
【あらゆる執筆に】冗長な表現に気付いて、推敲の質を上げよう!

【はじめに】こんなこといいな。あったらいいな。
以前、小説の書き方を記事として公開しました。
その際にテキスト校正ツールをいくつか紹介しましたが、それらを利用する際に欲しいと思っていた機能がありました。
「似たような単語が頻出した時に、ここが冗長だよーって教えてくれるツールはないのかなぁ⋯⋯」
そんなことをぼんやり考えていたのですが、LLM(大規模言語モデル)の基礎を勉強中にふと思いついたアルゴリズムがありました。
「そうか。無いなら自分で作ってしまえばいいんだ」
そんなこんなで開発したツールは本記事では「冗長表現可視化ツール」と呼ぶことにします。
事項からはGoogle Colaboratoryでの実装方法を紹介します。
Google Colaboratoryについて
今回使用するGoogle Colaboratoryについて、Bard(Google社製の生成AI)に説明してもらいました。以下、Bardでのサービス要約です。
Google Colaboratory(Colab)は、Google が提供する無料の Jupyter Notebook 環境です。Jupyter Notebook は、コード、テキスト、画像、表などを組み合わせたインタラクティブなドキュメントを作成できるツールです。Colab は、Web ブラウザ上で利用できるクラウドベースの Jupyter Notebook 環境であり、Python などのプログラミング言語や機械学習のライブラリを簡単に利用することができます。
Colab の主な特徴は以下のとおりです。
* クラウドベースなので、インストールや設定が不要ですぐに利用開始できます。
* 無料で利用できます。
* Python や TensorFlow などの機械学習ライブラリがプリインストールされています。
* 複数ユーザーで共有して共同作業することができます。
Colab は、機械学習の学習や開発に最適なツールです。また、Python やデータサイエンスなどのプログラミングを学習する際にも便利です。
## Colab の使い方
Colab の使い方は、以下のとおりです。
1. Google アカウントでログインします。
2. Colaboratory を開く: https://colab.research.google.com/をクリックします。
3. 新しいノートブックを作成します。
4. コードやテキストを入力して、実行します。
## Colab の活用例
Colab は、以下の用途に活用できます。
* 機械学習の学習や開発
* Python やデータサイエンスのプログラミングの学習
* データ分析や可視化
* ウェブアプリケーションの開発
Colab は、幅広い用途に活用できる便利なツールです。ぜひ、試してみてください。
ということで、今回の記事では機械学習をさせるわけではありませんが、その基礎を支える技術である形態素解析を用いてツールを実装していきます。Colabでの実行方法は基本セルの左側にある実行ボタンを押していくだけですが、使用方法で分からないことがあれば操作説明のページ等を参照してください。
冗長表現可視化ツールの内容
本記事の最後にまとめてコードを引っ越す手法を紹介しますが、ここでは「冗長表現可視化ツール」のコードの紹介と、それぞれ何をしているのかを説明します。
まずは使用するライブラリをインストールします。
# 日本語形態素解析用ライブラリのインストール
!pip install fugashi
!pip install unidic-lite
!pip install japanize-matplotlib fugashiは日本語形態素解析ライブラリで、unidec-liteは解析に用いる辞書になります。
japanize-matplotlibは後々出てくるデータの可視化をする際、matplotlib(グラフや図表を描画するためのライブラリ)で日本語を使えるようにするために必要です。
続いて形態素解析が正しくできるかチェックします。
fugashiの分かち書き機能を使って文章を名詞や連体詞、助詞等で分割します。
# 形態素解析器の動作確認
from fugashi import Tagger
tagger = Tagger('-Owakati')
text = "この文章を形態素分析した結果を表示します。"
tagger.parse(text)
for word in tagger(text):
print(word, word.pos, word.feature, sep='\t')次の結果が返ってくるはずです。
この 連体詞,*,*,* UnidicFeatures26(pos1='連体詞', pos2='*', pos3='*', pos4='*', cType='*', cForm='*', lForm='コノ', lemma='此の', orth='この', pron='コノ', orthBase='この', pronBase='コノ', goshu='和', iType='*', iForm='*', fType='*', fForm='*', kana='コノ', kanaBase='コノ', form='コノ', formBase='コノ', iConType='*', fConType='*', aType='0', aConType='*', aModeType='*')
文章 名詞,普通名詞,一般,* UnidicFeatures26(pos1='名詞', pos2='普通名詞', pos3='一般', pos4='*', cType='*', cForm='*', lForm='ブンショウ', lemma='文章', orth='文章', pron='ブンショー', orthBase='文章', pronBase='ブンショー', goshu='漢', iType='*', iForm='*', fType='*', fForm='*', kana='ブンショウ', kanaBase='ブンショウ', form='ブンショウ', formBase='ブンショウ', iConType='*', fConType='*', aType='1', aConType='C1', aModeType='*')
〜中略〜
。 補助記号,句点,*,* UnidicFeatures26(pos1='補助記号', pos2='句点', pos3='*', pos4='*', cType='*', cForm='*', lForm='', lemma='。', orth='。', pron='', orthBase='。', pronBase='', goshu='記号', iType='*', iForm='*', fType='*', fForm='*', kana='', kanaBase='', form='', formBase='', iConType='*', fConType='*', aType='*', aConType='*', aModeType='*') 分割された後の言葉と対応する品詞、その他featureに格納されている情報を出力しています。
「文章」に対してword.feature.kanaを出力すると「ブンショウ」という読み仮名が返ってきます。このあたりの使い道を考えるのも面白いかも知れませんね。
次に形跡する文章をtextという変数に格納します。
# 解析したい文章を入力
text = '''
これはテストの文章です。そんな文章なのでわざと強調表示したい文章を検知できるようにしました。
この結果としては文章と強調表示がハイライトされるはずです。
ある程度離れていたら検出しないので、例えばこの「結果」というキーワードはハイライトされません。
'''次に除外するキーワードを指定します。
# 除外したいワードを入力
exc_words = '''
そう
ない
こと
'''上記に指定したキーワードは後述する品詞による選別後も残ってしまうキーワードです。通常の文章で頻出する可能性の高いキーワードですので、除外ワードに指定しておきます。
また結果に応じて追加する必要もありますので留意してください。
例えば「沙希」という人物名は「沙」「希」に分割されてしまい、頻出するワードとして検出されてしまいます。
人物名が頻出するのは冗長ではないケースが多いので、この場合は「沙」「希」を登録しておく必要があります。
※ユーザー辞書で人物名として扱う手法もありますが、恐らくこちらの方が楽に調整できるので本記事では紹介しません。
それでは入力した文章に対して解析を行なっていきます。
# fugashiのインポートとトリガー設定
from fugashi import Tagger
tagger = Tagger('-Owakati')
# pandasのデータフレーム作成
import pandas as pd
df = pd.DataFrame(columns=["row", "word", "pos", "distance"]) # ワードと品詞と距離を格納するデータフレームを作る
word_dict = {} # ワードとレコードのインデックスを記録する辞書(既出ワード格納辞書)を作る
row_no = 0 # 処理した行数を格納する
diff = 5 # 距離の閾値を設定する
# 除外するキーワードをexc_wordsからリストに格納
exc_list =[]
for line in exc_words.split("\n"):
exc_list.append(line)
# 除外対象でないことを判定する関数
def not_excluded_words(word):
for w in exc_list:
# 引き渡されたwordがexc_wordに含まれているかどうかを判定する
if word == w:
return False # 含まれている場合はFalseを返す
return True # ループが終わっても含まれていない場合はTrueを返す
''' 形態素解析、選別結果をデータフレームに格納 '''
# 一行をfugashiで形態素解析して、最後のEOSを除いて、単語ずつ処理する
for line in text.split("\n"):
for word in tagger(line): # 単語オブジェクトのリストを取得する
word, pos = word.surface, word.feature.pos1 # 解析後のワードと属性を取得
# 品詞による抽出ワードを決める
if pos in ["名詞", "形容詞", "副詞"]:
# 除外対象ではないことを確認
if not_excluded_words(word):
# ワードが既出ワード格納辞書にあれば、直前のレコードのdistanceを0にする条件を追加する
if word in word_dict:
record_index = word_dict[word] # 辞書からレコードのインデックスを取得する
distance = df.index[-1] - record_index # 現在のレコードのインデックスと前回のレコードのインデックスの差を距離とする
if distance <= diff: # 距離が閾値以下ならば、distanceを0に更新する
df.loc[record_index, "distance"] = 0
else:
distance = -1 # ワードが辞書になければ、距離は-1とする
# データフレームにワードと品詞と距離を追加する
df = pd.concat([df, pd.DataFrame({"row": row_no, "word": word, "pos": pos, "distance": distance}, index=[0])], ignore_index=True)
# ワードとレコードのインデックスを辞書に記録する
word_dict[word] = df.index[-1] # 最新のレコードのインデックスを取得して辞書に上書きする
row_no += 1
# データフレームに格納されたデータを表示
df.head(10)次の結果が返ってくるはずです。
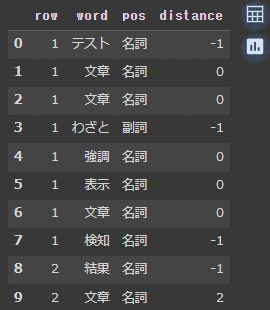
このコードで抽出した名詞、形容詞、副詞をデータフレーム(pandasライブラリで使用できる表)に格納し、表示したものがが上図になります。
この処理と同時に既出ワード辞書にワードとインデックスを格納していき、同じキーワードが再出現した時に現在のインデックスと前回のインデックスの差分を取り、これをキーワード間の距離(distance)としています。
この距離が閾値以下の前回の距離を「0」に置き換えているのは、後述するハイライト表示で使う為です。
今回閾値diffは5としていますが、適宜自分好みに調整してください。
続いて与えられた文章で冗長と思われる表現があればハイライトするコードです。
最初にハイライト表示の背景色、文字色を指定するためのエスケープシーケンス辞書を作っています。
# エスケープシーケンスの辞書を作る
color_dic = {'red_bg':'\033[41m', 'white_text':'\033[37m', 'reset_bg':'\033[49m', 'reset_text':'\033[0m'}
# ハイライトしたいキーワードのリストを作る
keywords = df[(df['distance'] >= 0) & (df['distance'] <= diff)]['word'].unique().tolist()
# ハイライトした順にキーワードを格納するリストを作る
highlighted_words = []
# 元の文章の各行に対して処理する
row_no = 0
for line in text.split("\n"):
# ハイライトしたいキーワードがあれば、エスケープシーケンスで囲む
for keyword in keywords:
# distanceが0~diffになっている行のみ対象とする条件を追加する
if keyword in line and row_no in df[(df['word'] == keyword) & (df['distance'] >= 0) & (df['distance'] <= diff)]['row'].unique():
line = line.replace(keyword, color_dic['red_bg'] + color_dic['white_text'] + keyword + color_dic['reset_bg'] + color_dic['reset_text'])
# ハイライトしたキーワードをリストに追加する
highlighted_words.append(keyword)
# print文で出力する
print(f"{row_no:06d}:{line}")
row_no += 1
# ハイライトしたキーワードのリストを集合に変換して重複を除去する
highlighted_words = list(set(highlighted_words))
# print文上でリンクを貼る為のモジュールを読み込み
from rich.console import Console
import urllib.parse
# 使用する変数を初期化
console = Console()
keyword_link = ""
print("** 検出した重複距離の近いキーワードリスト **")
for query in highlighted_words:
# ハイライト表示したキーワードに対してGoogleで同義語検索するURLを発行する
encoded_query = urllib.parse.quote(query + " 同義語")
url = "https://www.google.com/search?q=" + encoded_query
keyword_link = keyword_link + f"[link={url}]{query}[/link] "
# ハイライトしたキーワードのリストをリンク付きで表示する
console.print(keyword_link)
print("※リンクをクリックすると同義語検索結果画面を開きます。")今回の文章の場合、次のような結果が返ってきます。

距離の近いキーワードは言い換えた方が冗長にならないので、Googleで同義語を検索するリンクも作って表示しています。
最後に頻出ワードをTOP10で表示します。
import japanize_matplotlib
import matplotlib.pyplot as plt
# wordの出現回数をカウントする
word_count = df['word'].value_counts()
# 出現回数を降順にソートする
top10 = word_count.head(10)
top10 = top10.sort_values(ascending=False)
# 円グラフを描く
plt.pie(top10, labels=top10.index + ' (' + top10.astype(str) + ')', autopct='%1.1f%%', startangle=90, counterclock=False)
plt.title('頻出ワード(TOP10)')
plt.show()今回の文章の場合、下図が出力されるはずです。

これで頻出しているキーワードが可視化できました。
自分のColab環境にノートブックをコピーする
このノートブックはGit hub上で公開しています。
https://github.com/falls247/Colab/blob/main/keyword_duplication_check.ipynb
このURLの「https://github.com/」の部分を「http://colab.research.google.com/github」に置き換えてアクセスすることで自分のColab環境で開くことができます。そのまま自分のアカウントで開きたい場合は下記のアドレスからアクセスしてください。
http://colab.research.google.com/github/falls247/Colab/blob/main/keyword_duplication_check.ipynb
今回のコードはGPUの性能に依存しないので、GPU無しの環境でも快適に動くはずです。
いかがだったでしょうか? これでえっちな話を書いている時にペ◯◯とか◯棒を使いまくってしまった時に気付くことができますね。
今回は冗長な表現になっているかも知れない部分を検出するのみですが、他の校正ツールと合わせて使うと更に執筆が捗ると思います。
それでは、良い執筆ライフを!
この記事が気に入ったらサポートをしてみませんか?