シェア
npaka
2023年4月28日 07:59
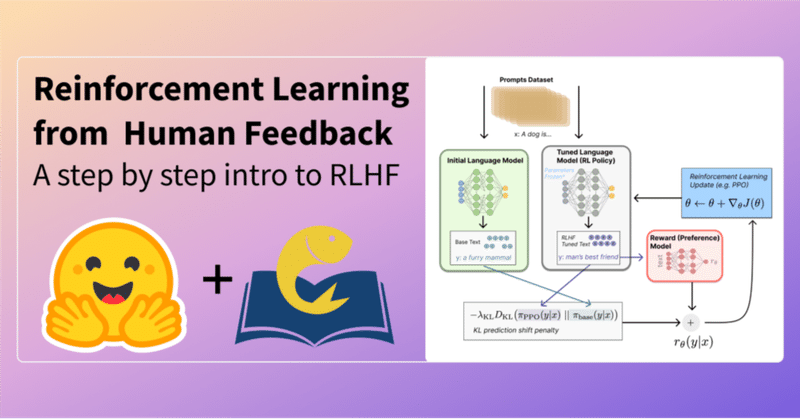
以下の記事が面白かったので、軽く要約しました。1. はじめに言語モデルは、人間の入力プロンプトから多様で説得力のあるテキストを生成することで、ここ数年、目覚ましい成果をあげています。しかし、「良い」テキストかどうかは、主観的で文脈に依存するため、定義することが困難です。「良い」テキストを生成するための損失関数の設計は難しく、ほとんどの言語モデルは、まだ単純な次のトークン予測損失(クロスエン
2023年4月16日 21:01
以下の記事を元に、「OpenAI API」のファインチューニングの学習データのガイドラインをまとめました。1. 学習データの書式ファインチューニングするには、単一の入力「プロンプト」とそれに関連する出力 「コンプリーション」 のペアで構成される学習データが必要です。これは、1回のプロンプトで詳細な手順や複数の例を入力するような、ベースモデルの使用方法とは大きく異なります。「学習データの書式
2023年4月5日 06:35
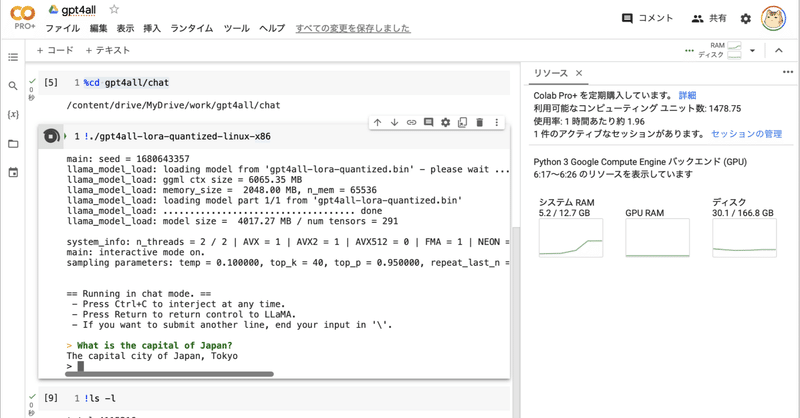
「Google Colab」で「GPT4ALL」を試したのでまとめました。1. GPT4ALL「GPT4ALL」は、LLaMAベースで、膨大な対話を含むクリーンなアシスタントデータで学習したチャットAIです。2. Colabでの実行Colabでの実行手順は、次のとおりです。(1) 新規のColabノートブックを開く。(2) Googleドライブのマウント。Colabインスタンスに