
議事録アナロジー4

何かしらを千葉県議会議員の選挙に間に合わせたかったので、今回もすこし急ぎ目です。 前回までで、四街道市の議事録で基本原理は確認したので次は千葉県議会の議事録をより大量につかって、もう一回実施してみたいとおもいます。
議事録の収集(クロール)
ググれば簡単に千葉県議会の議事録は見つかります。
上記議事録データサイトは、結構頑張っていていつの議会とか、注目のキーワードとかで関連する議員の発言を全体から検索したり、一つづつ確認したりできます。ただ議事録にたどりつくまで複数回クリックしないといけなく、URLも以下のようにidの羅列なので複数の議事録をDownloadしたい場合は手動では大変です。http://wwwp.pref.chiba.lg.jp/pbgikai/dsweb.exe/documentframe!1!guest06!!3716!1!1!1133,-1,1133!3078!288582!1133,-1,1133!3078!288582!1136,1135,1134!1!1!298368!3!1?Template=DocAllFrame
学習の精度をあげるには大量の議事録があるほどよいので今回はなにかクロール(Download)ツールを使いたいと思います。話はそれますが、クロールとかクローラとかネット用語として何気なくつかっていました。ネットの海をクロールで泳ぎ切るみたいな感じで大変そうだなと思ってました。あらためて辞書をcrawlでひくとはうとかノロノロ進むという意味なんですね。日本人はクロールと聞くとなんか早そう!(背泳ぎとか平泳ぎより)というイメージですがもとの意味はノロノロなんですね。
さて、そのクロールツールとして何が良いかを調べてみると wget という昔からあるツールが今回の目的とあっているようです。今までもサーバー構築時に、インターネットに接続できたか確認するときに以下のような基本的な使い方はしていました。
wget http://hoge.comそこにちょっとオプションをつけるだけでトップからリンクされている内容を階層的に取得してくれるしかもDOS攻撃と思われないよう適度にRequest間隔をあけるという優しさ成分も指定できます。今回は以下のような指定をしました。
wget
-m \
--wait=5 \
--tries=7 \
--waitretry=14 \
--regex-type posix \
--reject-regex '.*gif$|.*css$|.*Template=DocPrintWindow.*' \
http://wwwp.pref.chiba.lg.jp/pbgikai/html/mokuji/h30_02t.mok.html上から順に説明すると ミラーリング(階層的にどこまでも行く)、一回の要求に5秒まって、拒否られたら7回までリトライ(1-14秒間隔開けてね),posix正規表現でgif, cssとかPrint表示用の不要なファイルはDLしないことにして最後の行のURLから階層的にDLを始めなさいという意味になります。
待つこと19時間
祝日だったので外に遊びにいくまえにコマンド開始して、帰ってきてみたらまだ終わっていない。。 5秒まつのは優しすぎたかもしれません。結局2018年にあった4会の議事録をDL完了するのにそれぞれ14-19時間かかりました(並列ですすめたので結局19時間です)。
以下のように取得したものはhtmlであったり、textファイルであったり同じ議事録を色々なフォーマットでDLされているようです。
<div id="textcol"><pre><A name="LinkNo1"></A> 平成30年9月招集 千葉県定例県議会会議録(第7号)<br><br>平成30年9月28日(金曜日)<br> ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━<br> 議 事 日 程<br>議事日程(第7号)<br> 平成30年9月28日(金曜日)午前10時開議<br>日程第1 議案第1号ないし議案第22号、報告第1号ないし報告第3号及び決算認定に対する質<br> 疑並びに一般質問<br>日程第2 発議案第1号<br>日程第3 休会の件<br> ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━<br> 午前10時0分開議<br>◯議長(吉本 充君) これより本日の会議を開きます。<br> ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━<br><br>
<A name="LinkNo2"></A> 質疑並びに一般質問<br>◯議長(吉本 充君) 日程第1、議案第1号ないし第22号、報告第1号ないし第3号及び決算認定についてを一括議題とし、これより質疑並びに一般質問を行います。<br> 順次発言を許します。通告順により臼井正一君。<br> (臼井正一君登壇、拍手)<br><br>
2018.09.28 : 平成30年9月定例会(第7日目) 本文
平成30年9月招集 千葉県定例県議会会議録(第7号)
平成30年9月28日(金曜日)議事日程(第7号) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
議 事 日 程
議事日程(第7号)
平成30年9月28日(金曜日)午前10時開議
日程第1 議案第1号ないし議案第22号、報告第1号ないし報告第3号及び決算認定に対する質
疑並びに一般質問
日程第2 発議案第1号
日程第3 休会の件
ファイルをサイズと名前でフィルターする
word embedding用途にはとりあえずtextを対象にしたいと思います。DLしたファイル総数は2018年9月の議事録だけで1万以上あるのでそのなかから使えるTextファイルを絞り込む必要があります。textファイルかどうかを判断するためにいくつかファイルを実際にあけてみるとURLに特徴的な文字列がはいっていました。以下のようなコードで特定のディレクトリ以下にあるファイルサイズ10KB以上、特定のファイル名のものだけを抜き出して、単語に分割します。
def size_text_filter(path):
files = []
for pathname, dirnames, filenames in os.walk(path):
for filename in filenames:
# フィルタ処理
joinpath = os.path.join(pathname, filename)
size = os.stat(joinpath).st_size # in bytes
if ((1024*10 < size) and (0 <= filename.find('DocumentType=text' ))):
file = filewakati(joinpath,out,'shift_jis')
files.append(file)
return filesそして出来上がったファイルリストから単語リストを作ります。
def make_text(files):
data = []
for file in files:
f = open(file,encoding='utf-8')
words = f.read().split()
f.close()
max_sentence_length = 1000
subcount = (int)(len(words)/max_sentence_length)
for si in range(subcount) :
subset = words[si*max_sentence_length:(si+1)*max_sentence_length]
data.append( subset )
return dataあとは前回と同じことを回していきます。ただし前回まではサンプルで手動でDLしてきたので19万3千単語数が対象でしたが、今回は機械的にDLしたので対象が1034万7千単語です。計算終わるでしょうか、、、
議事録の単語の前後関係からそれぞれの特徴量をtrainingさせるところをNotePCで30epochしかけてみましたが、、1日遊んで帰ってきてもまだ10epochいっていない、、 これは待てない。。 最近はCloudに自分の必要な機械学習ライブラリとcuda等のdriverがセットアップ済みのGPUPCが時間貸しで安く使えます。(競売タイプで1時間100円くらいから使えます)早速mxnetインストール済みのものにgluon-nlpを追加でいれてあとはほぼそのままjupyter-notebookとデータをuploadして動かします。 3時間位で30epoch実施できました。
結果確認
get_k_closest_tokensEmb(voc, net, 10,"課題")
get_k_closest_tokensEmb(voc, net, 10,"環境")
get_k_closest_tokensEmb(voc, net, 10,"教育")
get_k_closest_tokensEmb(voc, net, 10,"ゴミ")
==>
closest tokens to "課題": 喫緊, 抱える, 解決, 山積, 現状, さまざま, 克服, 切り札, 抱え, 認識
[[0.5849266]]
closest tokens to "環境": 住環境, 生活, 生き物, 石渡, 温, 負荷, におい, 里美, 敏彦, アセスメント
[[0.5605044]]
closest tokens to "教育": 道徳, 教, 教師, 学校, 教科書, いのち, スクールソーシャルワーカースーパーバイザー, 教材, 教科, 教職員
[[0.63158363]]
closest tokens to "ゴミ": 副読本, ぽつりぽつり, 座り, かなっ, 喫食, 興味深かっ, 投げ捨てる, 鑑賞, 弁当, 読み取れ
[[0.64824504]]この辺はいいですね。千葉の課題が浮き彫りになってます
get_k_closest_tokensEmb(voc, net, 10,"IoT")
get_k_closest_tokensEmb(voc, net, 10,"農業")
get_k_closest_tokensEmb(voc, net, 10,"工業")
get_k_closest_tokensEmb(voc, net, 10,"森田")
==>
closest tokens to "IoT": AI, ポリテクセンター, モノ, ウド, 知能, 勝ち進ん, I, 切り札, Society, 思春
[[0.51021266]]
closest tokens to "農業": コンサルティング, 生産, 405, 働き手, 営, 農家, フレッシュミズ・アンシャンテ, フォークリフト, 畑作, あけぼの
[[0.43386555]]
closest tokens to "工業": 団地, 柴田, 利雄, 光信, 剣持, 上高野, 工業団地, 八千代工業, 夜景, 椎
[[0.5919762]]
closest tokens to "森田": 健作, 知事, 楽屋裏, いん, 森岳, おはよう, マスク, バラエティー, 俳優, ごときまあ妥当なんですが、、
get_top_k_by_analogy(voc,net,10,"人","嘘","議会")
get_top_k_by_analogy(voc,net,10,"人","嘘","知事")
get_top_k_by_analogy(voc,net,10,"人","お金","千葉")
==>
closest tokens to "嘘"-人+議会: 精選, セクシュアルハラスメント, 出退勤, 公正, 時刻, 取りまとめ, 部会, 不偏不党, ハラスメント
[0.49832934]
closest tokens to "嘘"-人+知事: 森田, 精選, セクシュアルハラスメント, カウンセリング, 健作, 傾注, 応接, カウンセラー, 求め
[0.44950074]
closest tokens to "お金"-人+千葉: 千葉, 堂本, つぎ込み, 出し合っ, 取り決め, 要は, 渡っ, 注ぐ, 諮っ
[0.5309635]このアナロジー"嘘"-"人"+"議会"で議会にとっての嘘とはをだしてみるのはやっぱり、、ちょっと無理を感じてきました。(面白いだけでそこからなにか言えるものがない)
get_k_closest_tokensEmb(voc, net, 10,"臼井正一")
get_k_closest_tokensEmb(voc, net, 10,"天野行雄")
==>
closest tokens to "臼井正一": 臼井, 敬二, 三十五, 西田, 佐野, 今井, 中台, 信田, 光保, 彰
[[0.8697448]]
closest tokens to "天野行雄": 天野, 良治, 横堀, 稲毛, 喜一郎, 藤井, 弘之, 竹内, 張り切っ, 宏子無作為に見つかった議員さんの名前をいれるとでてくるのは自民とか民主とか同じ会派のひとたちの名前。意見の傾向から特徴をみているのか、単純に近くに名前が記載されることが多いから表示されているのか判断つきません。 可能性は感じる結果ですが、これだけでは選挙のときに参考になる情報とは言えない感じです。
もともと抽出したかったものと、衝撃の多数決結果
議事録などのデータから抽出したかったのは、その議員が投票したらどんなことに賛成して、どんなことに反対するのかその議員の特性です。
とりあえず議案ごとの多数決の結果は別途まとまっているので視点を変えるためにそちらを参考にみてみます。例えば以下は平成最後の議会の議案の賛否一覧です。
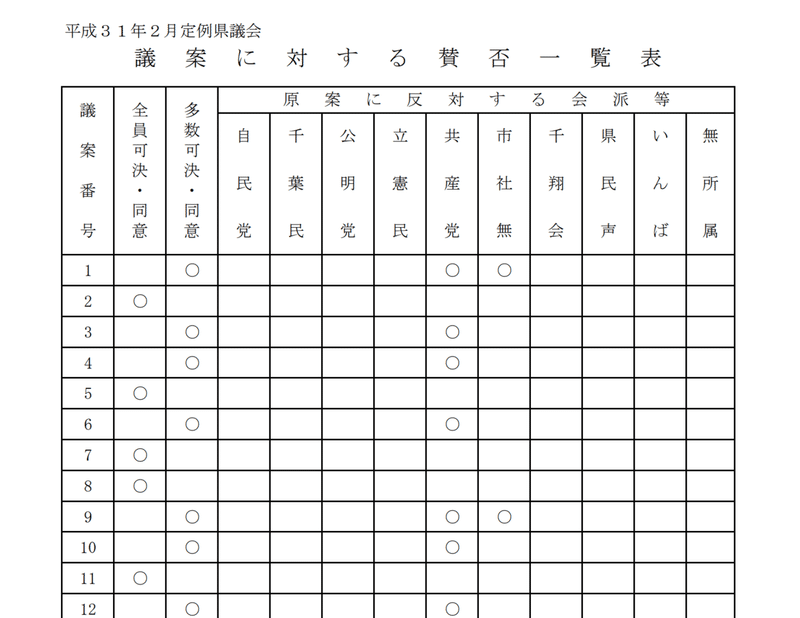
これをみて、びっくりしたのはかなりの数が全員可決が多い。反対しているものは全100議案中 半分くらい共産党、1割位が市民ネット、社民の会が反対しているだけで他の会派は全員、全部に賛成です。賛成の人が圧倒的に多いのがいいのか、悪いのかはべつにしてこの結果をいくら集めても差分が見えないので、選挙のときの参考にはならないことが分かりました。
議員さんごとに発言内容をサマライズ
選挙の参考にするためには議員さんごとの実際の活動がうがびあがらせたいので、議会の議事録から議員さんごとにどのような質問、コメントをはつげんしているのかを要約することを当面の目標として再設定したいとおもいます。選挙まであと4日ですが、がんばってみます。
この記事が気に入ったらサポートをしてみませんか?