米株Python [3-1] IF/FOR/時間/文字列

こんにちわ!トミィ(@toushi_tommy)です!今回から3章にしたいと思いますが、今までコードのコピペで動いていた項目に関して、初心者向けのコード解説及び、今まで使ったコードのTips集をまとめていきたいと思います。是非、復習も兼ねて理解を深めてください。最後にS&P500のシュミレーションコードを記載しました。
サークルは無料で運営しております。記事内容も無料です。トミィにジュースでもおごってあげようと思った方は投げ銭いただけると、今後の運営の励みになります。(課題の答えのみ有料記事にしております)
Ifの応用編、ラムダ式
まず、綺麗にコードを書くために、私はできるだけifを1行で書けるかどうかを検討します。(noteに張り付けするとインデントがうまくできない場合があるので、できるだけシンプルに書きます。)こちらが参考になりますので、ご覧ください。
私がよく使うコード例を示します。以下のコードを実行して、どのような動きになっているかを理解してください。
リスト内・辞書内にあるかどうか確認しながら値を設定するif文
# リスト
sample_list = ['aaa','bbb','ccc','ddd']
test1 = 1 if 'aaa' in sample_list else 0
test2 = 1 if 'eee' in sample_list else 0
print(test1,test2)
# 辞書
sample_dict = {'aaa':10,'bbb':20,'ccc':30,'ddd':40}
test3 = sample_dict['aaa'] if 'aaa' in sample_dict else 0
test4 = sample_dict['eee'] if 'eee' in sample_dict else 0
print(test3,test4)
# 応用 辞書+ラムダ式
test5 = (lambda x,y,z: x[y] if y in x else z)(sample_dict, 'aaa', 0)
comp = lambda x,y,z: x[y] if y in x else z
test6 = comp(sample_dict, 'eee', 0)
print(test5,test6)上記で使用した応用版のラムダ式(無名関数)については、以下をご覧ください。このラムダ式を使えると、コードをさらに短くできます。
For の内包表記
Forも可能であればできる限り1行で表現します。詳細はこちらも参考にしてみてください。
ちなみに私はスクレイピングでこの表現を多数使っております。スクレイピング課題はこちらです。
こちらを実施してみてください。動作が分かると思います。
data = [1, 2, 3, 4, 5]
# data配列の中身を2倍にする
newData = [d * 2 for d in data]
print(newData)私はスクレイピングでこのように使っております。
deal = data.find_all("td", class_="deal textRight") # 出来高のリストを取得
volume = [int(i) for i in [re.sub('.*>([0-9]+)</.*', r'\1', s) for s in [s.replace(',', '') for s in [str(i) for i in deal]]]]
説明すると(前のリスト結果をxxxで表現してます)
str(i) for i in deal -> 中身をすべてstr型に変換
s.replace(',', '') for s in [xxx] -> リスト内の ',' を削除
re.sub('.*>([0-9]+)</.*', r'\1', s) for s in [xxx] -> リストから数字の部分を取得
int(i) for i in [xxx] -> 数字をint型に変換
と4段階のループを1行で表現しております。replaceを使った置換や、re.subを使った正規表現による置換はこちらをご覧ください。
時間関連
現在の時間の出力を行います。GoogleColabでは現在の時間はUTC(世界協定時刻)になっている為、タイムゾーンを指定する必要があります。以下のコードのようにタイムゾーンを指定することで実際の時間を取得できます。今回、見やすいようにコード中に改行を入れておりますが、その場合は全体をカッコで括ることが必要です。まずは、下記のコードを実行してみてください。
import datetime as datetime
import pytz
date1 = datetime.datetime.now()
date2 = datetime.datetime.now(pytz.timezone('US/Eastern'))
date3 = (datetime.datetime.now(pytz.timezone('Asia/Tokyo'))
.strftime("%Y/%m/%d %H:%M:%S"))
date4 = (datetime.datetime.now(pytz.timezone('US/Eastern')).date()
+ datetime.timedelta(days=-30))
print(date1)
print(date2)
print(date3)
print(date4)処理時間測定系
実行時間を知りたい場合は、timeを使います。以下のコードを実行してみてください。
import time
start = time.time()
# 処理
time.sleep(1) # 1秒待つ
elapsed_time = time.time() - start
print("処理時間: {0}".format(elapsed_time) + "[sec]")時間出力変換系
出力タイプを文字列型、Date型をそれぞれ変換できます。また文字列の場合は好きな出力フォーマットに変換可能です。ファイル作成時にファイル名に日時を入れたい場合などに使えます。
# 文字列 -> Date型
from datetime import datetime as dt
str_time1 = '10/29/2020'
print(type(str_time1),str_time1)
date_time1 = dt.strptime(str_time1, '%m/%d/%Y')
print(type(date_time1),date_time1)
# Date型-> 文字列
import datetime as datetime
date_time2 = datetime.datetime.now()
print(type(date_time2),date_time2)
str_time2 = date_time2.strftime("%Y/%m/%d %H:%M:%S")
print(type(str_time2),str_time2)曜日を確認
weekdayを使うことで曜日を確認することができます。月曜日が0で日曜日が6の整数値が得られます。
import datetime as datetime
import pytz
wk = datetime.datetime.now(pytz.timezone('Asia/Tokyo')).weekday()
print(['月','火','水','木','金','土','日'][wk])現在の時間の米国マーケット情報を取得
現在の時間帯、土日祝日を確認して、プレ・アフター・現在値のどれを使うかを確認する為に使います。0: 市場外、1: プレマーケット、2: 市場時間、3: アフターマーケットのように使うことができます。
import datetime as datetime
import pytz
import holidays
def us_market():
ndate = datetime.datetime.now(pytz.timezone('US/Eastern'))
tmin = ndate.hour*60+ndate.minute
wk = ndate.weekday()
if (ndate in holidays.US()): return 0 # holiday
if (wk==5)|(wk==6): return 0 # Sat/San
if (tmin>240)&(tmin<570): return 1 # US Stock PRE 4:00-9:30
if (tmin>=570)&(tmin<=960): return 2 # US Stock 9:30-16:00
if (tmin>960)&(tmin<=1200): return 3 # US Stock AFTER 16:00-20:00
return 0
print(us_market())数字、文字列の変換等
出力する数字のフォーマットを変えたい場合に使います。主に以下の変換を良く使っております。各コードを実行して出力結果をご覧ください。また、書式変換には「書式化演算子」、「組み込み関数format」を使う方法がございますので、下記のリンクもご参考ください。
数字の小数点以下を指定
下記サンプルでは小数点2桁で出力します。
num = 0.123456
# 書式化演算子
str_num1 = '%.2f'%(num)
print(str_num1)
# 組み込み関数format
str_num2 ='{:.2f}'.format(num)
print(str_num2)パーセンテージ変換
出力を自動でパーセンテージに変換します。さらに小数点以下も2桁で指定してます。
num = 0.5
str_num = '{:.2%}'.format(num)
print(str_num)3桁おきにカンマを入れる
数字が長い場合(発行株式数など)の場合は、3桁おきにカンマを入れないと分かりにくい場合があります。その場合以下の書き方を使います。
num = 1234567890
str_num = '{:,}'.format(num)
print(str_num)数字、短縮文字変換(K/M/B/T付)
数字を単位付き文字列に変換(数字をK/M/B/T付の文字列に変換)、さらにその逆を行いたい場合にこのようなコードを使います。出来高、時価総額、売上等を出力するのに使います。
# 数字 -> 文字列 (K/M/B/T)
num_revenue = 274515000
conv_str = lambda x: '%.2f'%(x/float('1E'+str(3*'{:,}'.format(x).count(','))))+['','K','M','B','T']['{:,}'.format(x).count(',')]
str_revenue = conv_str(num_revenue)
print(str_revenue)
# 文字列 -> 数字
num_rev = float(str_revenue.translate(str.maketrans({'K':'E3','M':'E6','B':'E9','T':'E12'})))
print(num_rev)データ(DataFrame)のCSV保存と読み込み
株価などの取得したデータはCSVファイルに保存できます。また読み込みも可能です。以下サンプルコードを実行してみてください。CSVに保存して読み込んだ中身が同じことが確認できると思います。
import sys
sys.path.append('/content/drive/MyDrive/module')
import yfinance as yf
import pandas as pd
import os
output_dir = '/content/drive/MyDrive/output/'
if not os.path.isdir(output_dir): os.makedirs(output_dir)
df1 = yf.download('VOO', period = "ytd")
df1.to_csv(output_dir +'voo_data.csv', encoding='utf_8_sig')
df2 = pd.read_csv(output_dir+'voo_data.csv', index_col=0)
print('------ VOO DATA ------')
print(df1)
print('------ CSV DATA ------')
print(df2)実習
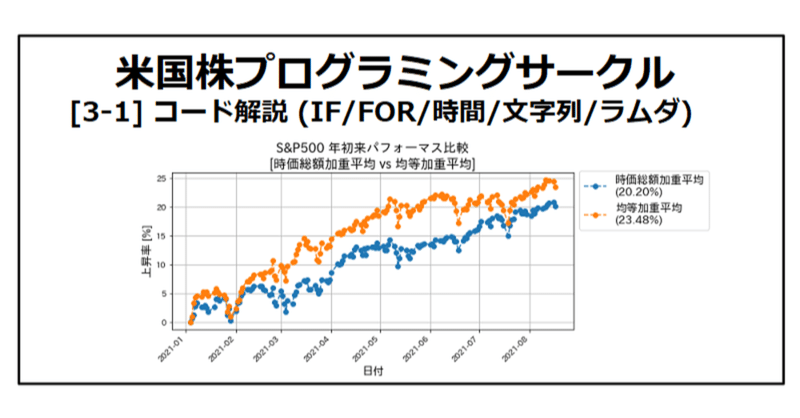
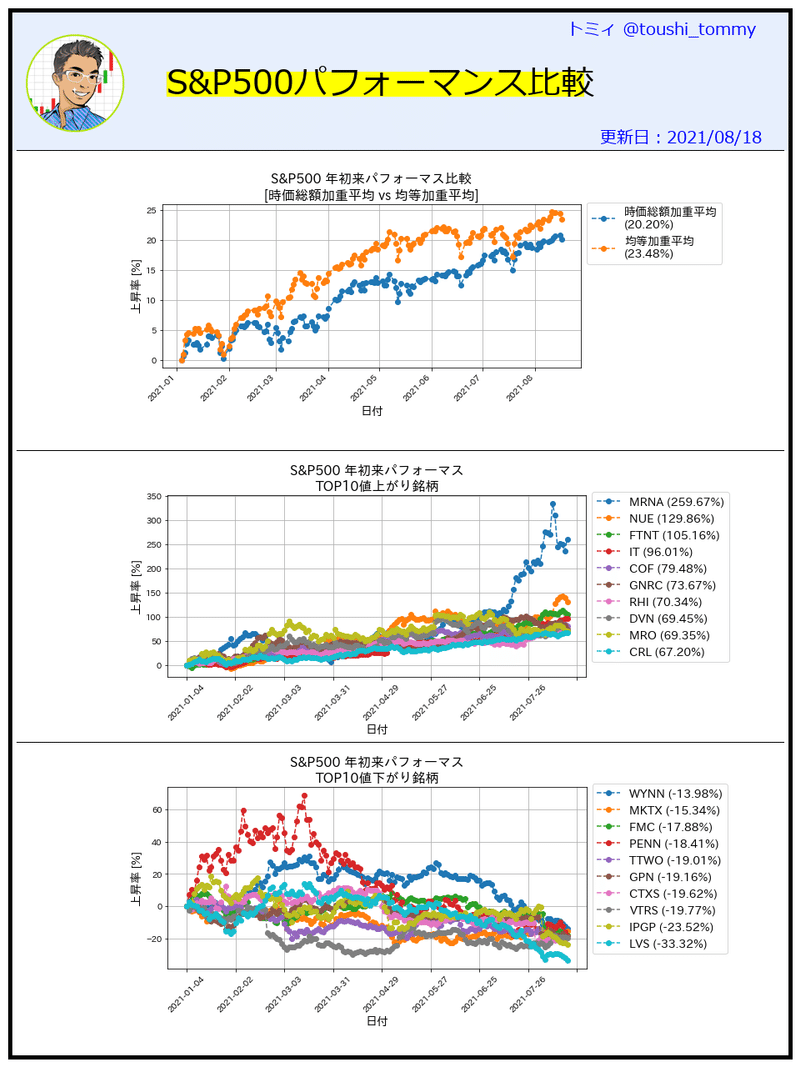
以下のコードを実行してみてください。S&P500は時価総額加重平均ですが、均等加重平均にしてパフォ―マスを比べてみました。実は均等の方が若干パフォーマンスが良いことが分かります。S&P500の銘柄すべてのデータを取得するので、実行に多少時間がかかります。また1回目でデータをCSVに保存しております。同じ日の実行の場合は2回目からはこのCSVを読み込むようにしておりますので、処理が速いです。
import sys
sys.path.append('/content/drive/MyDrive/module')
import datetime as datetime
import pytz
import yahoo_fin.stock_info as si
import yfinance as yf
import matplotlib.pyplot as plt
import japanize_matplotlib
import pandas as pd
from PIL import Image,ImageDraw,ImageFont
import IPython
import os
output_dir = '/content/drive/MyDrive/output/'
input_dir = '/content/drive/MyDrive/input/'
if not os.path.isdir(output_dir): os.makedirs(output_dir)
today = datetime.datetime.now(pytz.timezone('Asia/Tokyo'))
str_post = today.strftime("_%Y%m%d")
if os.path.exists(output_dir +'sp500_data'+str_post+'.csv'):
df_all = pd.read_csv(output_dir+'sp500_data'+str_post+'.csv', index_col=0)
else:
sp500_ticker = si.tickers_sp500()
df_all = yf.download(sp500_ticker, period = "ytd")['Adj Close']
df_all.to_csv(output_dir +'sp500_data'+str_post+'.csv', encoding='utf_8_sig')
df_all = df_all.dropna(how='all')
df_all = (df_all/df_all.iloc[0]-1)*100
df_all = df_all.dropna(how='all', axis=1)
df_all = df_all.sort_values(df_all.index[-1],axis=1,ascending=False)
df_idx = yf.download('^GSPC', period = "ytd")['Adj Close']
df_idx = (df_idx/df_idx.iloc[0]-1)*100
df = pd.DataFrame()
###############################################################################################
df = pd.concat([df_idx, df_all.mean(axis='columns')], axis=1)
df = df.rename(columns={'Adj Close': '時価総額加重平均', df.columns[1]: '均等加重平均'})
for i in range(len(df.columns)):
df = df.rename(columns={df.columns[i]: df.columns[i]+'\n('+'%.2f'%((df[df.columns[i]].iloc[-1]))+"%"+')'})
fig = plt.figure()
ax = fig.add_subplot(111)
df.plot(ax=ax,rot=45,fontsize=10,grid=True,figsize=(9,4),style='o--').legend(bbox_to_anchor=(1, 1.05),fontsize=14)
ax.set_title('S&P500 年初来パフォ―マス比較\n[時価総額加重平均 vs 均等加重平均]',fontsize=16)
ax.set_xlabel('日付',fontsize=14)
ax.set_ylabel('上昇率 [%]',fontsize=14)
plt.savefig(output_dir+'chart1.png', bbox_inches="tight")
plt.close()
###############################################################################################
# BEST 10
df = df_all.loc[:,df_all.columns[:10]].copy()
for i in range(len(df.columns)):
df = df.rename(columns={df.columns[i]: df.columns[i]+' ('+'%.2f'%((df[df.columns[i]].iloc[-1]))+"%"+')'})
fig = plt.figure()
ax = fig.add_subplot(111)
df.plot(ax=ax,rot=45,fontsize=10,grid=True,figsize=(9,4),style='o--').legend(bbox_to_anchor=(1, 1.05),fontsize=14)
ax.set_title('S&P500 年初来パフォ―マス\nTOP10値上がり銘柄',fontsize=16)
ax.set_xlabel('日付',fontsize=14)
ax.set_ylabel('上昇率 [%]',fontsize=14)
plt.savefig(output_dir+'chart2.png', bbox_inches="tight")
plt.close()
###############################################################################################
# WORST 10
df = df_all.loc[:,df_all.columns[-10:]].copy()
for i in range(len(df.columns)):
df = df.rename(columns={df.columns[i]: df.columns[i]+' ('+'%.2f'%((df[df.columns[i]].iloc[-1]))+"%"+')'})
fig = plt.figure()
ax = fig.add_subplot(111)
df.plot(ax=ax,rot=45,fontsize=10,grid=True,figsize=(9,4),style='o--').legend(bbox_to_anchor=(1, 1.05),fontsize=14)
ax.set_title('S&P500 年初来パフォ―マス\nTOP10値下がり銘柄',fontsize=16)
ax.set_xlabel('日付',fontsize=14)
ax.set_ylabel('上昇率 [%]',fontsize=14)
plt.savefig(output_dir+'chart3.png', bbox_inches="tight")
plt.close()
###############################################################################################
### 縦長まとめ画像 ############################################################################
# ここは変えてください ##
icon_img = input_dir+'tommy_icon2.png'
jap_font = '/content/drive/MyDrive/fonts/meiryo.ttc'
if not os.path.exists(jap_font):
jap_font = '/content/drive/MyDrive/module/japanize_matplotlib/fonts/ipaexg.ttf'
x_width = 960
y_width = 1280
im = Image.new('RGB', (x_width, y_width), (255,255,255))
draw = ImageDraw.Draw(im)
draw.rectangle([(10, 10), (950, 180)], fill=(231, 239, 252))
# アイコン ##########################################################
if os.path.exists(icon_img):
im.paste(Image.open(icon_img).resize((120, 120)).copy(), (30, 40))
#####################################################################
draw.line((200,100, 700,100), fill='yellow', width=30)
draw.text((200, 70), 'S&P500パフォーマンス比較', 'black', font=ImageFont.truetype(jap_font, 40))
draw.text((720, 150), '更新日:'+today.strftime("%Y/%m/%d"), 'blue', font=ImageFont.truetype(jap_font, 20))
# ここは変えてください ##
draw.text((680, 20), 'トミィ @toushi_tommy', 'blue', font=ImageFont.truetype(jap_font, 20))
draw.rectangle([(10, 10), (950, 1270)], outline='black', width=5)
draw.line((20,180, 940,180), fill='black', width=1)
im.paste(Image.open(output_dir+'chart1.png').copy(), (150, 200))
draw.line((20,540, 940,540), fill='black', width=1)
im.paste(Image.open(output_dir+'chart2.png').copy(), (150, 550))
draw.line((20,890, 940,890), fill='black', width=1)
im.paste(Image.open(output_dir+'chart3.png').copy(), (150, 900))
im.save(output_dir+'out.png')
IPython.display.Image(output_dir+'out.png')出力は以下の通りです。
課題
ダウやナスダック100で同じことをやってみましょう。ちなみにダウは si.tickers_dow()で取得可能、ダウのティッカーは^DJIになります。ナスダック100は同じく時価総額加重平均ですが、ダウは株価加重平均です。またナスダック100はyahoo finance 関数では取得できないので、自分でサイトを調べて入力する(コピペ)か、スクレイピングで取り出しましょう。ナスダック100はQQQと比較します。
本日は以上ですが、上記課題のコードの答え以下有料部分に記載します。(難しくないので、自力で作れます。もしくはサークル内で聞いていただいても答えることが可能ですので、あくまでも私にジュースをおごっていただける方のみ、ご覧ください。)
ここから先は
¥ 150
サポートいただけますと、うれしいです。より良い記事を書く励みになります!