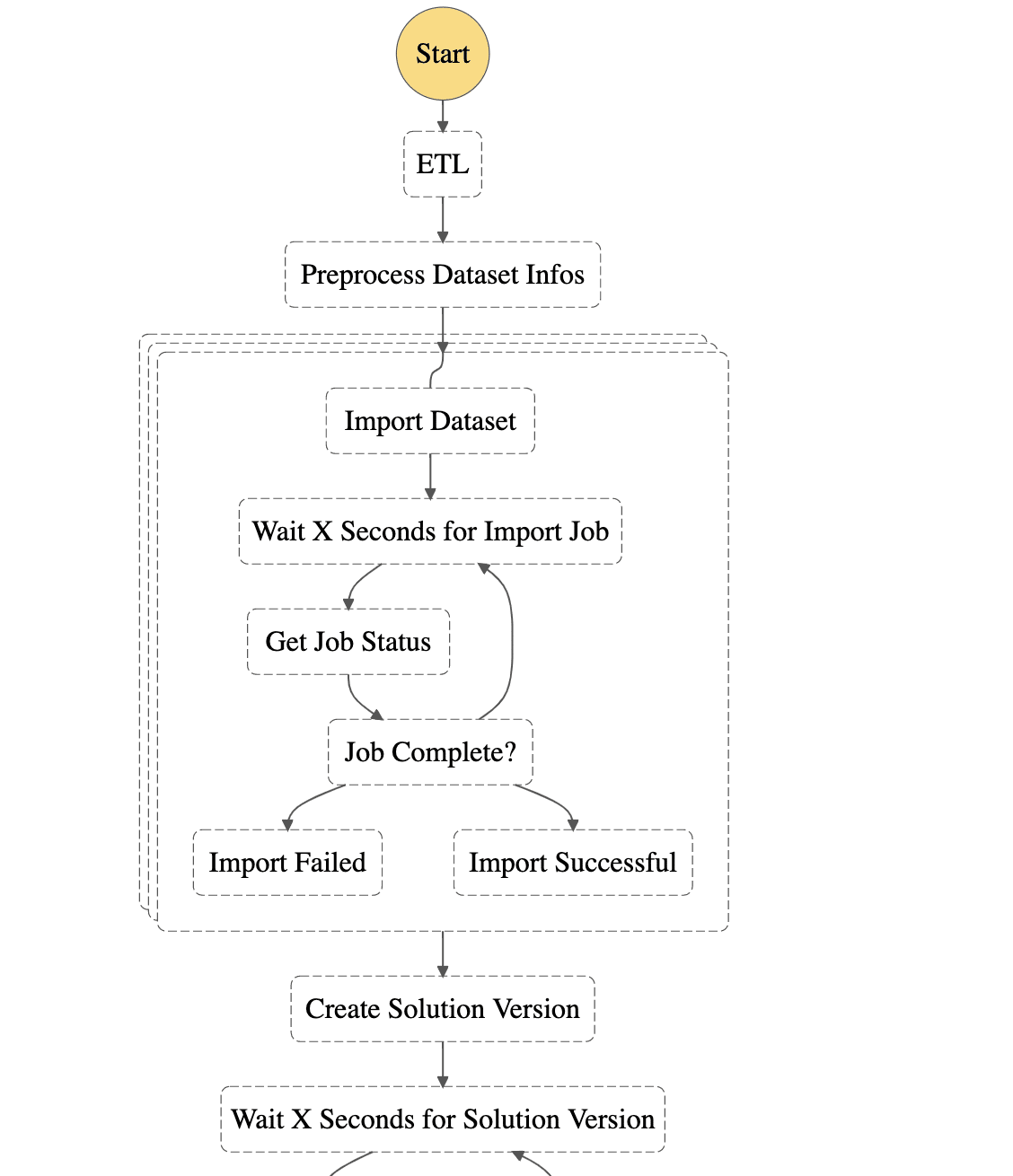
AWS Step Functions は図のようなダイアグラムを作成することができ、それぞれの State にて主に下記のような処理を実施できます。
・Task: Lambda 関数の実行, Glue ジョブの実行など
・Wait: 指定時間待機する
・Parallel: 並列処理を実施する
・Choice: 条件分岐
・Fail: ワークフローの最終状態 (失敗)
・Succeed: ワークフローの最終状態 (成功)
なので、例えば「Glue の結果をもとに Lamdba にて特定の処理を実行したい」などといった複数 AWS サービス間で依存関係をもつ要件を満たすことができます。
ワークフローを作成するには ASL (Amazon States Language) という JSON 形式の DSL を作成する必要があります。
また、AWS Step Functions Data Science SDK というオープンソースライブラリがあり、Python でワークフローを記述可能です。
今回は参考資料 [7] で Amazon Personalize の再学習を実施できる ASL が用意されていたのでこれを利用しました。
Glue ETL ジョブのトリガー
AWS Step Functions の Task State では Glue ジョブの実行をトリガーできます。
下記のような ASL を記述することで、Glue ジョブをトリガーできます。
{
"Comment": "Retrains Personalize",
"StartAt": "ETL",
"States": {
"ETL": {
"Parameters": {
"JobName": "<Glue JOB 名>"
},
"ResultPath": "$.ETL StepResults",
"Resource": "arn:aws:states:::glue:startJobRun.sync",
"Type": "Task",
"End": true
}
...
Amazon Personalize のトリガー
AWS Step Functions は Amazon Personalize の API を Task として設定できないため、Lambda を呼び出す Task を作成してその Lambda の中で Amazon Personalize のデータインポートジョブの作成、ソリューションバージョンの作成、バッチ推論ジョブの作成を実施する必要があります。
ASL は参考資料 [7] のものを利用して、バッチ推論ジョブを実施するように変更しています。
Glue ジョブをトリガーしているときは異なり、データインポートジョブの作成、ソリューションバージョンの作成、バッチ推論ジョブの作成は非同期で行われるため、各ジョブのステータスを監視するというループを組み込む必要があります。
{
"Comment": "Retrains Personalize",
"StartAt": "ETL",
"States": {
...
"Reimport All Datasets": {
"Type": "Map",
"ItemsPath": "$.datasets",
"MaxConcurrency": 0,
"Next": "Create Solution Version",
"ResultPath": "$.datasetImport",
"Iterator": {
"StartAt": "Import Dataset",
"States": {
"Import Dataset": {
"Type": "Task",
"Resource": "<Amazon Personalize のデータインポートジョブを作成する Lambda 関数の ARN>",
"ResultPath": "$.importJobArn",
"Catch": [],
"Next": "Wait X Seconds for Import Job"
},
"Wait X Seconds for Import Job": {
"Type": "Wait",
"Seconds": 600,
"Next": "Get Job Status"
},
"Get Job Status": {
"Type": "Task",
"Resource": "<Amazon Personalize のデータインポートジョブのステータスをチェックする Lambda 関数の ARN>",
"ResultPath": "$.importJobStatus",
"Next": "Job Complete?"
},
"Job Complete?": {
"Type": "Choice",
"Choices": [
{
"Variable": "$.importJobStatus",
"StringEquals": "CREATE FAILED",
"Next": "Import Failed"
},
{
"Variable": "$.importJobStatus",
"StringEquals": "ACTIVE",
"Next": "Import Successful"
}
],
"Default": "Wait X Seconds for Import Job"
},
"Import Failed": {
"Type": "Fail"
},
"Import Successful": {
"Type": "Succeed"
}
}
}
},
"Create Solution Version": {
"Type": "Task",
"Resource": "<Amazon Personalize のソリューションバージョンを作成する Lambda 関数の ARN>",
"ResultPath": "$.solutionVersionArn",
"Next": "Wait X Seconds for Solution Version"
},
"Wait X Seconds for Solution Version": {
"Type": "Wait",
"Seconds": 600,
"Next": "Get Solution Version Status"
},
"Get Solution Version Status": {
"Type": "Task",
"Resource": "<Amazon Personalize の作成したソリューションバージョンのステータスをチェックする Lambda 関数の ARN>",
"ResultPath": "$.solutionVersionStatus",
"Next": "Solution Version Active?"
},
"Solution Version Active?": {
"Type": "Choice",
"Choices": [
{
"Variable": "$.solutionVersionStatus",
"StringEquals": "CREATE FAILED",
"Next": "Report Failure"
},
{
"Variable": "$.solutionVersionStatus",
"StringEquals": "ACTIVE",
"Next": "Trigger Batch Inference"
}
],
"Default": "Wait X Seconds for Solution Version"
},
"Trigger Batch Inference": {
"Type": "Task",
"Resource": "<Amazon Personalize のバッチ推論ジョブを作成する Lambda 関数の ARN>",
"ResultPath": "$.batchInferenceJobArn",
"Next": "Get Batch Inference Status"
},
"Get Batch Inference Status": {
"Type": "Task",
"Resource": "<Amazon Personalize の作成したバッチ推論ジョブのステータスをチェックする Lambda 関数の ARN>",
"ResultPath": "$.batchInferenceJobStatus",
"Next": "Batch Completed?"
},
"Batch Completed?": {
"Type": "Choice",
"Choices": [
{
"Variable": "$.batchInferenceJobStatus",
"StringEquals": "CREATE FAILED",
"Next": "Report Failure"
},
{
"Variable": "$.batchInferenceJobStatus",
"StringEquals": "ACTIVE",
"Next": "Filter Recommended Item"
}
],
"Default": "Wait X Seconds for Batch Inference"
},
"Wait X Seconds for Batch Inference": {
"Type": "Wait",
"Seconds": 600,
"Next": "Get Batch Inference Status"
},
...最後に、作成した Step Functions を CloudWatch Events でトリガーしてあげることで上記ワークフローを定期実行することができます。
まとめ
AWS Glue, Amazon Personalize, AWS Step Functions といった AWS の各種マネージドサービスを利用することでレコメンドシステムを構築できました。
Amazon Personalize は機械学習の経験がなくてもデータさえ用意できれば、レコメンドシステムの検証を実施できるのが魅力的です。
しかし、レコメンド結果にフィルタリングを入れたい(※現在は機能提供されております)などといった、マネージドサービスであるがゆえに細かいところに手が届かない場面もあり、今後は Amazon Personalize に任せきりになっているレコメンドアルゴリズムを Amazon SageMaker などを利用して改善できればと考えております。
また、今回構築したシステムはサーバーレスであるため、リソース管理から開放され、また利用料金についても pay-as-you-go の従量課金制となっているため運用コストを抑えることができました。
株式会社 POL プロダクト部について
株式会社 POL ではエンジニアを募集しております!
募集上ではバックエンド・フロントエンドエンジニアとなっておりますが、機械学習・インフラエンジニアも Welcome ですのでお気軽にお声がけください!
https://pol.co.jp/recruit/engineer
参考情報
・[1] Amazon Personalize(アプリケーションにリアルタイムの推奨を構築する)| AWS
https://aws.amazon.com/jp/personalize/
・[2] AWS Glue PySpark 変換リファレンス - AWS Glue
https://docs.aws.amazon.com/ja_jp/glue/latest/dg/aws-glue-programming-python-transforms.html
・[3] pyspark.sql module — PySpark 2.4.0 documentation
http://spark.apache.org/docs/2.4.0/api/python/pyspark.sql.html#pyspark.sql.DataFrame
・[4] AWS Glue での ETL 入力および出力の形式オプション - AWS Glue
https://docs.aws.amazon.com/ja_jp/glue/latest/dg/aws-glue-programming-etl-format.html#aws-glue-programming-etl-format-csv
・[5] 開始方法 (コンソール) - Amazon Personalize
https://docs.aws.amazon.com/ja_jp/personalize/latest/dg/getting-started-console.html
・[6] Avro schema to JSON Schema
https://json-schema-validator.herokuapp.com/avro.jsp
・[7] aws-samples/amazon-personalize-automated-retraining: Automatic (periodic) retraining of Amazon Personalize
https://github.com/aws-samples/amazon-personalize-automated-retraining
この記事が気に入ったらサポートをしてみませんか?