
TWLogAIAN:インデックス作成時間に悩む

今朝は5時から開発開始です。
機械学習による異常検知
の調査の続きです。このサイトで紹介されているアクセスログのデータ
は、アクセス制限がかかっていてダウンロードできませんでした。このサイトにユーザー登録しましたが、それでもだめです。データの所有者に問い合わせる機能も試してましたが、この機能自体の問題で送信できないようです。そこで昨日の夜、他に同じようなアクセスログのデータセットがないか探してみました。
ありました。
サイズなどが似ているので同じデータかもしれません。
ダウンロードしてTWLogAIANに読み込ませてみました。読み込みの速度が遅くて数時間かかりそうなので途中で止めました。この際なので遅い原因を調べることにしました。以前、調べた時は全文検索エンジン(Bluge)のインデックス作成処理
の速度が関係していました。再びバッチ処理(まとめて登録する)の数や間隔を調整してみましたが、数を増やす(1万を10万とか)と速度は極端に低下しました。結局元に状態に戻しました。
ログをアクセスログとしてデータを取り出す処理(パース)を簡略化して時刻データだけ取り出す方法に変えてみると、1000万件を33分で読み込めました。
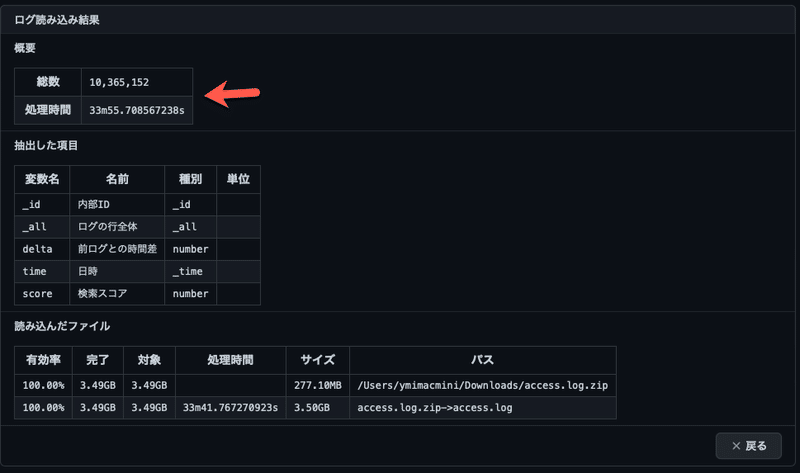
しかし、キーワードを入力せずに検索すると無応答になってしまいました。
プログラムを停止して、キーワードPOSTを指定して検索すると
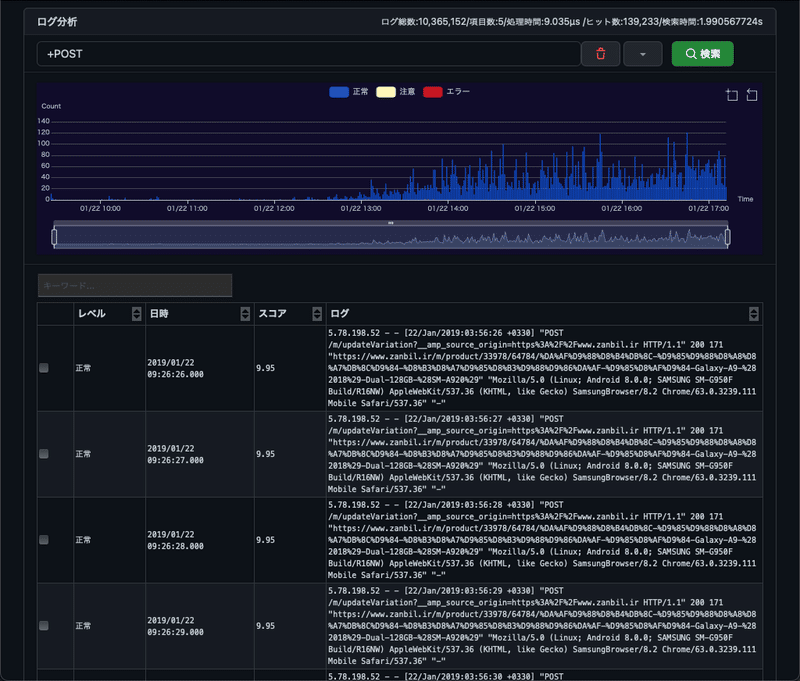
のように1秒ぐらいで結果を表示できました。
この検索時に指定したPOSTを読み込み時のフィルターに指定してみました。
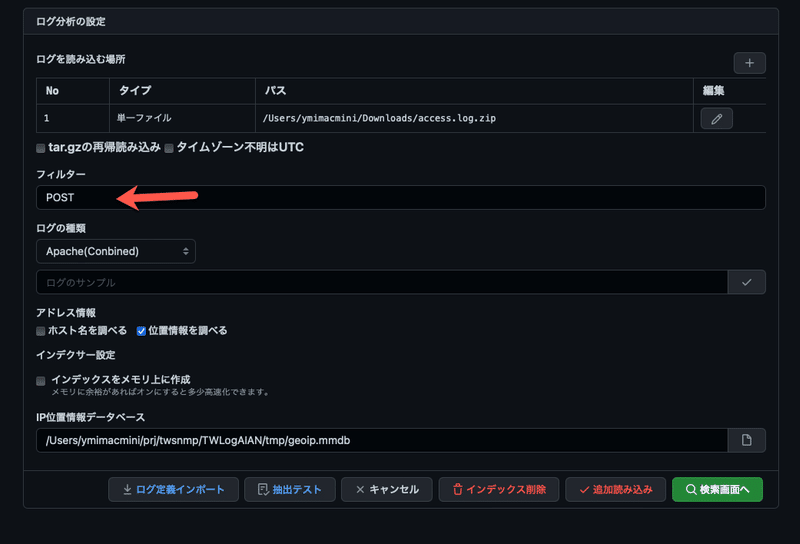
そうすると、何と3分弱(1/10以下)で読み込めます。しかも、アクセスログとしてパース付きです。
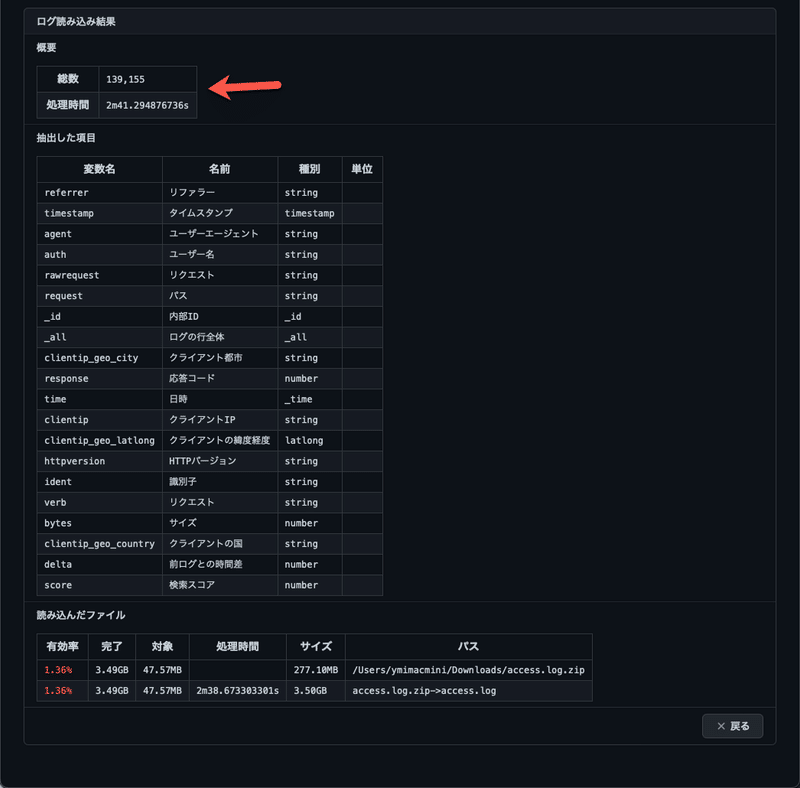
インデックスの読み込んだ割合は1.36%です。キーワードなしの検索でもフリーズしません。
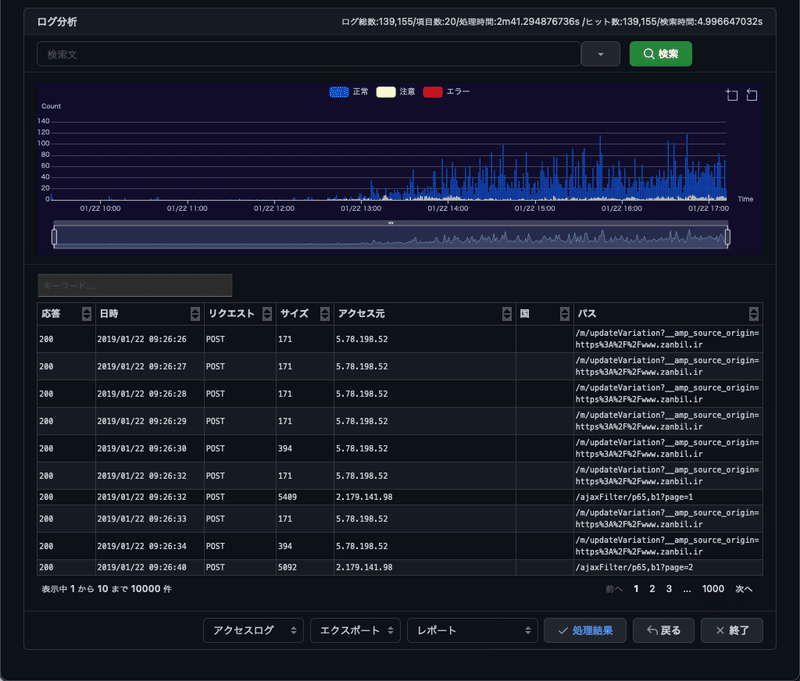
4秒で検索できます。
ログの中で分析に必要なものをフィルターをかけてインデックス作成することで高速に読み込めて、検索も速いということです。
漏れなく調査したいという気持ちはわかりますが、欲張らずに読み込むデータ量をフィルターで減らす工夫をするのが良いという教訓を得ました。
助手の猫が天から「フィルターをかけると見えるものがある!」と言ってそうです。
明日に続く
開発のための諸経費(機材、Appleの開発者、サーバー運用)に利用します。 ソフトウェアのマニュアルをnoteの記事で提供しています。 サポートによりnoteの運営にも貢献できるのでよろしくお願います。