タニタ機器との連携アプリ「Health Planet」蓄積データをエクスポートするやっつけ Python アプリ 作った

はじめに
【注意】
本noteで公開している内容を利用する場合は自己責任で実施してください。
ノーサポートノークレームでお願いします。不具合等の対応を行うことはできません。不明点に対する質問対応もできないと思ってください。
概要
タニタの各種機器と連携しているアプリケーション「ヘルスプラネット」ではデータの蓄積を自動実施する機能があります。しかし、蓄積されたデータはアプリ内部でしか確認できず、一括したデータダウンロード・エクスポートができません。
おそらく、課金するかサードパーティー製(パートナーサイト)のアプリを使う、など何らかの方法でデータ取得できるのでしょうがそれは嫌なので、公開されている OAuth2 API を無理やり使って自分でデータ(今回は血圧データ)を取得してみました。
例外処理等はまるでなし、デバッグ丸出しで、商用利用できるレベルまで作りこんでいないのでコード丸ごと公開してしまいます。
それなりに開発関連の知識があって、ヘルスプラネットを使ってる、というニッチな層にだけしか刺さらないでしょうが、良ければ使ってください。
なお、本実装時の参考として以下サイトから部分的にコードをコピーさせていただいています。ありがとうございます。
事前準備
開発&実行環境
自作アプリを実行する環境を作ります。
今回、私は Python3.11系 + venv + VSCode を使っています。
Python環境を作成する際、パッケージインストールのために下記requirements.txtを作成します。
requests
oauthlib
requests-oauthlib
上記の requirements.txt を使って pip によりパッケージインストールを行います。
> pip install -r requirements.txt
Health Planet側の準備
本noteを読んでいる方は、既に Health Planet を利用されていると思いますのでアカウント作成は済んでいるものとします。
データを一括取得するためには、アカウントだけではなく「サービス連携」の登録が必要になります。登録情報画面の下記赤枠のリンクから登録します。

次に、サービス連携登録画面で「アプリケーション開発者の方はこちら」を選択します。

今度は、「APIの設定」の画面になります。アプリケーション未登録の状態では「戻る」「新規登録」のみが表示されるはずなので「新規登録」を選択します。

登録するアプリケーションの情報を入力します。今回はコンソールから実行するアプリケーションなので、「アプリケーションタイプ」は「クライアントアプリケーション」を選択します。その他はご自分の情報を入力してください。
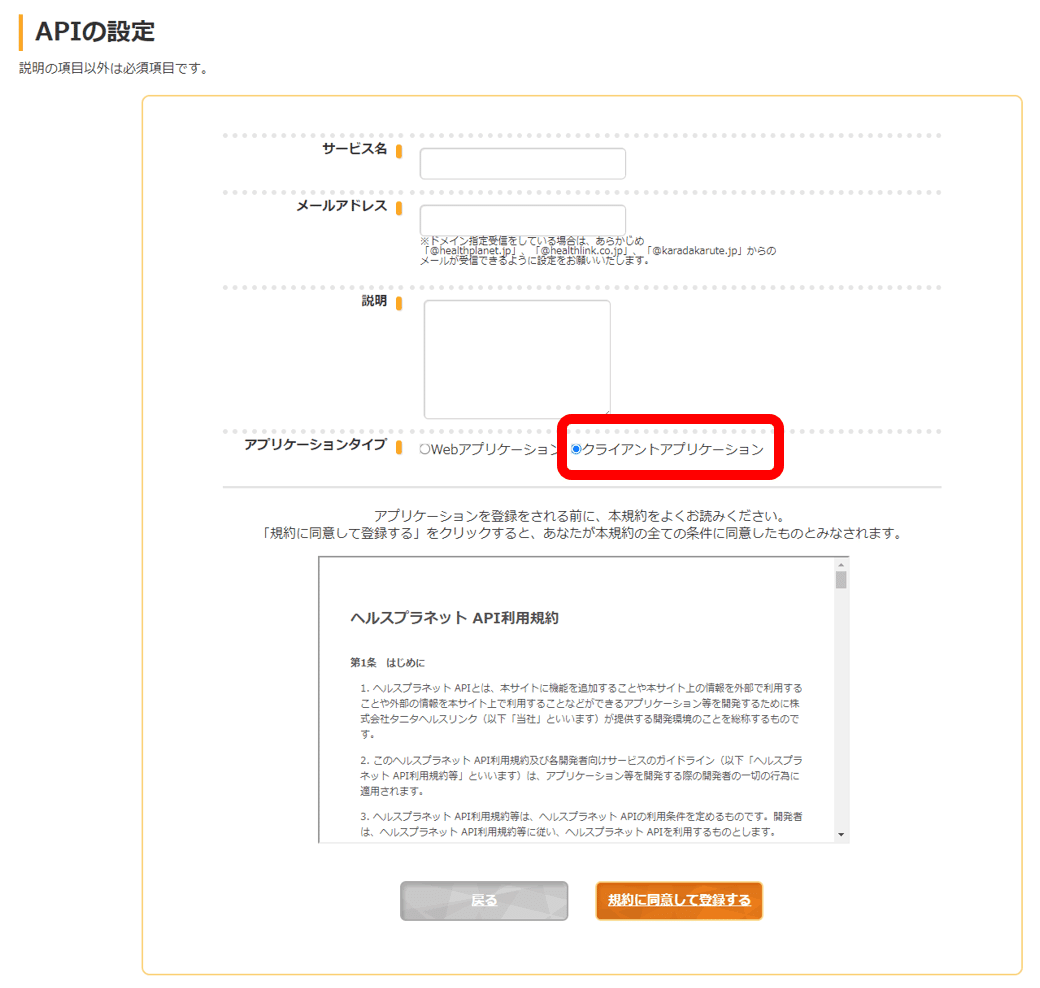
登録が終わると「Client ID」「Client secret」が表示されるので情報をメモしておきます。
コード実装
今回のアプリケーションのコードは下記の通りです。
コード中の 9行目、10行目に定義されている変数の値として、事前に取得した Client ID, Client secret をコピペします。
import os
import json
import requests
import xml.etree.ElementTree as ET
from datetime import datetime
from requests_oauthlib import OAuth2Session
# OAuth2の認証情報をセットアップ
CLIENT_ID = '■■■■自分で取得した ID■■■■'
CLIENT_SECRET = '■■■■自分で取得した SECRET■■■■'
REDIRECT_URI = 'localhost'
REQUEST_SCOPE = 'innerscan,sphygmomanometer'
AUTHORIZATION_SERVER_BASE_URL = 'https://www.healthplanet.jp'
AUTHORIZE_URL = f'{AUTHORIZATION_SERVER_BASE_URL}/oauth/auth'
TOKEN_URL = f'{AUTHORIZATION_SERVER_BASE_URL}/oauth/token'
SPHYGMOMANOMETER_URL = f'{AUTHORIZATION_SERVER_BASE_URL}/status/sphygmomanometer.xml'
RESULT_OUTPUT_DIR = "result"
def fetch_token():
session = OAuth2Session(
client_id=CLIENT_ID,
scope=REQUEST_SCOPE,
redirect_uri=REDIRECT_URI
)
authorization_url, state = session.authorization_url(AUTHORIZE_URL)
print("\n\n■■■■■■\nURLをブラウザにコピペし、認可コードを取得してください:")
print(authorization_url)
print("\n\n")
code = input("表示されている認可コードをコピペしてください: ")
url = "https://www.healthplanet.jp/oauth/token.?client_id=" + CLIENT_ID + "&client_secret=" + CLIENT_SECRET + "&redirect_uri=localhost&code=" + code + "&grant_type=authorization_code"
response = session.post(url)
return response.text
def fetch_resource_server(token):
url = SPHYGMOMANOMETER_URL + "?access_token=" + token + "&tag=622E,622F,6230"
response = requests.get(url)
return response.text
def parse_xml(xml_str):
root = ET.fromstring(xml_str)
data_dict = {}
for data_elem in root.findall('data'):
date_elem = data_elem.find('date')
date = date_elem.text
if date not in data_dict:
data_dict[date] = {}
if data_elem.find('tag').text == "622E":
key = "最高血圧"
elif data_elem.find('tag').text == "622F":
key = "最低血圧"
elif data_elem.find('tag').text == "6230":
key = "脈拍"
else:
key = "不明"
data_dict[date][key] = data_elem.find('keydata').text
str_array = []
for key_date, result_dict in data_dict.items():
date_result = key_date + ","
if "最高血圧" in result_dict:
date_result = date_result + result_dict["最高血圧"] + ","
else:
date_result = date_result + ","
if "最低血圧" in result_dict:
date_result = date_result + result_dict["最低血圧"] + ","
else:
date_result = date_result + ","
if "脈拍" in result_dict:
date_result = date_result + result_dict["脈拍"]
else:
date_result = date_result
str_array.append(date_result)
return str_array
def array_to_file(str_array):
if not os.path.exists(RESULT_OUTPUT_DIR):
os.makedirs(RESULT_OUTPUT_DIR)
now = datetime.now()
out_file = now.strftime("%Y%m%d%H%M%S") + ".txt"
out_path = os.path.join(RESULT_OUTPUT_DIR, out_file)
absolute_path = os.path.abspath(out_path)
print("\n\n")
print(absolute_path, " に結果を出力します")
with open(out_path, 'w') as file:
# 配列の要素を改行区切りでファイルに書き込む
for item in str_array:
file.write(item + '\n')
def main():
# トークン類の取得
token_str = fetch_token()
token_json = json.loads(token_str)
token = token_json["access_token"]
# リソースサーバよりデータを取得
response_body = fetch_resource_server(token)
#ヘルスプラネットが返却する生のXMLデータを確認するならここでprint
#print("start ###########################")
#print(response_body)
#print("end #############################")
ret_array = parse_xml(response_body)
#出力内容を printするならここで
#print(*ret_array, sep='\n')
array_to_file(ret_array)
if __name__ == '__main__':
main()コードの説明
概要
基本的に、このコードはエラーハンドリングなどしていないので、コードでやりたいことをちゃんと読んで理解してから実行してもらいたいです。
概要だけ説明します。
本コードを実行すると、以下の順に処理が進みます。
main() から処理を開始
fetch_token() でアクセス時に必要なトークン情報を払い出す
fetch_resource_server() で血圧データを取得(期間指定していないのでデフォルトの3か月)
parse_xml() で取得した XMLデータを加工して CSVデータの文字列配列にする
array_to_file() で結果をファイルに出力する
トークン払出イメージ
項番2の fetch_token() をプログラム実行する際、ユーザ操作が必要になります。具体的には、プログラムで生成した URLをブラウザに貼り付け、認証後に表示されるトークンをコンソールにコピペして入力します。

トークン取得作業を行ったブラウザで事前にHealthPlanetログイン済ではない場合、ログイン画面が表示されます。APIキーを取得したアカウントでログインしてください。
ログイン状態のブラウザでは、次に以下のアクセス許可画面が表示されます。

アクセス許可画面で「アクセスを許可」を選択すると、処理を進めるために必要なトークン(コード)が発行されます。

上記画面で黒塗りになっている箇所にコードが表示されます。このコードをプログラムを実行しているコンソールにコピペします。
出力ファイル
プログラム実行時に異常がなく完了した場合、プログラムを実行したフォルダに「result」という名前のサブフォルダを作成して結果ファイルを出力します。
出力ファイルは YYYYmmddHHMMSS で日付を表した文字に「.txt」の拡張子を付与して出力されます。
出力データサンプルは下記の通りです。
202306191047,121,70,58
202306191045,119,79,61
202306182359,113,74,72
この場合、
「測定日時」,「最高血圧」,「最低血圧」,「脈拍」
の順番でデータが出力されます。
データの出力順についてはプログラム中で自由に定義してください。
このようにCSV形式でファイルを出力しておけば、あとは Excel等で自由自在、ですね。
Health Planetドキュメント関連
APIの仕様については Health Planet本家サイトを参照してください。今回は血圧データをダウンロードしましたがその他のデータも対応されているはずです。また、期間指定なども可能です。
ドキュメントはHealth Planetサイト下部にあるフッター「APIの設定」からリンクが貼られています。

リンク先のサイトはこちらになります。
さいごに
今回、このアプリはヘルスプラネット事務局さんに問い合わせた結果、「データエクスポート機能がない」「WEB版を含めて、日別のデータ表示のみ」という残念な回答を受けたために作成しました。入力データがWEB上で一括表示されているなら、それをクロールしても良かったんですが。
各種ハードウェアからデータを自動連携して表示する、というアプリがHealthPlanetですが、そのデータが使えるのはアプリ内のみ。外部にデータを出力するための自由な手段がない、というのは、使い始めないと中々気づかないのではないかと思います。
時系列の測定データを第三者と連携する(無料かつ簡便な)出力機能は最低限展開されて良い機能なのではないでしょうか、、?
タニタ製の機器を購入して、測定して、自分のデータをアップロードしているのにそれがダウンロードできないとは、、。
是非、本家サイトで簡便なエクスポート機能を実装していただきたいものです。
この記事が気に入ったらサポートをしてみませんか?