
自律型マインクラフター (Minecraft played by AI)

こんにちはこんばんは、teftef です。今回は AI がマインクラフト (Minecraft) をプレイするということに関してです。OpenAI が開発した Video PreTraining (VPT) 、強化学習を使用した MINEDOJO、GPT-4 を使用した Voyager という最新手法などを3つの異なるアプローチを紹介していきます。
私もまだ初学者であり、説明が間違っていたり勘違いがある可能性が 0 ではないということをご了承ください。ぜひコメントなどをいただけたら幸いです。また、この記事を作成するにあたり、GPT-4 による校正、修正が含まれています。
論文
今回参考にさせていただいた論文はこちら
Minecraft

マインクラフト (Minecraft)は 2009 年にスウェーデンの Mojang という会社が公開したサンドボックス型のビデオゲームであり、プレイヤーは自由に世界を探索し、ブロックを配置または破壊して建物、アートワーク、その他の構造物を作り出すことができます。ブロックやアイテムはさまざまな素材でできており、それぞれが特定のツールを必要としたり、特定の性質を持ったりします。また、プレイヤーは生存モードで食物を獲得し、モンスターと戦い、体力を管理する必要があり理サバイバル要素も含んだゲームとなっています。
オープンワールドサンドボックスゲーム
マインクラフト (Minecraft) は上記でも紹介したようにサンドボックスゲームであり、将棋や囲碁のように決まったルールがなく、ワールドもシードによってランダムに生成されます。またプレイヤーはただモンスターを倒すだけではなく、構造物を作成したり、様々なタスクがあります。そのためまず 『AI に何を学習させるのか』を考える必要があります。これから紹介する論文は、いかにして自律的なエージェントを作成できるかということに目標とします。
ここから 3本のそれぞれ異なった手法を使ってマインクラフト (Minecraft) をプレイするAI の話をします。
それでは行きます。
VPT
VPT は Video PreTraining であり、人間の Minecraft プレイの大規模なラベルなしビデオデータセットに対して、操作(入力など)をラベルとして学習します。これによって学習されたモデルをタスクに応じてファインチューニングすることでタスクを実行することができます。(基本的にファインチューニングしないと本来の性能を発揮できません)

Inverse Dynamics Model(IDM)
まず web から少量のラベル付き動画データ(100時間程度)を入手して、動画をからどのような操作をしているのかを学習します。これを Inverse Dynamics Model(IDM)と呼びます。
アノテーションと学習
続いて , 70000時間の 動画を取得します。この動画を Inverse Dynamics Model(IDM)によってアノテーション (ラベル付け) します。これによって作成されたモデルを「VPT Base Model」とします。
ファインチューン
まず、新しく作成されたワールドで、 Minecraft をプレイしてもらい、家を作ってもらいます。この時のプレイ動画を使って「VPT Base Model」をファインチューンします。
結果

このようにファインチューンすると精度が向上していることがわかります。
また、このファインチューンを用いた手法は強化学習より優れた結果を出しました。
MINEDOJO
MineDOJO は NVIDIAによって製作されたMinecraft をプレイする AI です。

まず Minecraft のようなオープンエンド(目標が制限されず、途中修正可能であるという意味) の環境で活動する自立型のエージェント (AI) を作成するためには3つの条件が必要です。
それは
世界の無限性 : エージェント (AI) が活動する環境は、多様な種類の目標を追求でき。これらの目標は制限されるべきではない。
大規模データセット : このようなオープンエンドな環境での学習を促進するためには、大規模な事前知識のデータベースが必要である。
柔軟性と拡張性 : エージェント (AI) はオープンエンドな環境であらゆるタスクを追求できる柔軟性と、大規模な知識ソースを実用する形に変換できるスケーラビリティを備えている必要がある
ということです。
世界の無限性
そこで、このような条件を実現するために、まず エージェントに様々なタスクを与えました。具体的には 1,581のプログラムタスク (Programmatic tasks) と 216 のクリエイティブタスク (Creative tasks) という 2 つのタスクを与えます。
プログラムタスク (Programmatic tasks) はシミュレータの実際の状態に基づいて自動的に評価できるプログラム的なタスクであり、例えば『金のピッケルを作成する』、『豚をネザーに連れていく』のようなものです。
クリエイティブタスク (Creative tasks) は成功するという目標が一つに定まらず『ゾンビが中にいるホラーハウスを作成』、『豚に乗ってレースをする』のようなものです。
これらのタスクを OpenAI が開発する GPT-3 に入力することで このタスクを実現するための手順を返してくれます。
Here are some example creative tasks in Minecraft: {a few examples}.
Let’s brainstorm more detailed while reasonable creative tasks in Minecraft.
大規模データセット

エージェントを学習させる際のデータセットとして、Minecraft をプレイしている膨大な量のデモンストレーションデータが必要になります。そこで NVIDIA はウエブスクレイピングを用いて、我々は33年分のYouTubeビデオ(75 万本)、6000以上のウィキページ、660万のRedditのコメントを収集しました。もちろんこれらのデータセットにはノイズになってしまうものもあり、機械的にそのようなものを省きました。(詳しくは省略)
柔軟性と拡張性
これらのデータセットを使用して、マルチタスク強化学習を行うことでエージェントを学習させます。強化学習は簡単に言うと報酬系であり、目標に近づくと報酬を与え、遠のくと逆に報酬を引きます。総報酬を最大化するように、エージェントは新しい行動(探索)を試み、既知の最善の行動(利用)を使用するバランスを見つける必要があります。しかし Minecraft のようなオープンエンドなゲームでは報酬を定義することは困難であり、実現不可能です。そのため、YouTubeの動画とそのトランスクリプト (字幕) から、言語条件付きの報酬関数を学習することにしました。
MINECLIP
そこで、動画と自然言語による説明の相関 (関連性) を学習する Vision-Language モデル (Video-Language モデルと言ってもいい) であるMINECLIPを作成します。MINECLIP は 16 フレームの切り抜きと自然言語を同じ Embedding 空間に埋め込むことで、両者の相関 (関連性)を求めることができこれを強化学習の報酬として渡すことができます。エージェントは自然言語で与えられたタスクとそれに対して、エージェントが動作したときのビデオクリップの相関を計算します。その評価結果が報酬となり、エージェントはその報酬を基に次の行動を選択します。このプロセスが繰り返されることで、エージェントは自然言語の説明に従った行動を学習します。

この MINECLIP のText エンコーダー Φ_G は CLIPの Text エンコーダーを流用しています。また Video エンコーダー Φ_V は16 フレームに切り分けそれぞれを Image エンコーダー Φ_I よって特徴量に変換されます。これを Φ_a を通じてビデオ埋め込みに集約します。今回はこれをベースとし、少しばかりの改良を加えています。Φ_a の後に residual CLIP Adapter レイヤーを2層追加し、Φ_I と Φ_G の最後の二つのレイヤーをファインチューニングします。
結果

これは与えられた 12 のタスクに対する成功率の表です。学習された MINECLIP を使用し、zero-shot のタスクを行います。このように MINEDOJO は6つのタスクでパフォーマンス上昇を観測しました。しかしパフォーマンスが下がってしまったタスクもあります。これはこれは、task transfers が起こってしまっていると考えられます。例えば、エージェントが「木を切る」タスクを学習した後、それが「木を植える」タスクのパフォーマンスを低下させる場合、これはネガティブな task transfers となってしまいます。反対に、それが「家を建てる」タスクのパフォーマンスを向上させる場合、一般的には望ましい現象なので、ポジティブな task transfers となっります。より良いマルチタスク学習のアルゴリズムの探索が必要そうです。
MINEDOJO 特有の動き
最後に定性評価を見てみます。こちらに乗っているデモの動画を例にします。
ネザーポータルを立てる動画を見てみます。エージェントは建築が終ると、そのネザーゲートから少し離れて、ゲート全体を見せるようなしぐさを行います。またピラミッドの動画では、ピラミッドに入るとその構造を説明しているかのように全体を見まわします。
これはおそらく学習に使用した動画が YouTube の動画が原因であると考えられます。 Youtuber は建築した建物を視聴者に向けて公開するときに少し離れて全体像を見せたりしますし、ピラミッドなどの構造物は中身の状態や様子などを視聴者に見せるような動きをします。テスト結果にこのような動きが含まれるのは Youtube の動画を学習データに使用した結果なのだと考えられます。
Voyager
Voyager (ボイジャー) は 3023 年 5 月 25 日に出た GPT-4 を使用した MineCraft エージェントの論文です。

オープンエンドな世界で継続的に探索し、計画を立て、新しい行動をするというのはとても難しいタスクであり、今まで書いてきたようなのように強化学習(RL)や模倣学習を用いた手法があります。しかし、これらは体系的な探索、解釈性、汎化には困難が伴います。
そこで LLM をベースにしてエージェントの行動を決定するというアプローチをとります。この論文では、Minecraftにおいて、人間の介入なしに探索を推進し、様々なスキルを習得し、継続的に新しい発見をする、初のLLMを搭載した体現型生涯学習エージェントを作成、評価します。
構成
このエージェントは主に 3 つの要素から構成されており、全ての要素には GPT-4 による結果が用いられます。
自動カリキュラム (Automatic Curriculum)
スキルライブラリ (Skill Library)
反復型プロンプト機構 (Iterative Prompting Mechanism)
以下ではコードが出てきますが、これは手はすべて GPT-4 に入力する Prompt になっています。
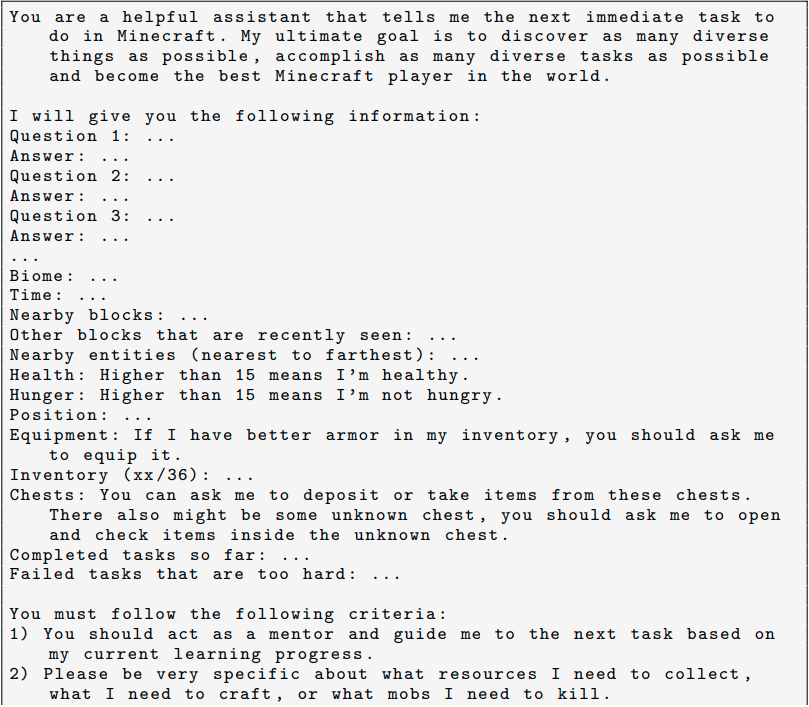
目標を提案する自動カリキュラム(Automatic Curriculum)
オープンエンドな環境において、複雑さのレベルが異なる様々な目標に遭遇します。そこで、以下のようなPrompt を用いて、目標を設定していきます。
・多様な行動を促し、制約を課す指令。
このような文章を Prompt の先頭に置きます。
“My ultimate goal is to discover as many diverse things as possible ...
The next task should not be too hard since I may not have the necessary resources or have learned enough skills to complete it yet.”;
…
次のタスクは、まだ必要なリソースがなかったり、
十分なスキルを習得していない可能性があるので、
あまり難しいものであってはならない”
・エージェントの現在の状態
現在の状態(インベントリ、装備、近くのブロックやエンティティ、バイオーム、時間、健康バーと空腹バー、位置など)を記します。
・フィードバック
過去に完了したタスクと失敗したタスク、エージェントの現在の探索の進捗と能力の最新情報を反映します。
・その他
エージェントの現在の状態や探索の進捗に基づいて自問自答したり、GPT-4 に追加のコンテキストを提供するために、wikiの知識を使って質問に自答します。
You are a helpful assistant that answer my question about Minecraft .
I will give you the following information : Question : ...
You will answer the question based on the context ( only if available and helpful ) and your own knowledge of Minecraft .
1) Start your answer with " Answer : ".
2) Answer " Answer : Unknown " if you don ’ t know the answer .
以上を Prompt にすると以下のようになります

スキルライブラリ (Skill Library)
自動カリキュラムによって提案されたタスクは複雑なものでありるため、好き得るライブラリによる進捗管理が必要となります。各スキルは、自動カリキュラムによって提案された特定のタスクを完了するための実行可能なコードとして表現されます。
・コード生成のガイドライン
最初にガイドラインを入力します。
“Your function will be reused for building more complex functions. Therefore, you should make it generic and reusable.”
・関連スキル
・前回生成したコード、環境からのフィードバックやエラー
これらに基づいてGPT-4は自己改善することができます
・エージェントの現在の状態
(在庫、装備、近くのブロックやエンティティ、バイオーム、時間、健康と空腹のバー、位置など)
スキルライブラリの push と pop

下 : pop
これらによって作成された Prompt を用いて反復プロンプト機構(後述)に通すことによってに、プログラムを繰り返し改良し、新しいスキルとしてスキルライブラリに組み込み、その記述の埋め込みによりインデックスを作成します。
また、スキルの検索には、自分で作成したタスクプランと環境からのフィードバックを埋め込んでスキルライブラリに問い合わせます。
(要するにデータベースみたいなものです )
反復プロンプト機構 (Iterative Prompting Mechanism)
3種類のフィードバックを通じて、自己改善を促すような機構(メカニズム)を導入します。

・環境フィードバック(図の左)
プログラム実行の中間経過を示すフィードバックです。例えば、「鉄のインゴットがあと7個必要なので、鉄の胸当てを作ることができません: 7 more iron ingots "と表示され、鉄製チェストプレートの製作に失敗した原因が示されます。
・実行エラー(図の右)
実行エラーです。バグ修正に使われます。
・タスクの成功チェックを行う自己検証

タスクの成功、失敗かを判定します。 Prompt を入力し、それを GPT-4 が判定します。タスクが失敗した場合は、タスクを完了させる方法を提案することで、評価を行います。
全体
以上の 3 つの機構を用いて全体のプログラムは以下のように構築されます。

まず、自動カリキュラム (Automatic Curriculum) を用いて生成されたタスクを反復型プロンプト機構 (Iterative Prompting Mechanism) に入力し、スキルライブラリ (Skill Library) と照らし合わせてコードを実行し(ここでGPT-4はコードインタープリタとして機能し、生成されたプログラムを解釈し、それに基づいて行動します。)Minecraft を操作します。その結果として、フィードバックとエラーは、次のコード洗練のラウンドのためのGPT-4のプロンプトに組み込まれます。
この反復型プロンプト機構 (Iterative Prompting Mechanism)による反復プロセスは、自己検証がタスクの完了を確認するまで続けられます。タスクが完了した時点で、この新しいスキルをスキルライブラリ (Skill Library) に追加し、自動カリキュラム (Automatic Curriculum) に新しい目標を求めます。
また、ロバスト性を追求するために (デッドロックを解消するために) エージェントが4ラウンドのコード生成後に行き詰まった場合、別のタスクをカリキュラムに問い合わせます。
結果
従来手法として、AutoGPT、ReActとReflexionというエージェント訓練手法と比べています。また、ablation としてスキルライブラリ (Skill Library) を使わない時とも比較します。

探索性能の結果はこのように大きな向上を見せました。160回のプロンプト反復で従来手法の 3.3 倍の 63 個の新規アイテムを発見しました。また唯一 Voyager のみが 「木→石→鉄→ダイヤモンド」 ツールの作製に成功しています。
これは、エージェントの進歩を促進するために適切な複雑さの課題を一貫して提示する自動カリキュラムの有効性を示しています。

VOYAGERは、ベースラインと比較して2.3倍長い距離を移動し、様々な地形を横断することができます

また、zero-shot (未知の)のタスクに対しても遂行することができています。数字はそのタスクにたどり着いた際の繰り返した回数で、小さいほど効率的であると言えます。
結論・考察
Video PreTraining (VPT) 、 MINEDOJO、Voyager と3つの手法を見てきましたが、どれも異なる手法を用いて マインクラフト (Minecraft) をプレイすることを目標にしています。
しかし、Video PreTraining (VPT)は zero-shot タスクは得意ではなくファインチューンを必要とします。 MINEDOJO は Youtube のだ動画を学習させたモデルであり、精度は上がりましたがやはり Youtube 特有の動きをします。
対して Voyager は完全に GPT-4 という LLM を使用して高性能なマインクラフトエージェントを作成することに成功しています。
ここからわかるのは、 LLM は他のどの手法も抑えて性能がよく、さらに Prompt エンジニアリングを行い、Promot の受け渡しのアーキテクチャの工夫だけで達成しています。
これまでも自然言語モデルを用いた論文をいくつか解説しました。直近の GPT-4 のプラグイン機能 web ブラウジング機能を使用してみた結果として、果たして自然言語モデルがこのまま進化するとすべてのもの (検索や仕事)が GPT-4 に置き換わってしまうのも時間の問題ではないかと思えてしまいます。その時にどのように立ち回り、AI とどのように関係を気づいていくかを改めて考えてみることも重要かもしれません。
参考文献
最後に
最後まで読んでいただきありがとうございました。今回はマインクラフトを AI がプレイするという関連で3 本の論文をまとめてみました。
最後に少し宣伝です。主のteftefが運営を行っているdiscordサーバーを載せます。このサーバーではMidjourneyやStble Diffusionのプロンプトを共有したり、研究したりしています。ぜひ参加して、お絵描きAIを探ってみてはいかがでしょう。(8700字、teftef)
↓↓もしよろしければこの記事と開発の支援お願いいたします!
この記事が参加している募集
この記事が気に入ったらサポートをしてみませんか?