
【好き勝手DIG】データベース_NoSQL編

前回はデータベース, つまりはデータ管理のツールの変遷を追ってきた。加えてRDBの成り立ち, 進化の前提を頭に入れることができた。
RDBは構造化を原則としてデータ群をモデリングして効率的に∧人にわかりやすくデータ管理することに長けている。一方で逆の概念, 逆を指し示す言葉としてNoSQLがある。これが何者なのかが気になっているのでググってみた。
RDB(リレーショナル・データベース)の限界
RDBの限界が顕在化した背景は、インターネット台頭など1990-2000年代にかけてRDB開発当初想定していた「データベース」に求められる要求が変わってきたこと。
具体的な課題はパフォーマンス(性能と信頼性のトレードオフ), 非構造データモデル台頭(構造化データ以外への要求の高まり) である。
参考:RDBとNoSQLにみるDB近現代史 データベースに破壊的イノベーションは二度起きるか?
RDBのパフォーマンス問題(性能と信頼性のトレードオフ)
RDBはデータ管理に厳密である。データ完全性を確実にするために、厳密な(ACID特性に基づいた)トランザクション処理を前提とする。ゆえに基本的にデータは一元管理となり、ストレージ(データ保管先)を共有するインフラ構成となる。そうなるとスケールアウト(ロードに応じてストレージを増殖)がしにくいという問題が発生する。現代のデータ量の二次関数的な増加, データの重要性の高まりに課題として顕在化された。
RDBは関係(一般的にはテーブル, 表)をSQLによって結合して新しい関係, 表を出力する。関係が多くなるほど複雑性が増し、結合やサブクエリが増加して計算が多くなる。そしてデータ量が多くなるほど負荷が増す。そして、結果的にパフォーマンス低下を招くことになる。
RDBのデータモデル問題(構造化データ以外への要求に対応しにくい)
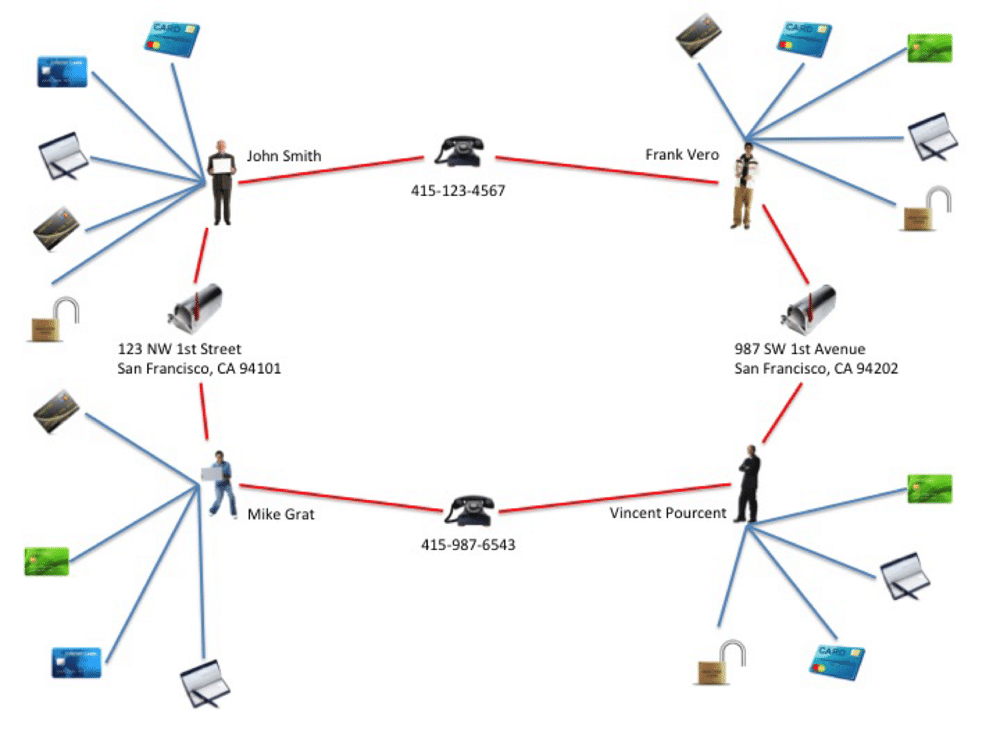 例:保険企業の不正検知のためのグラフデータイメージ
例:保険企業の不正検知のためのグラフデータイメージ

例:グラフデータベースのデータ管理
RDBは構造化, 業務のモデリングを前提としており、関係(一般的にはテーブル, 表)と属性に目的, 指向, 意味をもたせて設計, 構築する。また正規化によってモデリングの精度をあげることで現実世界を効率的に映し出すことを実現する。逆にいうと、一度決まったものを容易に変えることが難しいし、一貫性に欠けるデータを登録することは憚れる。現代においてデータはユーザーやマーケット分析において重要な位置づけであり、そもそもデータを保持していないと話にならない。例えば、定型化されてないログなどである。非構造的なデータの重要性が高まっているなかで、構造化に強みをもつRDBの柔軟性の低さが顕在化しつつある。
加えて、物体間の関係性表現に用いられる(SNSなどに多い)ネットワーク構造のグラフを表現することが得意ではない(できなくはない)。これらは再帰的構造を前提とするため、そもそも再帰的な処理(超意訳するとループ処理)を回避したかったRDBにはマッチしない。一方で現代においてSNSが社会インフラになっているという点でも「関係性」の重要度は高まっているし、関係性は傾向分析を手助け、効果的な施策に落とすことを実現可能にする。(RDBは物体間(ここでは関係, テーブル, 表)の関係性を表すことに長けていたが、物体内に属するオブジェクトそれぞれの関係性を管理することには長けてないっていう整理でいいのかな...)
グラフとは 頂点と頂点間をつなぐ線によって、物事を抽象的に捉えたもの. 交通網, 分子構造, 依存関係, Social Network( https://www.hongo.wide.ad.jp/~jo2lxq/dm/lecture/06.pdf )
NoSQLとは?RDBに取って代わるものなのか?
そもそもNoSQLの定義は明確に存在しない。「RDBとは異なるアーキテクチャやデータモデルに基づくデータベース」くらいの認識でOK。
NoSQLは「Not Only SQL」を意味し、上述したSQL不足点を補う位置づけで捉えるのがよい。くれぐれも「NO!! SQL!!」でSQL, RDBの存在を否定するのではない、ということ。 ( https://ja.wikipedia.org/wiki/NoSQL )
NoSQLの特徴と種類 ( https://ja.wikipedia.org/wiki/NoSQL )
特徴
関係モデルではないデータストアの特徴として、固定されたスキーマに縛られないこと、関係モデルの結合操作を利用しないこと(場合によっては単にそのような機能が欠落しているだけ)、水平スケーラビリティが確保しやすい事が多いこと、トランザクション処理を利用できないものが多いことなどが挙げられる。
実例
検索のための文書のインデキシング、トラフィックの高いウェブサイトのサーバ、ストリーミングデータの配布などがあり、Diggのgreen badge、Facebookのインボックスの検索、eBayのシステム全体など
種類, 分類
・キー・バリュー型 (Key Value Store) - キーに対してバリュー(値)という単純な構造。Basho Riak, Redisなど。大半はバリューとして単純なバイナリデータ (BLOB) のみが格納できるが、Redisのようにリスト、マップ、ソート済みセットといったリッチなデータ構造をサポートするものもある。またバリューに加えて、タグやメタデータと呼ばれる追加情報が格納できるものも多い。日本発のものには okuyama, Hibari などがある。
・ソート済みカラム指向 - 行キーに対してカラム(名前と値の組み合わせ)の集合を持つ。行ごとに好きな名前のカラムを好きな数だけ格納できる。カラムはカラム名によってソートされるため、例えばカラム名に時刻を使うことで1行の中に時系列のデータを格納することができる。Apache Cassandra, Apache HBaseなど。
・ドキュメント指向(Document-oriented、Document store) - XMLやJSONといった、 スキーマレスでデータ構造が柔軟なもの。MongoDB、Apache CouchDB、Amazon DynamoDBなど。XMLデータベースなどのシステムでは、XQueryを利用できるものもある。
・グラフ指向
NoSQLによるパフォーマンス問題の解決
NoSQLは、以下のアプローチでスケールアウトを可能にしてパフォーマンス問題を解消。特にKVS(Key-Value Store)が代表的である。
「厳密なトランザクション制御によるデータ整合性」と「SQLで実現していた高度なデータ操作」というRDBが持つ利点をある程度諦める代わりにパフォーマンスを追求するというトレードオフ(交換条件)を許容するアプローチ...KVSは...「キー」とそれによって一意に決まる「値」という、非常にシンプルな構造しか持たず、それゆえ一意キーによる高速な検索性能を実現
....
単純化したデータ構造を、さらにオンメモリ化するなど、パフォーマンスを向上させるオプション...NoSQLの製品の多くは、複数のデータベースのインスタンスでクラスタを構成し、スケールアウトを可能にすることでパフォーマンス向上 ( https://eh-career.com/engineerhub/entry/2017/11/22/110000 )
NoSQLによる非構造データモデルの解決
非構造化データの扱いに対する解決策として登場したNoSQLの一つが、ドキュメント指向型DBと呼ばれるタイプです。JSONやXMLのような自由度の高いドキュメントを、RDBのテーブルに変換することなくネイティブに扱う機能( https://eh-career.com/engineerhub/entry/2017/11/22/110000 )
参考
https://qiita.com/1amageek/items/3dbbc3112493a73880d0
https://www.agtech.co.jp/blog/2020/11/first_actian_zen_nosql_or_rdb/?gclid=EAIaIQobChMI4Yjel5DQ7gIVopvCCh3Cww7eEAAYASAAEgKHq_D_BwE#way2
この記事が気に入ったらサポートをしてみませんか?