徒然なるままに論文を読んでみた#3

こんばんは。今日も面白そうな論文をシェアしていきます。その前にちょこっと自己紹介↓
東京大学教養学部理科三類所属の学生です。生成AI・バイオ(代替タンパク質・分子生物学・細胞生物学・合成生物学)・経営・国際政治分野を勉強してます。医学で言えば分子医療とか再生医療、人機融合みたいなところが興味範囲ですかね。
今はAIの波が凄すぎて、「今しかない!」と思い立ち、AIを推進してちょっとでも日本に貢献できたらいいなと思いAIに重点おいてる人間ですが、バイオに触れることでしか得られない栄養素があるので、定期的に触れようとモチベーションを保つために始めました。
ですが今回はGoogleによるGeminiの発表を受け、バイオ全く関係ないですが、Geminiをできる限りまとめたいと思います。
ChatGPT研究所さんの記事とも併せて読めば、Geminiマスターになれること間違いなしです!
本日の論文
Gemini Team, 2023, Gemini: A Family of Highly Capable Multimodal Models
今夜私が読みますのは、Google社のGeminiの技術レポです。技術レポとはいえ、どちらかというとプロモーション強めな論文でした。
Geminiの概要
Googleの秘蔵っ子マルチモーダル生成AI
2023年5月に開発中との告知がありましたが、開発遅延の噂もある中でのサプライズ発表となりました。
広報用の機能比較の表では、わざわざ比較対象としてChatGPT-4/4Vと明記。ライバル視するのは当然ですが、GAFAで大勝負の時に採られてきた狙い撃ち戦略だと捉えられます!
技術論文では、開発メンバーに伝説のGoogle共同創業者・Sergay Brinが入っていることが確認できます!
紹介記事では、Alphabet社のCEO:Sundar PichaiとDeepMind社のCEO・Demis Hassabisの共著として発表しました!
なお、Geminiは「双子座」の意味で、英語発音は「ジェミナイ」のようになりますが、実際には統一されていないようで、日本語名称としては「ジェミニ」を用いるらしいです。今後どちらで表記・発音するかは個人の好みが大きく出ると考えています。
3つのタイプで公開される
Geminiは、学習時のパラメータの大きさや調整の違いにより、3つの型:Ultra・Pro・Nanoに分類されます。モデルとしての機能は、LLMのScaling Law(J. Kaplan et al. 2020)の例に漏れず、Ultra>Pro>Nanoとなっているそう(下図)。
Ultra:最も高い性能を持ち、高度に複雑なタスクを高精度で熟す。
現在は公開はされていないが、2024年初を目安にBard Advance(有料版)に搭載される予定。 API提供も12月半ばよりベータ版として開始、2024年初により大規模に展開される予定。Pro:汎用的で、コスパの良いモデル。
2023年12月8日時点で、Googleの言語設定が英語の場合のBardは、モデルがPaLM2からGemini Proに置換済み。12月半ばよりAPI提供開始。 検索サービスや広告・Chrome・Duet AIに展開予定。Nano:モバイルデバイスで扱うための軽量モデル。
Gemini Pro等の大きいGeminiモデルを蒸留することで訓練されている。モデルサイズはパラメータ数18億・32.5億の2種類用意されている。 Pixel 8 Proに最初に実装され、端末上で会議の録音・文字起こし・要約などが可能になる。
※大きなLLMの予測を教師データとして、より小さなモデルの訓練に利用することでより小さな言語モデルに知識を移転する技術を蒸留(distillation)という。

Geminiの使い方
2023年12月8日時点では、Googleの言語設定を英語にし、Bardを開くことで、無料でGemini Proを扱うことができます。多言語対応しているので、日本語も十分に理解します。
Geminiの機構
デコーダ構成のTransformerベースマルチモーダル生成AI
2017年に記念碑的論文(A. Vaswani et al., 2017)で発表されたTransformerを今回も活用。GPTと同じくデコーダ構成のTransformerを利用しているよう。
Gemini models build on top of Transformer decoders (Vaswani et al., 2017) that are enhanced with improvements in architecture and model optimization to enable stable training at scale and optimized inference on Google’s Tensor Processing Units. They are trained to support 32k context length, employing efficient attention mechanisms (for e.g. multi-query attention (Shazeer, 2019)).

エンコーダ・デコーダ構成の場合、エンコーダにおいて入力のプロンプトに対して、各単語(正確にはトークン)間の関係性をAttention機構で評価し、その文脈理解に基づいて、デコーダで出力文章の次の単語の予測を行います。
例えば、「私はパンツです。」の翻訳タスクの場合、まず入力「私はパンツです。」をトークンに分割し(「私 | は | パンツ | です | 。」)、各トークンをベクトル化(単語埋め込み)するとともに文章の中での位置を情報を含んだベクトルを足し合わせる(位置埋め込み)ことで生成したベクトルを、エンコーダにかけて学習させます。その上で、エンコーダでの文脈理解に基づき、出力の文章をトークンごとに先頭から構成していきます。確率計算により、次の単語に最も相応しい単語を並べていきます(”I” → ”I am” → ”I am a” → ”I am a panty” → ”I am a panty.”)。
GPTやGeminiのようなデコーダ構成のモデルは、左の図からエンコーダ部分を除いたものです。デコーダ構成のモデルは、自然言語処理において、特に要約や対話、翻訳といったタスクを得意とすることが知られています。一方、BERTやRoBERTaのようなエンコーダ構成のモデルも存在し、こちらは文書分類や系列ラベリングといったタスクに向いています。
Transformerについては、以下の解説記事がわかりやすいです。適宜参照ください。
なお、テキストのトークン化においては、定番のSentencePiece(T. Kudo & J. Richardson, 2018)を用いているそう。
生まれながらにしてマルチモーダル
We designed Gemini to be natively multimodal, pre-trained from the start on different modalities. Then we fine-tuned it with additional multimodal data to further refine its effectiveness. This helps Gemini seamlessly understand and reason about all kinds of inputs from the ground up, far better than existing multimodal models — and its capabilities are state of the art in nearly every domain.
マルチモーダリティ(Multimodality)とは、複数の情報の形式(テキスト、音声、画像、動画等)を組み合わせて処理することを指します。ChatGPT等では、画像と文章をセットで入力する(例:「この画像の内容を説明して。」)ことができますが、そのような入力に対応しているLLMを、マルチモーダルなLLMと呼びます。
GPT-4/4Vは、画像や音声等にも対応しているマルチモーダルモデルで、精度も十分です。GPT-4/4V含め、Gemini以前のマルチモーダルモデルでは、テキストはテキスト、画像は画像と、各モダリティごとに事前学習し、それを統合して複数のモダリティに対応させる形式が取られてきました。一方、Geminiでは、最初からモダリティごとに分離することはせず、複数のモダリティをいっぺんに扱って事前学習しているようです。”Natively Multimodal”に設計することによって、画像認識等において極めて高い精度を出せるように訓練されています。

その結果、テキストだけではなく、画像・動画・音声等でも最高性能を叩き出し、32個の評価指標のうち、30で圧倒的精度を示しています(後述)。
Geminiの性能:テキスト

Geminiは非常に高いテキスト性能を有し、推論力も高いです。様々な言語モデルと比較しても、12個のテキストに関する指標のうち、10個で最も高い精度を獲得しています(なお、残りの2指標ではGPT-4の方が高い性能を示している)。特筆すべきは、MMLU・GSM8K・MATHです。
On MMLU (Hendrycks et al., 2021a), Gemini Ultra can outperform all existing models, achieving an accuracy of 90.04%. MMLU is a holistic exam benchmark, which measures knowledge across a set of 57 subjects. Human expert performance is gauged at 89.8% by the benchmark authors, and Gemini Ultra is the first model to exceed this threshold, with the prior state-of-the-art result at 86.4%.
MMLU(Massive Multitask Language Understanding; D. Hendrycks et al., 2021a)は、自然科学(STEM分野)・人文科学・社会科学等の57のタスクをカバーしており、自然言語処理のマルチタスク能力を測る指標です。この指標では、89.8%が人間の専門家の測定値となるのに対し、Gemini Ultraは90.04%のスコアを出しました。MMLUで高いスコアを推論力に限らず、幅広い分野の十分な知識が必要です。文章理解力や人間を超えるスコアを出したのはこれが初めてとのことだが、驚異的です。
なお、MMLUでのパフォーマンスは、chain-of-thought prompting(J. Wei et al., 2022)という技術を用いることで向上するそう。k個のchain-of-thoughtを生成して、基準となる閾値を超えた確信を得たものを出力として選択し、閾値を超えない場合は、chain-of-thoughtを破棄して最大尤度選択に基づく貪欲法に戻る(=一番それらしいのを確率で選ぶ)という回答選択プロセスを踏んでいます。
数学的推論能力も、GSM8K(K. Cobbe et al., 2021)やMATH(J. Hendrycks et al., 2021b)でのスコアで評価し、他のモデルと比べて最高の性能を出しています。ただし、数学力については、初等数学レベルの簡単なものであれば正答率が94.4%と高いが、大学入試レベルのやや複雑な数学問題となると53.2%と、依然LLMの課題である数学力の低さは解決されていないです。また、Gemini UltraとGemini Proとの数学力の差も顕著であり、Gemini Proでは精度の高い数学的推論は見込めません。
その他、多言語との翻訳や、長い文脈の理解、プログラミング等でも高い評価を得られたことが記載されています。例えば、プログラミングにおいては、Gemini ProベースのAlphaCode2が、複数のコンペの成績をまとめるとTop15%に入るとされています。
Geminiの性能:マルチモーダリティ
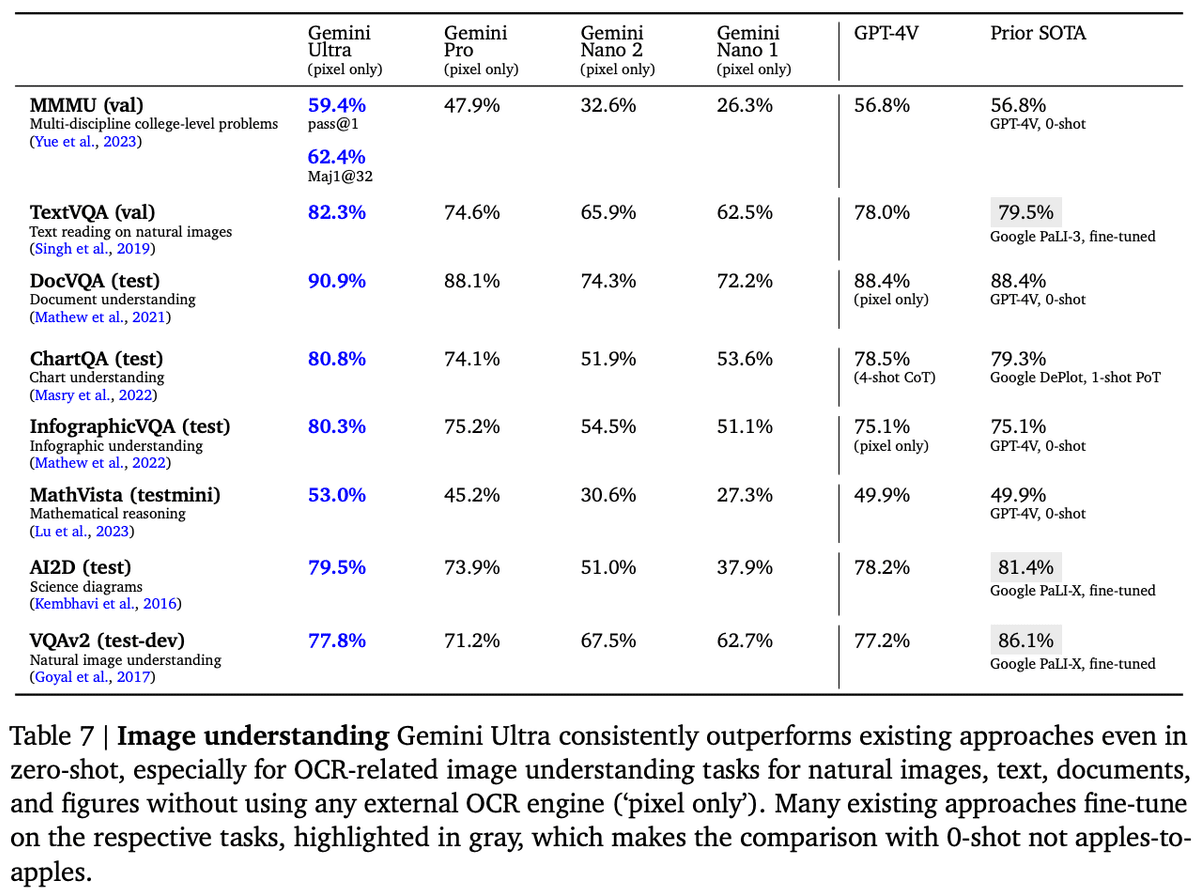


Geminiは、テキスト以外の分野でも非常に高い評価を獲得しています。画像認識においては、9個の指標のうち全てで最も高い評価を獲得しました。比較的新しい指標のMMMU(Massive Multi-discipline Multimodal Understanding; X. Yue et al., 2023)では、Art & Design・Business・Science・Health & Medicine・Humanities & Social Science・Tech & Engineeringの6つの専門分野に対して、大学レベルの試験・クイズ・教科書から取り出したマルチモーダルの問題に答える能力を測り、非常に高いスコアを出しています。また、画像中の言語は、英語以外であっても認識できることが示されています。
論文中で紹介されているデモ例も、その画像認識能力を存分に伝えており、実際に筆者が使用してみても、その能力はGPT-4Vを凌駕している感覚があります。このような高度な画像中の文字認識を、外部のOCRツールを使うことなく実現しているのが驚き。


また、GPT-4Vでは現状難しいこととして、image2imageの変換があります。しかし、Geminiでは、画像の入力に対し、適切な推論を踏まえて画像を返す能力があります。
その他、動画や音声の認識でも極めて優秀なスコアを出しており、それぞれ6個、5個の指標のうち全てで最も高い性能を示しています。
Gemini開発上のガバナンス
AI Alignmentが頻りに提唱されるようになり、ちゃんと気にしてますよというアピールも論文中にあります。内容としてはそんなに濃くないので割愛。
Geminiでできること
Geminiのデモ動画
6分ほどに亘るこの映像では、Gemini Ultraの文脈・状況・画像認識能力や、推論力の高さが余すところなく伝えられている。ぜひ一度ご覧になることをお勧めする。
なお、このデモ動画自体はフェイクとの指摘もある。実際にはリアルタイムで動くのではなく、いちいちプロンプトを入力する必要があるとのことで、この動画は誇大だとの指摘。
その他のデモ動画
数学・力学の解法を評価することもできるほどの論理性・状況認識能。
プログラミングでも、Top15%ほどの実力は最低限持っているとのこと。
画像をコードに落とし込むことも可能、最初のデモがすごくチープなことが面白い。
動画の続きを予測することも可能、ストーリーラインの理解でも高機能を発揮
注意ポイント
Geminiは"頑固"
Gemini発表から数日が経ち、アーリーアダプターたちによるユースケース報告が様々な媒体で報告されるようになりました。そして、特に報告が相次いでいる(そして僕自身使っていて感じた)特徴として、「Geminiはハルシネーションが起こりやすく、かつ誤りを指摘しても頑として認めない」ということが指摘されます。ChatGPT-4/4Vは、もちろんハルシネーションは起こる一方、間違いを指摘すると訂正してくれるのでイライラは少ないのですが、Geminiはあまりにも頑固かつ自信満々なので、ちょっと困っちゃいます。


若干Googleの焦りが感じられますね。もしかしたら開発遅延説は本当で、ただ指標はとりあえず良かったので出しましたという感じでしょうか。ハルシネーションの酷さといい、デモの誇張といい、Googleの焦りがGeminiへの不審に繋がらないか心配です。
とはいえ、それなりに使ってみましたが、画像認識能は明らかにChatGPT-4Vを凌駕していますし、出力の詳細さも、ChatGPT-4に遜色ないと感じています。Googleは検索ツールからデバイス、その他のIT環境を全て握っているので、Geminiの機能が調整されれば、生成AI時代の覇権を引き続き握る可能性もあります。IT業界の動向から目が離せませんね!!