米株プログラミング[2-5](決算情報編)

こんにちわトミィ(@toushi_tommy)です!今回はスクレイピングを使って決算情報のサマリを出すようにしました。yahoo_fin が提供している get_earnings_history を使ってみたのですが、頻繁にタイムアウトして、データが取れない事が多く、諦めてしまいました。色んな所から決算データを取るように試しましたが、今回は Earnings Whispers を使っております。下記のサイトをご覧ください。より詳細を見る場合には、こちらが良いと思います。
サークルは無料で運営しております。記事内容も無料です。トミィにジュースでもおごってあげようと思った方は投げ銭いただけると、今後の運営の励みになります。
決算情報確認
決算情報を確認する為には、前回の決算データを取得する必要があります。今回、Earnings Whispers をスクレイピングし、ウォッチリストをリスト形式で、出力するようにしました。前回リスト作成ではplotlyを使って表作成したのですが、リスト項目が多い場合は画像保存すると切れてしまう問題がありました。こちらもご覧ください。
その為、今回は画像を作る形にしましたので、切れることもありません。リスト作りの為の参考にしてみてください。コードは以下の通りです。(タイムアウトで実行できない場合は、時間を空けて再度実行してみてください。)
import sys
sys.path.append('/content/drive/MyDrive/module')
import pandas as pd
from bs4 import BeautifulSoup
import requests
import re
from PIL import Image, ImageDraw, ImageFont
import datetime as datetime
import pytz
import os
import IPython
import dateutil.parser
tickers = ['GOOGL', 'AAPL', 'META', 'AMZN', 'MSFT']
output_dir = '/content/drive/MyDrive/output/'
if not os.path.isdir(output_dir): os.makedirs(output_dir)
header = ['Ticker','前回決算日', 'EPS予', 'EPS実', 'EPS(%)', '売上予', '売上実',
'売上(%)','YoY(%)', '次回決算日', 'EPS予想', '売上予想']
df = pd.DataFrame(index=tickers, columns=header)
df['Ticker']=tickers
# データ作成
for t in range(len(tickers)):
ticker=tickers[t]
print("\r now reading -->> " + ticker+ " ---" ,end="")
url='https://www.earningswhispers.com/epsdetails/'+ticker
site = requests.get(url)
data = BeautifulSoup(site.text,'html.parser')
try:
ldate=re.sub('.*/>(.*)</.*', r'\1', str(data.find_all("div", class_="mbcontent")[0]))
if(ldate!=''):
last_date = dateutil.parser.parse(re.sub('.*/>(.*)</.*', r'\1', str(data.find_all("div", class_="mbcontent")[0])))
df.loc[tickers[t],'前回決算日']=last_date.strftime('%Y/%m/%d %H:%M')
eps_act = re.sub('.*>(.*)</.*', r'\1', str(data.find_all("div", class_="mainitem")[0])).replace('(','-').replace(')','')
eps_est = re.sub('.*>(.*)</.*', r'\1', str(data.find_all("div", class_="thirditem")[0])).replace('(','-').replace(')','')
if(len(data.find_all("div", class_="esurp"))>0):
eps_sur = re.sub('.*"esurp", "(.*)", "EPS".*', r'\1', str(data.find_all("div", class_="esurp")[0]))
df.loc[tickers[t],'EPS(%)']=eps_sur
rev_act = re.sub('.*>(.*)</.*', r'\1', str(data.find_all("div", class_="fourthitem")[0])).replace('il','')
rev_est = re.sub('.*>(.*)</.*', r'\1', str(data.find_all("div", class_="fifthitem")[0])).replace('il','')
if(len(data.find_all("div", class_="rsurp"))>0):
rev_sur = re.sub('.*"rsurp", "(.*)", "Revenue".*', r'\1', str(data.find_all("div", class_="rsurp")[0]))
df.loc[tickers[t],'売上(%)']=rev_sur
else:
df.loc[tickers[t],'売上(%)']=''
if(len(data.find_all("div", class_="revgrowth"))>0):
rev_gro = re.sub('.*"revgrowth", "(.*)%",.*', r'\1%', str(data.find_all("div", class_="revgrowth")[0]))
df.loc[tickers[t],'YoY(%)']=rev_gro
else:
df.loc[tickers[t],'YoY(%)']=''
df.loc[tickers[t],'EPS予']=eps_est
df.loc[tickers[t],'EPS実']=eps_act
df.loc[tickers[t],'売上予']=rev_est
df.loc[tickers[t],'売上実']=rev_act
if(eps_act!='')&(eps_est!=''):
df.loc[tickers[t],'EPS(%)']='{:.2%}'.format(float(float(eps_act.replace('$',''))-float(eps_est.replace('$','')))/abs(float(eps_est.replace('$',''))))
else:
df.loc[tickers[t],'EPS(%)']=''
except:
print("NO OLD DATA:",ticker)
pass
url='https://www.earningswhispers.com/stocks/'+ticker
site = requests.get(url)
data = BeautifulSoup(site.text,'html.parser')
next_day = re.sub('.*>(.*)</.*', r'\1', str(data.find_all("div", class_="mainitem")[1]))
next_time = re.sub('.*>(.*)</.*', r'\1', str(data.find_all("div", id="earningstime")[0]))
try:
next_date = dateutil.parser.parse(next_day + ' ' + next_time.replace('ET',''))
except:
next_date = dateutil.parser.parse(next_day)
pass
if(last_date.strftime('%Y/%m/%d')!=next_date.strftime('%Y/%m/%d')):
df.loc[tickers[t],'次回決算日']=next_date.strftime('%Y/%m/%d %H:%M')
eps_cons = re.sub('.*>Consensus:\s+(.*)</.*', r'\1', str(data.find_all("div", id="consensus")[0])).replace('(','-').replace(')','')
rev_cons = re.sub('.*>Revenue:\s+(.*)</.*', r'\1', str(data.find_all("div", id="revest")[0])).replace('il','')
df.loc[tickers[t],'EPS予想']=eps_cons
df.loc[tickers[t],'売上予想']=rev_cons
df = df.sort_values(['次回決算日','前回決算日'], ascending=[True,True])
sort_tickers = list(df['Ticker'])
#########################################################################
# 表作成
#########################################################################
font_title = ImageFont.truetype("/content/drive/MyDrive/module/japanize_matplotlib/fonts/ipaexg.ttf", 18)
font_head = ImageFont.truetype("/content/drive/MyDrive/module/japanize_matplotlib/fonts/ipaexg.ttf", 16)
font_txt = ImageFont.truetype("/content/drive/MyDrive/module/matplotlib/mpl-data/fonts/ttf/DejaVuSans.ttf", 16)
#########################################################################
# 初期設定
title = "ウォッチリスト決算データ"
# Xサイズ
x_width = [80,160,70,70,70,90,90,70,70,160,80,90]
y_width = 30
title_y = 50
x_buff = 10
text_color = (42,63,95)
line_color = (163,197,236)
# 色を付けたいセル(プラスは青、マイナスは赤)
cell_pct = ['EPS(%)','売上(%)','YoY(%)','EPS予','EPS実','EPS予想']
#########################################################################
im = Image.new('RGB', (sum(x_width)+x_buff*2, y_width*(len(tickers)+1)+title_y+10), "white")
draw = ImageDraw.Draw(im)
#### タイトル 部分 ####
draw.text((sum(x_width)/2-400/2, 10),title+ ' ('+datetime.datetime.now(pytz.timezone('Asia/Tokyo')).strftime("%Y/%m/%d %H:%M")+')',
text_color,font=font_title)
#### ヘッダー 部分 ####
xpos=x_buff
ypos=title_y
for i in range(len(header)):
draw.rectangle([(xpos, ypos), (xpos+x_width[i], ypos+y_width)], fill=(221,237,255), outline=line_color, width=1)
draw.text((xpos+10, ypos+5),header[i], text_color,font=font_head)
xpos=xpos+x_width[i]
#### データ 部分 ####
for t in range(len(sort_tickers)):
ticker = sort_tickers[t]
xpos=x_buff
ypos=ypos+y_width
for i in range(len(header)):
draw.rectangle([(xpos, ypos), (xpos+x_width[i], ypos+y_width)], outline=line_color, width=1
, fill=((255,255,255) if t % 2 == 0 else (235,235,235)))
# 色付け #########
if(header[i] in cell_pct):
if (str(df.loc[ticker,header[i]])[:1]=='-'):txt_color="red"
else:txt_color="blue"
else:
txt_color=text_color
draw.text((xpos+5, ypos+5),str(df.loc[ticker,header[i]]), txt_color,font=font_txt)
xpos=xpos+x_width[i]
# 太枠形成 ##############################################################
xpos=x_buff
ypos=title_y
# 外太枠 ######################################
draw.rectangle([(xpos, ypos), (xpos+sum(x_width), ypos+y_width*(len(tickers)+1))], outline=line_color, width=2)
# ヘッダ太枠 ##################################
draw.rectangle([(xpos, ypos), (xpos+sum(x_width), ypos+y_width)], outline=line_color, width=2)
# 他太枠作成 ##################################
bold_fm='前回決算日'
bold_to='YoY(%)'
draw.rectangle([(xpos+x_width[header.index(bold_fm)-1], ypos), (xpos+sum(x_width[header.index(bold_fm)-1:header.index(bold_to)+1])
, ypos+y_width*(len(tickers)+1))], outline=line_color, width=2)
# 出力 ##############################################################
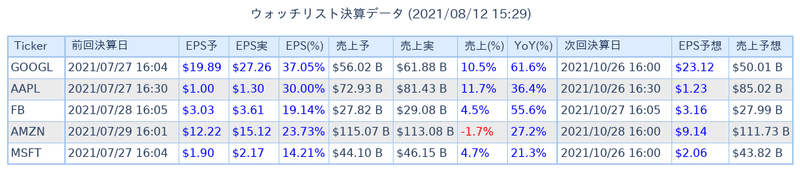
im.save(output_dir+'list.png')
IPython.display.Image(output_dir+'list.png')
#########################################################################出力するとこのようになります。
課題
ウォッチリストを変更して出力を確認しましょう。
今後、コードもこちらを参考にリストを作ってみても良いと思います。
決算結果及びプレ、アフター値
プレ、アフター値を決算結果と一緒に見たい人もいるかもしれませんので、コードを書いてみました。銘柄は (Earnings Whispers) のツイートから取ってきて入れ替えてみてください。
アフターコードはこちら
import sys
sys.path.append('/content/drive/MyDrive/module')
import pandas as pd
from bs4 import BeautifulSoup
import requests
import re
from PIL import Image, ImageDraw, ImageFont
import datetime as datetime
import pytz
import os
import IPython
import dateutil.parser
def get_ext_value(ticker,pre_after):
ret_per = float(0.00)
ret_val = float(0.00)
url = "https://www.marketwatch.com/investing/stock/"+ticker
try:
site = requests.get(url)
data = BeautifulSoup(site.text,'html.parser')
da = data.find_all("span", class_="change--percent--q")
str_per=re.findall('session="'+pre_after+'">(.*)%</bg-quote>', str(da[0]))
da = data.find_all("bg-quote", class_="value")
str_val=re.findall('session="'+pre_after+'">(.*)</bg-quote>', str(da[0]))
if(len(str_per)>0): ret_per=(float(str_per[0]))*0.01
if(len(str_val)>0): ret_val=(float(str_val[0].replace(',','')))
except:
pass
return ret_val,ret_per
tickers = ['GOOGL', 'AAPL', 'META', 'AMZN', 'MSFT']
output_dir = '/content/drive/MyDrive/output/'
if not os.path.isdir(output_dir): os.makedirs(output_dir)
header = ['Ticker','決算日', 'EPS予', 'EPS実', 'EPS(%)', '売上予', '売上実',
'売上(%)','YoY(%)', 'アフター']
df = pd.DataFrame(index=tickers, columns=header)
df['Ticker']=tickers
# データ作成
for t in range(len(tickers)):
ticker=tickers[t]
print("\r now reading -->> " + ticker+ " ---" ,end="")
url='https://www.earningswhispers.com/epsdetails/'+ticker
site = requests.get(url)
data = BeautifulSoup(site.text,'html.parser')
try:
ldate=re.sub('.*/>(.*)</.*', r'\1', str(data.find_all("div", class_="mbcontent")[0]))
if(ldate!=''):
last_date = dateutil.parser.parse(re.sub('.*/>(.*)</.*', r'\1', str(data.find_all("div", class_="mbcontent")[0])))
df.loc[tickers[t],'決算日']=last_date.strftime('%Y/%m/%d %H:%M')
eps_act = re.sub('.*>(.*)</.*', r'\1', str(data.find_all("div", class_="mainitem")[0])).replace('(','-').replace(')','')
eps_est = re.sub('.*>(.*)</.*', r'\1', str(data.find_all("div", class_="thirditem")[0])).replace('(','-').replace(')','')
if(len(data.find_all("div", class_="esurp"))>0):
eps_sur = re.sub('.*"esurp", "(.*)", "EPS".*', r'\1', str(data.find_all("div", class_="esurp")[0]))
df.loc[tickers[t],'EPS(%)']=eps_sur
rev_act = re.sub('.*>(.*)</.*', r'\1', str(data.find_all("div", class_="fourthitem")[0])).replace('il','')
rev_est = re.sub('.*>(.*)</.*', r'\1', str(data.find_all("div", class_="fifthitem")[0])).replace('il','')
if(len(data.find_all("div", class_="rsurp"))>0):
rev_sur = re.sub('.*"rsurp", "(.*)", "Revenue".*', r'\1', str(data.find_all("div", class_="rsurp")[0]))
df.loc[tickers[t],'売上(%)']=rev_sur
else:
df.loc[tickers[t],'売上(%)']=''
if(len(data.find_all("div", class_="revgrowth"))>0):
rev_gro = re.sub('.*"revgrowth", "(.*)%",.*', r'\1%', str(data.find_all("div", class_="revgrowth")[0]))
df.loc[tickers[t],'YoY(%)']=rev_gro
else:
df.loc[tickers[t],'YoY(%)']=''
df.loc[tickers[t],'EPS予']=eps_est
df.loc[tickers[t],'EPS実']=eps_act
df.loc[tickers[t],'売上予']=rev_est
df.loc[tickers[t],'売上実']=rev_act
if(eps_act!='')&(eps_est!=''):
df.loc[tickers[t],'EPS(%)']='{:.2%}'.format(float(float(eps_act.replace('$',''))-float(eps_est.replace('$','')))/abs(float(eps_est.replace('$',''))))
else:
df.loc[tickers[t],'EPS(%)']=''
stock, pct = get_ext_value(ticker,'after')
df.loc[tickers[t],'アフター']='{:.2%}'.format(pct)
except:
print("NO OLD DATA:",ticker)
pass
#df = df.sort_values('決算日', ascending=True)
df['sort'] = pd.to_numeric(df['アフター'].str.replace('%',''))
df = df.sort_values('sort', ascending=False)
sort_tickers = list(df['Ticker'])
#########################################################################
# 表作成
#########################################################################
font_title = ImageFont.truetype("/content/drive/MyDrive/module/japanize_matplotlib/fonts/ipaexg.ttf", 18)
font_head = ImageFont.truetype("/content/drive/MyDrive/module/japanize_matplotlib/fonts/ipaexg.ttf", 16)
font_txt = ImageFont.truetype("/content/drive/MyDrive/module/matplotlib/mpl-data/fonts/ttf/DejaVuSans.ttf", 16)
#########################################################################
# 初期設定
title = "決算データ【アフター】"
# Xサイズ
x_width = [80,160,70,70,70,90,90,70,70,80]
y_width = 30
title_y = 50
x_buff = 10
text_color = (42,63,95)
line_color = (163,197,236)
# 色を付けたいセル(プラスは青、マイナスは赤)
cell_pct = ['EPS(%)','売上(%)','YoY(%)','EPS予','EPS実','アフター']
#########################################################################
im = Image.new('RGB', (sum(x_width)+x_buff*2, y_width*(len(tickers)+1)+title_y+10), "white")
draw = ImageDraw.Draw(im)
#### タイトル 部分 ####
draw.text((sum(x_width)/2-400/2, 10),title+ ' ('+datetime.datetime.now(pytz.timezone('Asia/Tokyo')).strftime("%Y/%m/%d %H:%M")+')',
text_color,font=font_title)
#### ヘッダー 部分 ####
xpos=x_buff
ypos=title_y
for i in range(len(header)):
draw.rectangle([(xpos, ypos), (xpos+x_width[i], ypos+y_width)], fill=(221,237,255), outline=line_color, width=1)
draw.text((xpos+10, ypos+5),header[i], text_color,font=font_head)
xpos=xpos+x_width[i]
#### データ 部分 ####
for t in range(len(sort_tickers)):
ticker = sort_tickers[t]
xpos=x_buff
ypos=ypos+y_width
for i in range(len(header)):
draw.rectangle([(xpos, ypos), (xpos+x_width[i], ypos+y_width)], outline=line_color, width=1
, fill=((255,255,255) if t % 2 == 0 else (235,235,235)))
# 色付け #########
if(header[i] in cell_pct):
if (str(df.loc[ticker,header[i]])[:1]=='-'):txt_color="red"
else:txt_color="blue"
else:
txt_color=text_color
draw.text((xpos+5, ypos+5),str(df.loc[ticker,header[i]]), txt_color,font=font_txt)
xpos=xpos+x_width[i]
# 太枠形成 ##############################################################
xpos=x_buff
ypos=title_y
# 外太枠 ######################################
draw.rectangle([(xpos, ypos), (xpos+sum(x_width), ypos+y_width*(len(tickers)+1))], outline=line_color, width=2)
# ヘッダ太枠 ##################################
draw.rectangle([(xpos, ypos), (xpos+sum(x_width), ypos+y_width)], outline=line_color, width=2)
# 他太枠作成 ##################################
bold_fm='決算日'
bold_to='YoY(%)'
draw.rectangle([(xpos+x_width[header.index(bold_fm)-1], ypos), (xpos+sum(x_width[header.index(bold_fm)-1:header.index(bold_to)+1])
, ypos+y_width*(len(tickers)+1))], outline=line_color, width=2)
# 出力 ##############################################################
im.save(output_dir+'list.png')
IPython.display.Image(output_dir+'list.png')
#########################################################################プレコードはこちら
import sys
sys.path.append('/content/drive/MyDrive/module')
import pandas as pd
from bs4 import BeautifulSoup
import requests
import re
from PIL import Image, ImageDraw, ImageFont
import datetime as datetime
import pytz
import os
import IPython
import dateutil.parser
def get_ext_value(ticker,pre_after):
ret_per = float(0.00)
ret_val = float(0.00)
url = "https://www.marketwatch.com/investing/stock/"+ticker
try:
site = requests.get(url)
data = BeautifulSoup(site.text,'html.parser')
da = data.find_all("span", class_="change--percent--q")
str_per=re.findall('session="'+pre_after+'">(.*)%</bg-quote>', str(da[0]))
da = data.find_all("bg-quote", class_="value")
str_val=re.findall('session="'+pre_after+'">(.*)</bg-quote>', str(da[0]))
if(len(str_per)>0): ret_per=(float(str_per[0]))*0.01
if(len(str_val)>0): ret_val=(float(str_val[0].replace(',','')))
except:
pass
return ret_val,ret_per
tickers = ['GOOGL', 'AAPL', 'FB', 'AMZN', 'MSFT']
output_dir = '/content/drive/MyDrive/output/'
if not os.path.isdir(output_dir): os.makedirs(output_dir)
header = ['Ticker','決算日', 'EPS予', 'EPS実', 'EPS(%)', '売上予', '売上実',
'売上(%)','YoY(%)', 'プレ']
df = pd.DataFrame(index=tickers, columns=header)
df['Ticker']=tickers
# データ作成
for t in range(len(tickers)):
ticker=tickers[t]
print("\r now reading -->> " + ticker+ " ---" ,end="")
url='https://www.earningswhispers.com/epsdetails/'+ticker
site = requests.get(url)
data = BeautifulSoup(site.text,'html.parser')
try:
ldate=re.sub('.*/>(.*)</.*', r'\1', str(data.find_all("div", class_="mbcontent")[0]))
if(ldate!=''):
last_date = dateutil.parser.parse(re.sub('.*/>(.*)</.*', r'\1', str(data.find_all("div", class_="mbcontent")[0])))
df.loc[tickers[t],'決算日']=last_date.strftime('%Y/%m/%d %H:%M')
eps_act = re.sub('.*>(.*)</.*', r'\1', str(data.find_all("div", class_="mainitem")[0])).replace('(','-').replace(')','')
eps_est = re.sub('.*>(.*)</.*', r'\1', str(data.find_all("div", class_="thirditem")[0])).replace('(','-').replace(')','')
if(len(data.find_all("div", class_="esurp"))>0):
eps_sur = re.sub('.*"esurp", "(.*)", "EPS".*', r'\1', str(data.find_all("div", class_="esurp")[0]))
df.loc[tickers[t],'EPS(%)']=eps_sur
rev_act = re.sub('.*>(.*)</.*', r'\1', str(data.find_all("div", class_="fourthitem")[0])).replace('il','')
rev_est = re.sub('.*>(.*)</.*', r'\1', str(data.find_all("div", class_="fifthitem")[0])).replace('il','')
if(len(data.find_all("div", class_="rsurp"))>0):
rev_sur = re.sub('.*"rsurp", "(.*)", "Revenue".*', r'\1', str(data.find_all("div", class_="rsurp")[0]))
df.loc[tickers[t],'売上(%)']=rev_sur
else:
df.loc[tickers[t],'売上(%)']=''
if(len(data.find_all("div", class_="revgrowth"))>0):
rev_gro = re.sub('.*"revgrowth", "(.*)%",.*', r'\1%', str(data.find_all("div", class_="revgrowth")[0]))
df.loc[tickers[t],'YoY(%)']=rev_gro
else:
df.loc[tickers[t],'YoY(%)']=''
df.loc[tickers[t],'EPS予']=eps_est
df.loc[tickers[t],'EPS実']=eps_act
df.loc[tickers[t],'売上予']=rev_est
df.loc[tickers[t],'売上実']=rev_act
if(eps_act!='')&(eps_est!=''):
df.loc[tickers[t],'EPS(%)']='{:.2%}'.format(float(float(eps_act.replace('$',''))-float(eps_est.replace('$','')))/abs(float(eps_est.replace('$',''))))
else:
df.loc[tickers[t],'EPS(%)']=''
stock, pct = get_ext_value(ticker,'pre')
df.loc[tickers[t],'プレ']='{:.2%}'.format(pct)
except:
print("NO OLD DATA:",ticker)
pass
#df = df.sort_values('決算日', ascending=True)
df['sort'] = pd.to_numeric(df['プレ'].str.replace('%',''))
df = df.sort_values('sort', ascending=False)
sort_tickers = list(df['Ticker'])
#########################################################################
# 表作成
#########################################################################
font_title = ImageFont.truetype("/content/drive/MyDrive/module/japanize_matplotlib/fonts/ipaexg.ttf", 18)
font_head = ImageFont.truetype("/content/drive/MyDrive/module/japanize_matplotlib/fonts/ipaexg.ttf", 16)
font_txt = ImageFont.truetype("/content/drive/MyDrive/module/matplotlib/mpl-data/fonts/ttf/DejaVuSans.ttf", 16)
#########################################################################
# 初期設定
title = "決算データ【プレ】"
# Xサイズ
x_width = [80,160,70,70,70,90,90,70,70,80]
y_width = 30
title_y = 50
x_buff = 10
text_color = (42,63,95)
line_color = (163,197,236)
# 色を付けたいセル(プラスは青、マイナスは赤)
cell_pct = ['EPS(%)','売上(%)','YoY(%)','EPS予','EPS実','プレ']
#########################################################################
im = Image.new('RGB', (sum(x_width)+x_buff*2, y_width*(len(tickers)+1)+title_y+10), "white")
draw = ImageDraw.Draw(im)
#### タイトル 部分 ####
draw.text((sum(x_width)/2-400/2, 10),title+ ' ('+datetime.datetime.now(pytz.timezone('Asia/Tokyo')).strftime("%Y/%m/%d %H:%M")+')',
text_color,font=font_title)
#### ヘッダー 部分 ####
xpos=x_buff
ypos=title_y
for i in range(len(header)):
draw.rectangle([(xpos, ypos), (xpos+x_width[i], ypos+y_width)], fill=(221,237,255), outline=line_color, width=1)
draw.text((xpos+10, ypos+5),header[i], text_color,font=font_head)
xpos=xpos+x_width[i]
#### データ 部分 ####
for t in range(len(sort_tickers)):
ticker = sort_tickers[t]
xpos=x_buff
ypos=ypos+y_width
for i in range(len(header)):
draw.rectangle([(xpos, ypos), (xpos+x_width[i], ypos+y_width)], outline=line_color, width=1
, fill=((255,255,255) if t % 2 == 0 else (235,235,235)))
# 色付け #########
if(header[i] in cell_pct):
if (str(df.loc[ticker,header[i]])[:1]=='-'):txt_color="red"
else:txt_color="blue"
else:
txt_color=text_color
draw.text((xpos+5, ypos+5),str(df.loc[ticker,header[i]]), txt_color,font=font_txt)
xpos=xpos+x_width[i]
# 太枠形成 ##############################################################
xpos=x_buff
ypos=title_y
# 外太枠 ######################################
draw.rectangle([(xpos, ypos), (xpos+sum(x_width), ypos+y_width*(len(tickers)+1))], outline=line_color, width=2)
# ヘッダ太枠 ##################################
draw.rectangle([(xpos, ypos), (xpos+sum(x_width), ypos+y_width)], outline=line_color, width=2)
# 他太枠作成 ##################################
bold_fm='決算日'
bold_to='YoY(%)'
draw.rectangle([(xpos+x_width[header.index(bold_fm)-1], ypos), (xpos+sum(x_width[header.index(bold_fm)-1:header.index(bold_to)+1])
, ypos+y_width*(len(tickers)+1))], outline=line_color, width=2)
# 出力 ##############################################################
im.save(output_dir+'list.png')
IPython.display.Image(output_dir+'list.png')
#########################################################################雑談
今回、ムチャクチャ時間かかりました。まず、si.get_earnings_historyが安定して動かない所から始まって、決算情報を取っているサイト Seeking Alpha がスクレイピングをブロックしているのですが、いろいろやってみて、取れる時と取れない時があるので、これもまた安定しない事が分かりました。どうもFSLYのサーバーを使っているようで、何か細工をやっているようです。Seeking Alphaはこちら
スクレイピングをやるときは、HTMLのパターンを解析しないといけないので、結構厄介で時間がかかります。是非、皆さんもいろいろ挑戦してみてください。
本日はここまでです
ここから先は
¥ 150
サポートいただけますと、うれしいです。より良い記事を書く励みになります!