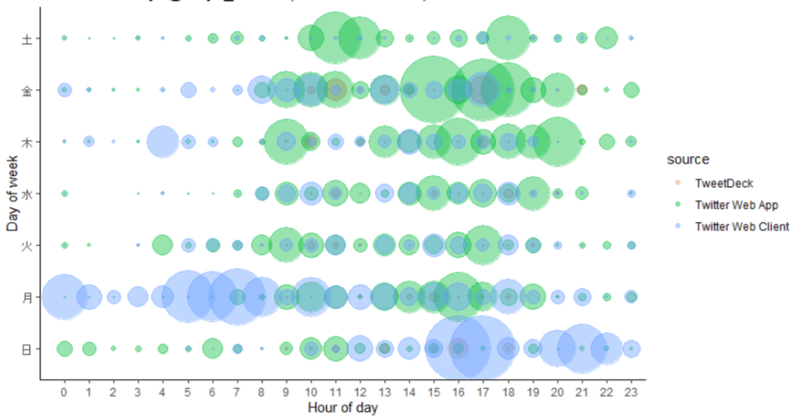
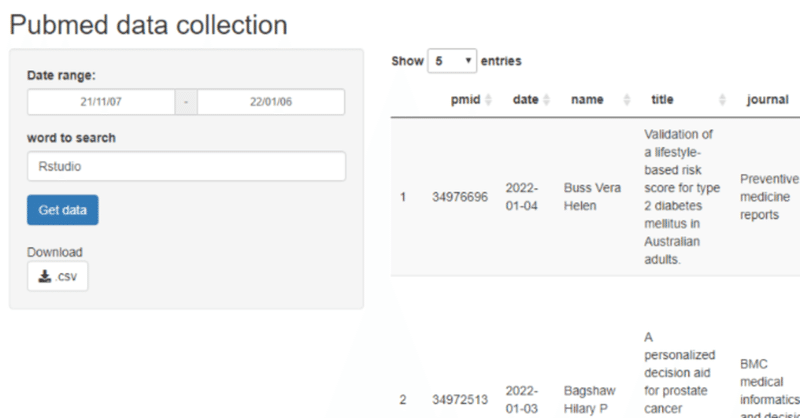
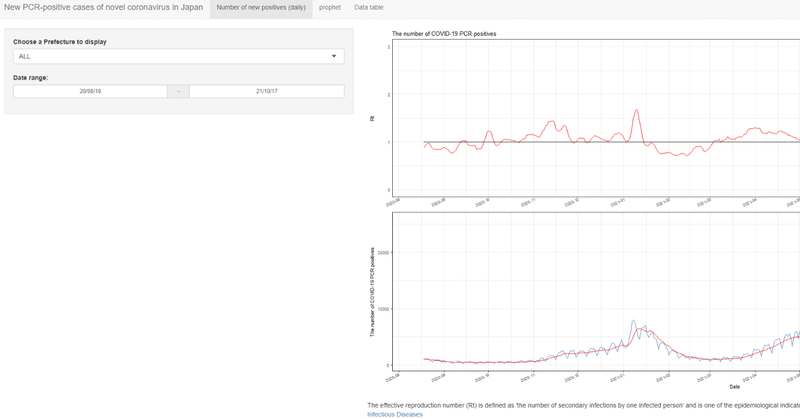
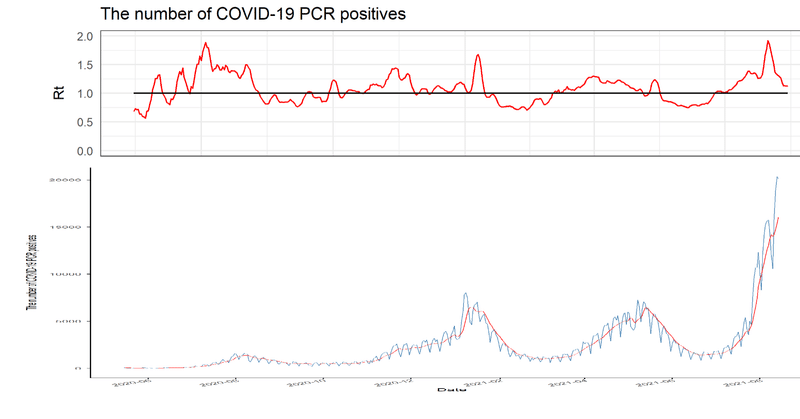
最近の記事







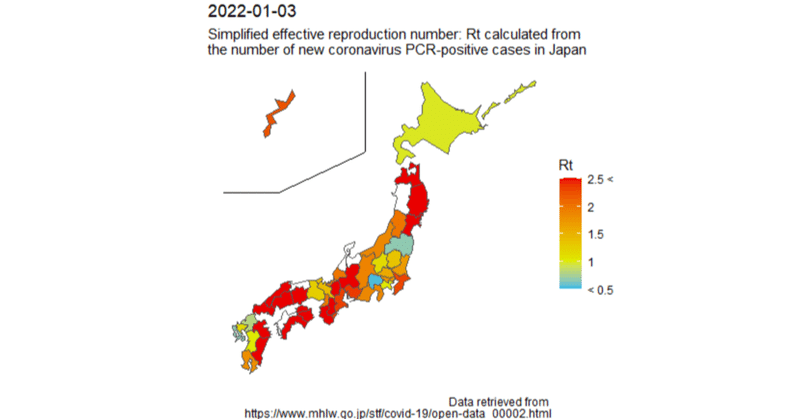
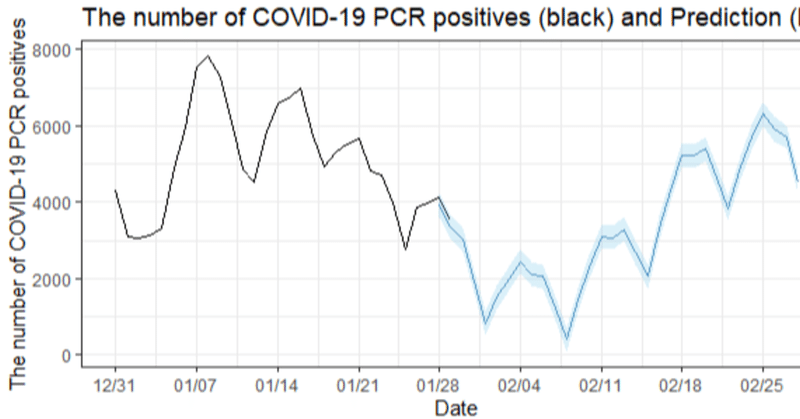
【R/ggplot2】Visualization of the simplified effective reproduction number (Rt) of the number of new coronavirus positive cases by prefecture on a map of Japan.
I would like to visualize the increase or decrease of the number of new coronavirus positive cases in Japan at the regional level. Therefore, I visualized the simplified effective reproduction number (Rt) of the number of new coronavirus-p