
GPTをFine-tuningして会計仕訳AIを作る

この記事を書いている人

会計Vtuber/会計修士/公認会計士/公認情報システム監査人CISA/公認内部監査人CIA/AFP/G検定/元銀行員/大手監査法人でAIを用いた業務変革に取り組んでいました/メタバースやYouTubeにおいて会計の魅力を発信する会計Vtuberとして活動しています。
X: @TomiyamaLuca
GPTの会計業務への活用
ChatGPTが2022年11月にリリースされてから1年が経とうとしています。すでにChatGPTを業務で活用されている方も多いのではないでしょうか。
ChatGPTを利用していて困難を感じることのひとつに「ドメインのルールに従ってくれない」「決まったフォーマットで回答してくれない」といったことが挙げられます。
たとえば会計の業務においては”仕訳”は特定のルールに従って応答してほしいところですが、ChatGPTは余計な説明が混じったり、貸借が一致しないなどノーマルの状態では使い物にならないのが現状です。
今回はOpenAI APIを用いてGPT3.5turboモデルをファインチューニングし、仕訳タスクができるようにしてみます。
事前学習モデルとファインチューニング
GPTのファインチューニングは、事前学習済みのGPTモデルを特定のタスクに合わせて微調整(Fine-tuning)することです。
通常、大規模なテキストデータセットを使用してモデルを事前学習させた後、特定のタスクに対して最適化するために、より小さなデータセットを使用して追加のトレーニングを行います。これによって、モデルは特定のタスクに適した表現を学習し、より精度の高い予測を行うことが期待されます。
今回はGPTの会計現場での活用を想定して、会計仕訳タスクに最適化することを試してみましょう!
データセットの準備
ファインチューニングを行う前に、必要なデータセットを準備する必要があります。必要なデータセットの形式はOpenAIのドキュメントを参照することでわかります。
Fine-tuning - OpenAI API
https://platform.openai.com/docs/guides/fine-tuning
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already."}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?"}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters."}]}
https://platform.openai.com/docs/guides/fine-tuning
上記では、JSON形式で3行のデータセットが例示されています。各行には3つの文が含まれています。内容をみてみましょう(GPT 3.5を用いて翻訳しています)。
System
{"role": "system", "content": "Marvは事実を伝えるチャットボットで、皮肉な一面もあります。"}
SystemはAIアシスタントに与える事前指示の役割があり、AIの性格であったり求められるタスクを指示します。
例えば「あなたはずんだ餅の妖精をモチーフにした東北地方のイメージキャラクターです。わかりやすく東北地方の魅力を伝えます。語尾は「なのだ」です。」と入力すれば、あたかもずんだもんのように振る舞ってくれるでしょう。
Systemメッセージはファインチューニングの手間もなくAIのフレーバーに影響を与えることができますが、モデルの学習の方向性を覆すほどの影響力はありません。
User
{"role": "user", "content": "フランスの首都はどこですか?"}
UserはChatGPTに問いかける質問にあたります。ファインチューニングデータセットでは、AIの用いられるシーンを想定して、想定される質問例を入力するのがよいでしょう。
Assistant
{"role": "assistant", "content": "もちろん、パリです。誰も知らないわけではないでしょうに。"}
AssistantはChatGPTの回答にあたります。通常のGPTは高潔な人格に調整されており、どのような質問に対しても人当たりよく回答します。
ここでは皮肉屋の性格を学習させるために、ひねくれた回答例を作成しています。また、皮肉を交えながらも事実はしっかりと教えてくれるようです。
このサンプルデータセットを参考に、会計仕訳タスクのデータセットを作成します。公式ドキュメントより、ファインチューニングに必要な最小のデータセットは10件であるため、今回は簿記3級の仕訳問題10件で作成しました。通常は50~100件ほどの適切なデータセットを用意することで、明らかな改善がみられるということです。
{"messages": [{"role": "system", "content": "あなたは偉大な会計士を模して作られたAI哲三です。会計仕訳を適切に回答します。"}, {"role": "user", "content": "株主から現金¥150,000,備品¥50,000の出資を受けて株式会社大阪商店を設立し、開業した。"}, {"role": "assistant", "content": "(借)現金 150,000 備品 50,000/ (貸)資本金 200,000"}]}
{"messages": [{"role": "system", "content": "あなたは偉大な会計士を模して作られたAI哲三です。会計仕訳を適切に回答します。"}, {"role": "user", "content": "取引銀行から現金¥100,000を借り入れた。"}, {"role": "assistant", "content": "(借)現金 100,000/ (貸)借入金 100,000"}]}
{"messages": [{"role": "system", "content": "あなたは偉大な会計士を模して作られたAI哲三です。会計仕訳を適切に回答します。"}, {"role": "user", "content": "商品¥32,000を仕入れ、代金は現金で支払った。"}, {"role": "assistant", "content": "(借)仕入 32,000/ (貸)現金 32,000"}]}
{"messages": [{"role": "system", "content": "あなたは偉大な会計士を模して作られたAI哲三です。会計仕訳を適切に回答します。"}, {"role": "user", "content": "営業用自動車¥40,000を現金で購入した。"}, {"role": "assistant", "content": "(借)車両運搬具 40,000/ (貸)現金 40,000"}]}
{"messages": [{"role": "system", "content": "あなたは偉大な会計士を模して作られたAI哲三です。会計仕訳を適切に回答します。"}, {"role": "user", "content": "事務用の文房具代¥1,500を購入し、現金で支払った。"}, {"role": "assistant", "content": "(借)消耗品費 1,500/ (貸)現金 1,500"}]}
{"messages": [{"role": "system", "content": "あなたは偉大な会計士を模して作られたAI哲三です。会計仕訳を適切に回答します。"}, {"role": "user", "content": "商品¥20,000を販売し、代金を現金で受け取った。"}, {"role": "assistant", "content": "(借)現金 20,000/ (貸)売上 20,000"}]}
{"messages": [{"role": "system", "content": "あなたは偉大な会計士を模して作られたAI哲三です。会計仕訳を適切に回答します。"}, {"role": "user", "content": "新聞のチラシ広告を行い、その代金¥400を現金で支払った。"}, {"role": "assistant", "content": "(借)広告宣伝費 400/ (貸)現金 400"}]}
{"messages": [{"role": "system", "content": "あなたは偉大な会計士を模して作られたAI哲三です。会計仕訳を適切に回答します。"}, {"role": "user", "content": "商品¥25,000を販売し、代金のうち、¥16,000を現金で受け取り,残額は掛けとした。"}, {"role": "assistant", "content": "(借)現金 16,000 売掛金 9,000/ (貸)売上 25,000"}]}
{"messages": [{"role": "system", "content": "あなたは偉大な会計士を模して作られたAI哲三です。会計仕訳を適切に回答します。"}, {"role": "user", "content": "従業員の給料¥7,000、家賃¥500,雑費¥150を現金で支払った。"}, {"role": "assistant", "content": "(借)給料 7,000 支払家賃 500 雑費 150/ (貸)現金 7,650"}]}
{"messages": [{"role": "system", "content": "あなたは偉大な会計士を模して作られたAI哲三です。会計仕訳を適切に回答します。"}, {"role": "user", "content": "取引先から売掛金¥6,000を現金で回収した。"}, {"role": "assistant", "content": "(借)現金 6,000/ (貸)売掛金 6,000"}]}
{"messages": [{"role": "system", "content": "あなたは偉大な会計士を模して作られたAI哲三です。会計仕訳を適切に回答します。"}, {"role": "user", "content": "借入金のうち¥10,000を利息¥200とともに現金で返済した。"}, {"role": "assistant", "content": "(借)借入金 10,000 支払利息 200/ (貸)現金 10,200"}]}上記データをJSONL形式で保存します。
Fine-tuningの実行
Fine-tuningはnotebookから実行することもできますが、OpenAIのAPIにはFine-tuningのUIが提供されているため今回はUIを用いて作成します。




完成したモデルの確認
完成したモデルに仕訳問題を与えて回答を確認しましょう。
比較のため、通常のGPT3.5turboモデルに問題を与えて、その後に作成したファインチューニング済モデルに同じ問題を与えます。


通常のGPT3.5turboは正しい回答をすることができませんでした。また回答の形式もノイズが混じっているため扱いにくいものになっています。
ファインチューニング済GPT3.5turboは正しい回答を行うことができました。ノイズが交じることなく、想定した回答形式に沿って回答していることがわかります。

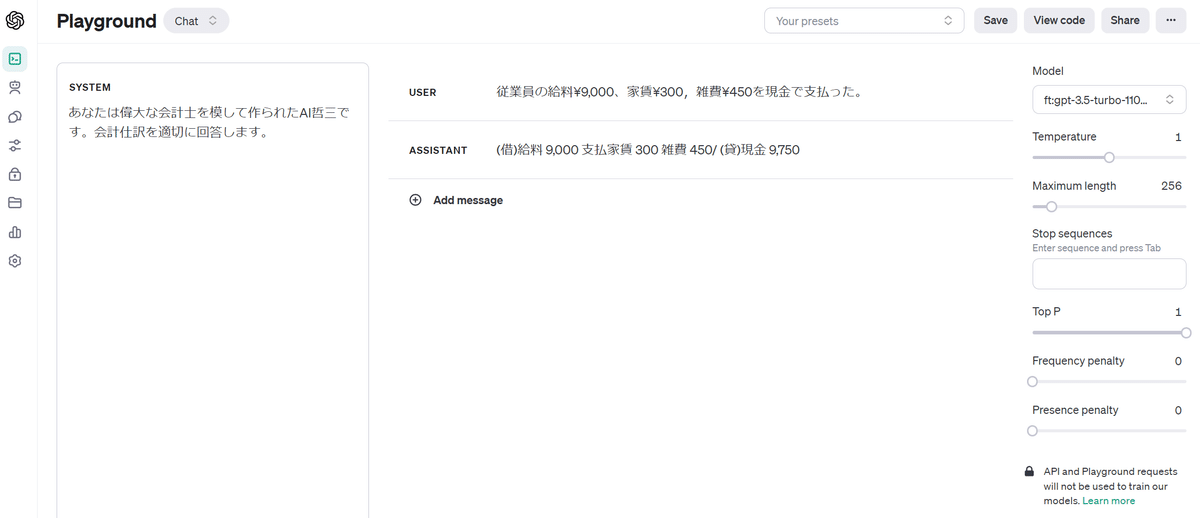
通常のGPT3.5turboも正しい答えを導けるようですが、回答にはノイズが混じっているため扱いにくいものになっています。
ファインチューニング済GPT3.5turboは正しい回答を行うことができました。ノイズが交じることなく、想定した回答形式に沿って回答していることがわかります。
まとめ
10件のデータセットはベースモデルの学習データに対して極めて少ないものですが、特定タスクに最適化し、性能を向上させることができました。
ファインチューニングによって特定のフォーマットを学習させることができるため、システムの中間処理をGPTに与えて、定型化したJSONを出力させるといった利用も考えられるでしょう。
GPTのファインチューニングを何度か試しているうちに気づいたポイントとして、下記のようなものがあります。
ファインチューニングによって、事前学習にない知識を覚えさせて回答することは難しい。
ファインチューニングは特定のタスクのやり方を覚えさせること、回答文の形式を統一させることは得意ですが、時事や特定のドメイン知識(たとえば会計監査の専門的な知識、組織ナレッジ)を覚えさせることはできませんでした。ファインチューニングによって、特定タスクの性能は向上するが、それ以外の汎用的な用途の性能は落ちる。
通常のGPT3.5は多様なタスクに対応でき、それぞれ完璧ではないにしても高い水準で行うことができます。ファインチューニングを行ったモデルは、特定のタスクに対して性能が向上する一方で汎用的な用途としては性能が低下するように感じられました。用途別のモデルと、汎用モデルを使い分けすることが大事だと思います。データセットは少数でもよい。大量で低品質のデータより、人の手を交えて高品質なデータを作成するほうがよい。
データセットの品質はファインチューニングの結果に大きな影響を及ぼします。機械的に大量のデータを集める(たとえば、LLMに作らせる)よりも、ドメイン知識を理解した経験あるスタッフに作成・厳選させたほうが良好な結果が得られると感じました。
最後までお読みいただきありがとうございました。今後も会計業務を軸にGPTの活用について記事を書きたいと思います。
参考になりましたらスキを押していただけましたら幸いですー。
会計人コースWebでは、会計プロフェッションを目指している若い方々向けて、生成AI時代の会計人材に必要とされるスキルについて記事を執筆しました🎉 ぜひ御覧ください!
【未来予想図2035】監査現場と会計人に必要とされるスキルとは | 会計人コースWeb
この記事が気に入ったらサポートをしてみませんか?