Pythonでシステムトレード〜pandas基礎〜

こんにちは。Qです。
ここではpandasの基礎について書きたいと思います。初心者に相場のデータ分析を教えることになり、基礎操作がわかってないと辛いと思ったのでその人向けに書きました。
もし良ければどうぞ。

pandasはPythonの表計算に使われるライブラリでデータを分析するためには、避けて通れないライブラリです。
その機能も多岐に渡り、ここでは紹介しつくすことはできないです。
公式サイト
0.コードとデータ
1.用語解説・DataFrameとSeries
pandasには大きく分けて二つの種類のデータがあります。それが
SeriesとDataframeです。(Tableというデータの形もありますが、ここでは触れません)
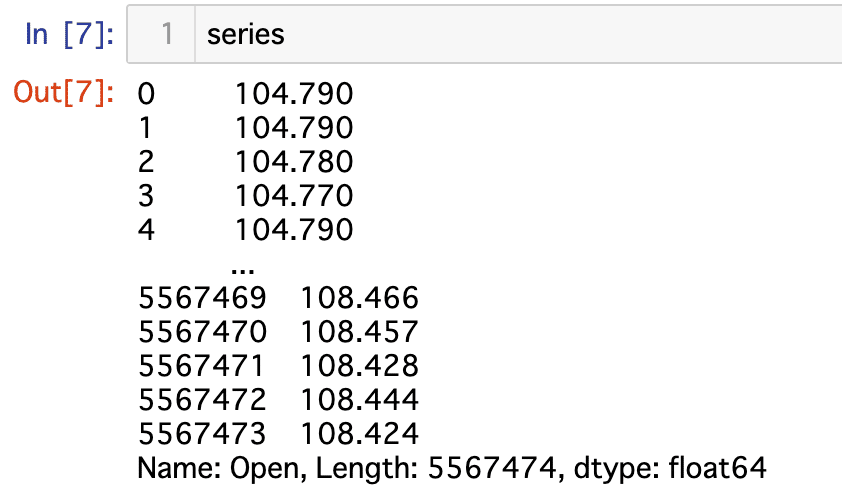
Series :1列(1次元)のデータ
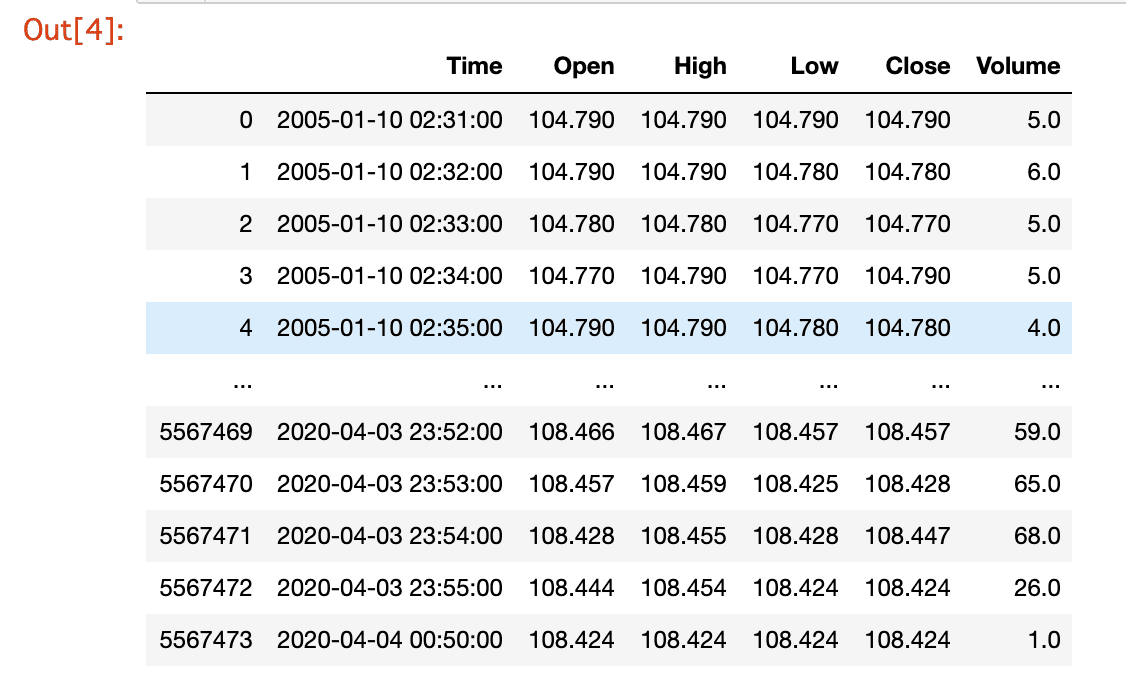
Dataframe:行と列(多次元)のデータ
2.データを読み込む
read_csv(path)

csvファイル形式のデータを読み込みます。
()内にデータのpathを指定することで、データを読み込みます・
相場分析の際によく使用するオプション
dtype : 辞書型 読み込むデータの型を指定します。予期しないデータ型で読み込むのを防ぎます。
parse_dates : リスト型
リストの形で日付データを読み込みます。日付型として読み込むことで、日付データに独特な処理を可能にします。
参考公式サイト
似たようなファイル読み込みメソッドにread_json、read_tableがあります。
3.データを書き出す
to_csv(file)

to_csvとすることで編集後のデータを書き出すことができます。
相場分析の際によく使用するオプション
index : bool
index = Falseとすると保存する際にindexの列が除外されます。
私は、日付型の列がインデックスになっているとかでない限りFalseにしています。
参考公式サイト
4.カラム名を変更する・カラム名を抜き出す
データ分析をしていると必要なデータのカラムを指定することが多くなると思います。そういったときによく使うのがdf.columnsという変数です。df.columns = listとすることで書き換えもできます。

カラムが存在するかどうか調べたいときはカラム名 in df.columnsとすると確認できます。返ってくるのはTrueとFalseの値です。

5.列を抜き出す
一列の場合は下記で抜き出せます。
df[カラム名]
df.カラム名

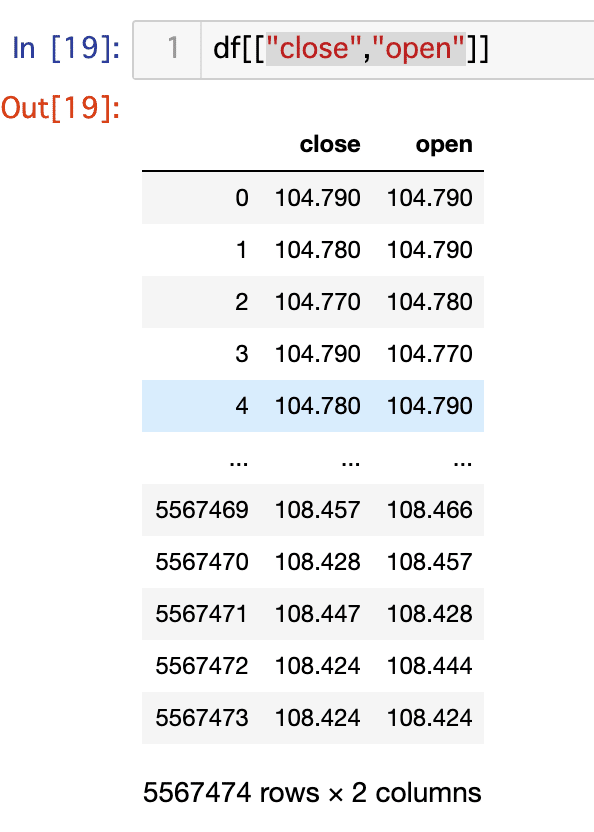
2列以上の場合、リストの形で抜き出します。
6.numpyに変換する
.values
.valuesをつけるとnumpyに変換されます。

7.条件に合わせて抜き出す
df[df[カラム]条件式]
カラムをなんらかの条件で抜き出したい場合、dfのなかに条件式を書きます。
下記はcloseの価格が106円より高い場合を抜き出します。

and条件or
複数の条件で抜き出したい場合は()&()もしくは()|()という形にします。

8.列に関数を適用する
.apply(関数名)とすることで列に関数を適用できます。
ここではhourという、時間帯を抜き出す関数をtime列に適用しています。

参考公式サイト
9.階差をとる
df.diff(階差分)とするとデータの差分を抜き出せます。変化率を見る場合など非常に便利です。
1階差

2階差

10.条件に合わせて抜き出す groupby
groupby関数を使うことで、カラムの種類ごとの集計ができます。
いったんgropubyで集計したいオブジェクトを指定し、そこに集計のメソッドをかけます。
集計単位には、mean(平均)median(中央値)count(総数) min(最小値) max(最大値) sum(合計値) std(標準偏差)などがあります。
今回は時間ごとの変化の大きさの平均について集計してみます。
(ドル円のデータですが、4時5時・・・怪しいですね)

参考公式サイト
11.記述統計をとる
.他にも記述統計をとる方法はあります。
describe()とすることで記述統計を一瞬で出せます。

少し補足すると、25%はデータを降順に並べて25%の位置にあるデータということです。
75%も同様です。
12.データの情報を見る
df.head()→データフレームの上の行を確認
df.tail()→データフレームの下の行を確認
数値を入れると表示する行を指定することができます。
df.info()→データ型など確認

13.NaNを埋める
データにはたまにデータの抜け漏れ(欠損)が出てきます。その値の埋め方で簡単なものを紹介します。
.dropna()
NaNがある行を消してしまいます。一行目にNaNがあったので、一行目が消えました。

.bfill()
後ろの値でNaNを埋めます。diffにあった0行目のNaNが一行目の数値で埋まりました。

.ffill()
前の値でNaNを埋めます。前に数値がないと埋まりません。
14.移動平均を計算する
.rolling(n).mean()
移動平均の計算の際に使用します。
rollingメソッドは標準偏差の計算などにも使えます。.rolling(n).std()のように条件の部分を平均 mean()から変更します。

15.指数平滑移動平均を計算する
.ewm(num).mean()

しかし、計算上emaと違うとの指摘されているサイトもあります。
とりあえずは以上になります。
今日も読んでくださってありがとうございました。
必要がありそうなものは適宜追記していきます。
Q
この記事が気に入ったらサポートをしてみませんか?