
脳波 (EEG) から画像を生成する話

こんにちはこんばんは、teftef です。しばらく大学が忙しくて,記事を休止していました。少し前に fMRI を用いて画像を生成する記事について書きました。今回は fMRI の代わりに EEG を入力として画像を生成する DreamDiffusion についてです。
私もまだ初学者であり、説明が間違っていたり勘違いがある可能性が 0 ではないということをご了承ください。ぜひコメントなどをいただけたら幸いです。また、この記事を作成するにあたり、GPT-4 による校正、修正が含まれています。
論文
脳波を測定すること
人間の脳を解析することで人間の行動や睡眠の脳の動きや特性を知ることができ、脳科学や BMI 宿の発展に大きな貢献となる。しかし私たちは頭蓋骨を切って脳を見ることはできません (倫理的に)。そのため fMRI や EEG といった非侵襲的 (人体を傷つけることがない) な手法を用いて脳波や血流を観測して、それを分析することで、脳の動きや特性を解析しています。
今回は被験者が画像を見てるときに観測された脳波や血流の変化から被験者が見ている画像を再構成できるのではないかという試みから、「脳波から画像を生成すること」について書いていきます。これによって自閉症や失語症患者とのコミュニケーションなどに役立つことが期待されます。
動機や導入についてはこちらの記事でも詳しく書いているので、 前回の fMRI to Image についてはぜひこちらから。
fMRI
脳の活動を観察する方法に fMRI (磁気共鳴画像法)というものがあります。脳が活動すると、特定の部分への血流が増加し、酸素の消費が増えるます。 fMRI は脳の血流量と酸素レベルの変化を検出し、活性化している脳の領域をマッピングすることで、脳のどの部分が何に使用されているかを可視化する技術です。脳のどの部分が特定の課題を実行しているか(例えば、画像を認識する、言葉を理解する、計算する等)を調べるために広く用いられています。fMRI は高い空間分解能を持ち(空間を測るのが得意)、それによって脳の立体的な構造のどの部分が活性化しているのかを正確に把握できます。
fMRI の短所
fMRI はこのような装置を使って脳の酸素量をスキャンします。被験者はその中に横たわる必要があり、大きな動きが制約されます。またこの機械は強力な磁場を発生させるため、金属製の物体(例えば、ペースメーカーや一部の歯科用インプラント)を体内に持つ人は使用できません。ターミネーターのワンシーンでも見たように金属が吸い寄せられてしまします。また fMRI は血流の変化を測定しており、血流の変化には数秒かかるため、時間分解能が低くなります。

EEG
EEG は脳の表面に配置された電極を通じて、脳の電気活動を直接記録します。脳は電気的なシステムであり、私たちの思考(意識的または無意識的なもの)は、電流を介して互いに信号を送る神経細胞のネットワークを通じて生成されます。電気信号が多ければ多いほど、神経細胞の通信が増え、それは脳の活動量の増加に対応します。その電流の変化を検出することで脳の活動の変化を調べることができます。
EEGは脳の電気活動をミリ秒単位で測定できるため、高い時間分解能を持ちます。これは、時間的な精度が必要な研究(特定の刺激に対する即時の脳反応を追跡する研究など)にとっては大きな利点となります。
EEG の短所
ただし fMRI とは異なり、EEGは脳の表面からの電気活動のみを捉えるため、特定の脳の深部で何が起こっているか、脳のどこの部分から来た信号なのかを正確に知ることは難しくなっています。
また、EEGは非常にノイズが多く、脳波データは限られており個人差も無視できないということが問題となっています。
fMRIの代わりに EEG を使う理由
EEGは下のような装置を用いて脳波を測定します。 fMRI と異なり、装置が小さく、特殊な技術を持たなくても使用することができます。また、これを装着している間でも行動が大きく制限されることがなく、ある程度自由に動くことができます。何より市販で脳波を測定する装置が発売されており、入手しやすいことも理由の一つです。

研究の目的と課題
今回は EEG から画像を生成することを目的とします。
これを行うために以下の課題を解決します。
EEG は非常にノイズが多く、脳波データは限られており個人差も無視できないという問題からロバストな (頑健な) 表現を得ること。
EEG信号には独自の特性があり、その特徴空間は text や画像の空間とは大きく異なる。限られた、ノイズの多い脳波と画像のペアを用いて、脳波、テキスト、画像の空間をどのように対応付けるのか
ネットワークアーキテクチャ

このような大きく分けて 3 つの構成から成るフローとなっています。
ロバストな表現を作る。
Stable Diffusion のファインチューニング。事前に学習された Stable Diffusion をEEG を 条件付けとしてファインチューニングする。
CLIP を用いた空間の対応付け。CLIPエンコーダを用いたEEG、Text、画像の空間を対応付ける。
1.ロバストな表現を作る

まずはノイズのある EEG からロバストな EEG を再構成することで、EEGエンコーダの事前学習を行います。EEGデータは二次元であり、縦軸は頭皮に配置されたチャンネル表し、横軸は時間を表しています。EEGの時間分解能は非常に高く、ミリ秒単位の脳活動の急激な変化を捉えることができます。そのため、かすかな脳波の変化を測定することができ、それは逆にノイズが混じりやすくなることになります。
EEG の再構成
そこで、測定されたノイズが混じった EEG (図の一番上)から意味のある情報を抽出するために エンコーダーとデコーダーから成るオートエンコーダー(Masked AutoEncoder (MAE)) を通すことで再構成を行います。ERTT みたいだよね。
まず EEG は時間と脳波の強さから決まっているため、時間領域でトークンに分割し、トークンの一定割合をランダムにマスクします (図の真ん中) 。要するに脳波をとぎれとぎれにする感じです。これを 1次元の畳み込みから成るエンコーダーおよびデコーダーから成る MAE を通じて、周囲のトークンからの文脈的な手がかりに基づいて、欠落した部分を予測するように学習させます。

これによって学習された MAE のエンコーダーは様々な人やさまざまな脳活動にわたるEEGデータに対して、"意味のある" 埋め込みを得ることができます。
2 . Stable Diffusion のファインチューニング

先ほど学習した MAE エンコーダーを通して EEG の埋め込みを抽出します。これを用いて Stable Diffusion の Unet の Cross-Attention に入力(?)します。これによって EEG の埋め込みを条件付けに Stable Diffusion のモデルを学習することができます。学習時にはText Encoder および VAE は Freez させて Unet のみを学習させます。
3 . CLIP を用いた空間の対応付け

EEG信号には独自の特性があり、EEG の埋め込みはテキストや画像の埋め込みとは異なる特性を持ちます。そのため、EEG と画像のペアデータを使ってStabel Diffusion をend-to-end でファインチューニングしてもEEGの特徴をPretrained のSDの既存のテキスト埋め込みと正確に対応付けすることができません。SD は Text と画像がうまく対応されているモデルであり、そこに EEG と 画像が対応付けされたデータセットを用いてファインチューニングしても EEG と Text の対応付けは、うまく対応付けされているとは限りません。
CLIP空間の知識を使う
そのため、CLIP の知識を用いて画像の埋め込みと EEG の埋め込みを近づけさせます。CLIP Image Encoder を用いて画像から 特徴量(青)を抽出します。続いて1 番目の手順で学習させた MAE のエンコーダーから EEG の 埋め込み(黄)を抽出します。この2 つの Cos 類似度を小さくすることで、擬似的に Text , EEG, 画像 の埋め込みを近づけることができます。これによって、最適化された EEG の埋め込みはSDに適しており、その結果、生成される画像の品質が向上します。この CLIP は SD のファインチューニングをする際は Freez されます。

実験
データセット
今回学習に使用する EEG 画像は 400 人以上の被験者から約 12 万件を収集しています。これらのデータには、物を見る、運動イメージ、ビデオを見るなどのタスクを含む、多種多様なEEGデータが含まれています。その画像には
動物(犬、猫、象など)、乗り物(旅客機、バイク、自動車など)、日常的な物体(コンピュータ、椅子、マグカップなど)など、さまざまな物体の画像が含まれています。
Stable Diffusion モデル
ファインチューンに用いるモデルが Stable Diffusio 1.5 となっています。
結果


一番左の画像が被験者が見た画像 (真値) です。それに対して EEG を取り、それを元に画像を生成します。右の 3 つの画像が出力画像です。モデルが脳波データから高品質の画像を生成し、これらの画像が真値と正確に一致していることが観察できました。
従来手法との比較(定性評価)

GAN を用いた Brain to Image (上) と今回の手法 (下) を比較しました。
その結果 Diffusion Model を用いた今回の手法では画像が大きく崩れていないことがわかります。
定量評価
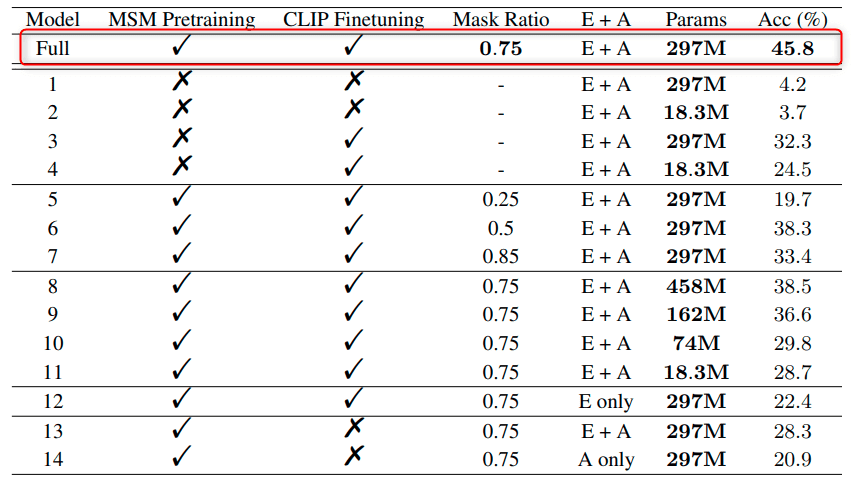
このように提案手法のモデルが最も良い精度を出しています。その分パラメーターは多いです。
参考文献
https://www.medic.mie-u.ac.jp/meduc/text/physiol2003-7.pdf
最後に
最後まで読んでいただきありがとうございました。今回は fMRI から画像を生成する手法の代わりとして EEG から画像を生成する手法を紹介しました。このように脳波から画像を生成する分野は翻訳に近いなと感じています。ぶっちゃけいってしまうと、2つのモダリティの対応付け (音声-画像、fMRI-画像、Text-画像 など何でもいい) があれば生成することは容易であると思います。今後もこのような研究が出てくると思いますが、個人的には、例えば脳波のとある特徴が画像の何に対応するのかなど、 Diffusion Model と脳波の対応付けの考察 (fMRI の記事で書きました) の方が面白いと思いました。
宣伝
最後に少し宣伝です。主のteftefが運営を行っているdiscordサーバーを載せます。このサーバーではMidjourneyやStble Diffusionのプロンプトを共有したり、研究したりしています。ぜひ参加して、お絵描きAIを探ってみてはいかがでしょう。(4700 字,teftef)
↓↓もしよろしければこの記事と開発の支援お願いいたします!
※注意 : 支援してくださる方へ
※注意 : ここから先は何も内容がありません。しかし、この記事をお読みいただき、良かったと感じていただけたのであれば、この記事と開発の支援お願いいたします!
ここから先は
¥ 500
この記事が参加している募集
この記事が気に入ったらチップで応援してみませんか?