
臨床予測モデル検証の要点

2024年1月にBMJのResearch Methods & Reportingで予測モデルの評価と外的検証に関するreviewが3本出たので、復習も兼ねて自分なりに整理しました。本記事ではpart 1のみ扱っています。
この論文に書いてある通りに行うべき・論ずるべきか?と言われると思うところはあるのですが、予測モデルの研究を行った経験のある人や、抄読会などで何度か予測モデルの研究を扱った人は必読の内容だと思います(特にpart1)。これらの事を知った上で、どうするか考えるのと、知らずに自分の知識ベースで行うのとでは結構な隔たりがあるでしょう。ただ、Part 3は外的検証研究におけるサンプルサイズ計算に特化した内容で人を選ぶので、必要になったら読めば良いと思います。
元論文はオープンなので英語が問題なく読める方や、細部が気になる方はぜひ自分でも読んでいただけたらと思います(本記事は一言一句丁寧に訳しているわけではないです)。僕の本を読んでおくと理解が深まります(多分)。
尚、本記事は自分なりの解釈・意見であり、論文のクリエイティブ・コモンズライセンスCC BY 4.0(適切な引用で翻案可)に準拠しています。
Collins GS, Dhiman P, Ma J, Schlussel MM, Archer L, Van Calster B, Harrell FE Jr, Martin GP, Moons KGM, van Smeden M, Sperrin M, Bullock GS, Riley RD. Evaluation of clinical prediction models (part 1): from development to external validation. BMJ. 2024 Jan 8;384:e074819. doi: 10.1136/bmj-2023-074819. PMID: 38191193; PMCID: PMC10772854.
ちなみにこの論文はGary Collins (TRIPOD statements書いた人), Frank Harrellに加えて若手の予測モデル研究者(Maarten Smedenなど)が多く共著者に含まれています。
一番の御大であるSteyerberg先生は本論文のrapid responseに寄稿されています。COVID-19パンデミックで質の低いモデルが量産されてしまったと。また、質の高い予測モデルの開発と検証には、生物統計学と疫学に関する知識と訓練が必要である、指摘されていますがその通りだと思います。この辺が機械学習専門の人がいきなりモデルを作っても上手くいかない理由の一つかなと。
1. 臨床予測モデルの評価がなぜ大事か?
そもそも臨床予測モデルとは、複数の予測因子(例えば、年齢、家族歴、症状)に基づいて、患者アウトカム(のリスク)を推定するためのものです。血圧など連続的なアウトカム値を推定するモデルもありますが、本論文では一般的な生存/死亡などの二値アウトカムを用いたリスク推定に焦点を当てています。
2023年までに世の中には、慢性閉塞性肺疾患の診断には400を超えるモデルが、心血管疾患予測には300を超えるモデルが、そしてcovid-19には600を超える予後モデルがあるとのこと。Covidは乱立していたので相当多いだろうと思ってはいましたが、まさかこんなに多いとは。そりゃ使われませんよね。有名な下記論文のとおりです。
1-1. Summary Points
臨床予測モデルは、モデルがターゲットとなる対象集団を代表するデータセットで評価すべき。
開発用データセットでは優れているように見えたモデルも、別のデータセットで評価すると、(仮に同じ母集団からのデータであっても)性能が低くなることがほとんど。
モデルを開発する時点でデータを分割(split)することは、信頼性の低いモデルにつながるため避けるべき。
利用可能なすべてのデータを活用する努力をすべき(内的検証におけるresamplingや、内的-外的交差検証など)
本論文では、モデルを開発する段階なら、とにかくnを集めること、そしていかなる形でも(時間・空間的分割含めて)分割せずに全部のデータを用いろ、というのが基本的なスタンスです。
1-2. なぜ予測モデルは使われないのか?
世の中のほとんどの予測モデルが用いられていません。その理由として、
研究デザインと解析に関する問題(サンプルサイズが小さい、overfittingなど)
評価報告が不十分(予測モデル研究を十分に評価することが難しい)
臨床的意思決定への明確なリンクがない
Part 1.では「モデルの予測性能を公正かつ有意義に評価すること」に主眼が置かれています。モデルが正しく評価されていないと、次の段階の評価(e.g., 介入や費用対効果研究)が可能かどうか、あるいはモデルの更新(e.g., 再較正)が必要かどうかの判断ができなくなるわけですね。最悪の場合、モデルが有害になる可能性さえあります。
個人的には研究者側のdisseminationの努力も足りていないと思っています。
大抵の人が論文を出しておしまいになるので(自省)。
1-3. なぜ予測モデルの検証が必要なのか?
まず、すごく納得したのが、実は臨床予測モデルにおける検証(バリデーション, validation)という単語は定義が曖昧で、一貫性がないということ。
確かにバリデーションと言っていても色々なニュアンスがあり、とりあえずバリデーションと書いておけば、臨床で使える!とすら思われがち。時には意図的に誤って用いられているようにも思います。ひどい場合には、外的検証じゃないのに「external validationしました!」と書いてある研究もあります。また、ほとんどの外的検証の研究において、データセットが小さいため、性能評価が不安定な事が指摘されています(中々刺さる)。
ちなみに(外的)検証を行った際には識別能(AUROCなどで示されるdiscrimination)もですが、特に較正能(calibration)の低下が著しいことが多いです。
一方で、一口に予測性能が不十分か?と言ってもそこは結構難しいところ。例えば、「性能不足だ!」と言うにはモデルの較正がどの程度ズレているのか判断する必要があるのですが、その判断はあくまで主観的です。
要は、バリデーションと銘打った研究が実施されたからと言って、
そのモデルが「(正しく)バリデーションされた」・「有効である」とは限らない
実際、異なるセッティングでは、性能にばらつきがあることは予想されますし、モデルが常に有効であることが証明されることはありません(また、そうであることを期待してはいけない)。これはPart 2の結論にもあります。
1-4. 内的検証(internal validation):モデル開発時の評価
モデル開発に使用したのと同じデータ(またはデータ源)を評価に使用する場合、そのプロセスは内的検証(internal validation)と呼ばれます。例えば、予測モデルの報告ガイドラインであるTRIPODでは、「モデルの種類、モデルの構築手順(予測因子の選択を含む)、内的検証の方法を明記する」と書かれています。TRIPODは一度は目を通しましょう。日本語版もあります。
内的検証でよく用いられるのは下記二つ。
・Data splitting (e.g., 7:3などにランダム分割して、7割で開発、3割で検証)
・Resampling(k-fold cross validationやbootstrapping)
個人的な補足として、拙著にも書きましたが、因果推論の文脈における内的妥当性(internal validity)と外的妥当性(external validity)と同じようなものですが、予測の文脈においては内的検証(internal validation)と外的検証(external validation)と書くことが多い?のでそれに準拠しています。ちなみに"test set"は内的検証・外的検証どちらの意味でも使われるので、検証に使った集団がどんな集団かを考えるのが大事です。
1-5. モデル開発時の内的検証:総論
A. Apparent performance(日本語だと、"見かけの性能"?)
これは、開発に使ったデータセットでそのまま予測モデルを評価することです。開発したデータセットに最もフィットしたものになるので、overfittingしやすく、当然良い性能が出ます(良い方向に結果が出るのでoptimistic/optimismと言います)。ただし、後述するように非常に大きなサンプルサイズではoptimismは無視できるため、実はunbiasedになります。
これは知らない人が多い気がします。実際に論文を書くときに、「開発したデータセットでそのまま評価して報告するとは何事だ!」と、apparent performanceだけ出しても論文としては受理されにくいでしょう。後述する通り、外的検証が行われていることが当たり前だという風潮が一般的だと思います。また、そのような大規模データセットは潜在的にheterogeneousであり、そのようなデータで作成された予測モデルの価値はなんなのか?という疑問もありますが。
B. Internal validation(内的検証)
予測モデルの研究なら、最低限内的検証は行う必要があります。
Split sample(分割法)
一般的には推奨されません。データが減ってoverfittingしやすくなり、かつ評価するデータセットが小さくなるので。一方、データが大きい場合、overfittingのリスクは減少するため、検証データを使ってもあまり意味がないです(apparent performanceおよび下記の1-6を参照)。また、ランダム分割を繰り返す事によって良い結果を出そうとするcherry pickingに繋がります。
k-fold cross validation(k分割法)とBootstrapping(ブートストラップ):具体的な方法は図を見るほうが早いので下記URLどうぞ(no COI)。
モデルを開発するために全てのデータを用いる事ができるのが利点。モデルが対象とする母集団において、unbiased or least unbiased な推定値が得られます。ただし、欠測データの存在&予測モデルがrestricted cubic splineなどの非線形項を含む場合は、一筋縄ではいかないことに注意が必要です。
C. Internal-external cross validation(内的-外的交差検証)
データセットが複数あるいは複数施設がある場合、k-fold cross validationと同様に、ある施設を除いた残りの施設でモデルを作成し、最初に除いた施設で検証する方法です。この方法では施設間におけるモデル性能の異質性や、モデルの性能がどの施設で・あるいはどんな理由で悪いのかを探索する事ができます。近年はビッグデータが増えたのでこの方法がますます重要になりそうですね。高田先生らの書かれた下記論文にも詳しく書いてあります。
Bigdataが当たり前になってきた現在、これが主流になっていくのかなと思います。最近BMJから出た下記論文もdevelopment & internal-external validationを行なっていました。個人的にはこの論文のmethodsは非常にクリアに書かれていて流石だなと思います(共著者がPart 1の筆頭著者)。
D. External validation(外的検証)
外的検証の重要性は昨今強調されているので多くの方がご存知かと思います。モデル開発に使用したデータとは異なる新しいサンプルのデータで、モデルの性能を推定することですが、実はここもいくつか焦点があります。
・再現性の評価:モデル開発に使用した母集団と同様のデータで行う
・Transportabilityの評価:異なる母集団やセッティングのデータで行う
・Generalizabilityの評価:同じ母集団における別集団やセッティングで行う
個人的には、transportabilityや再現性の話を論文上でしてもあまり理解(重要視)してもらえないことの方が多く、異なるセッティングで検証したかどうかのgeneralizabilityの評価が特に重視されているように思います。Generalizabilityやtransportabilityの話は下記どうぞ。
面白かったのが『モデル開発段階での外的検証は効率的なデータ利用とは言えないため、編集者や査読者の(知識不足が故の)要求に応えるためだけに実施されるべきではない』とのこと。さらに、外的検証は対象集団を代表する新しいデータを用いて、その後の研究でモデルの性能を評価するために用いるべきであり、便宜的に入手可能な既存のデータを用いても、モデル性能に関する情報は限定的で誤解を招くとまで書かれています。
昨今は内的検証と外的検証両方を行うのが一般的に思いますが、そこの線引きがちょっと分かりにくいですよね。実は外的検証なんていうものは存在しないという意見もあります。
多分筆者らは、モデル開発の時点では、本来の意味での外的検証を行う必要はないと言っているのでしょう。これは後述する、「外的検証が行われていないと認めない雑誌がある(そして、それは愚かだと筆者らは考えてる)」という問題とのバランスになりそうです。
また、外的検証の研究は、意図的に異なる設定(成人用に開発したモデルが小児でも使えるかどうか)や、予測因子やアウトカムの定義・時間軸が異なる場合もあります(例えば、1年後のアウトカムを予測するモデルが、2年後のアウトカムで評価される) 。
このような検証自体は良いのですが、ある既存のモデルが十分に外的検証されていないセッティングで自分のモデルと比較する研究が時々あるなとは思っています(transportabilityが検討されていない)。
例えば、小児を対象として自分が開発したモデルがあるとします。このモデルと、成人で開発された既存のモデルXとを比較する場合、この既存のモデルXは小児でも検証されているべきと思います。検証されていないモデルを自分のセッティングに持ってきて自分のモデルと比べるのはunfairでしょう…
Temporal validation(時間的検証)
例えば2010年から2020年までのデータがあった場合、2010年から2017年までのデータを使ってモデルを開発し、2018年から2020年までのデータを使って検証するような感じです。モデル開発時における時間的検証はほとんど役に立たないので避けるべき。モデルの性能が調査期間中に変化しているかどうか(特に悪化しているかどうか)の評価に有用。理想的には修正までできればというところ。
Geographical or spatial validation(空間的検証)
モデル開発とは異なる地域の集団のデータで評価すること。 モデル開発時において空間的検証が有用であることは稀である。特に、すべてのデータをモデル開発に使用でき、異なる施設におけるモデル性能の不均一性を内的・外的検証アプローチで探索できる場合はなおさら。データが特に大きく、解析に計算負荷がかかる場合は、クラスター(例えば国や施設)を除外することが現実的な妥協案として考えられる。
個人的には無いよりいいだろうと思っていたのと、claimsのような大規模データならこのような分割しないと検証できないと考えていましたが、あまり意味がないと言われると苦しいところです(実際には、後述する通りあまりに大きいデータだとresamplingできないのでsplitせざるを得ないことはあるのですが)。
ここからは各論です。
1-6. モデル開発時の内的検証:Apparent performance
上記の通り、開発したデータでそのまま予測性能を出すと、一般には共変量シフト(共変量の分布が開発時と検証時で異なる)が起きない・overfittingのためにoptimismと呼ばれるモデルの過大評価が発生します。
本論文では外傷にはトランサミン!となった有名なCRASH-2 trialのデータでapparent performanceがどう変化するかを検証しています(n=20207、アウトカムとして28日死亡のnが3089)。
ここで使うモデルは下記
対象:外傷患者(注:本文には急性心筋梗塞と書いてありますが、typoかなと思っています。CRASHの項目で既往歴に心筋梗塞はないので)
サンプルサイズ:200, 300, 400, 500, 1000, 5000, 10000までのサンプルを用意
アウトカム:28日死亡
予測因子:4つの予測因子(年齢、性別、収縮期血圧、GCS[意識レベル])と、10個の無関係なノイズ予測因子の計14個
モデル:ロジスティック回帰
解析:各サンプル数(200, 300, …10000)それぞれで500回モデルを回してc統計量(≒AUROC)を計算する(500回置換ありのresamplingする)。
c統計量とAUROCの話は岡田先生のこのnoteが一番わかりやすいです。
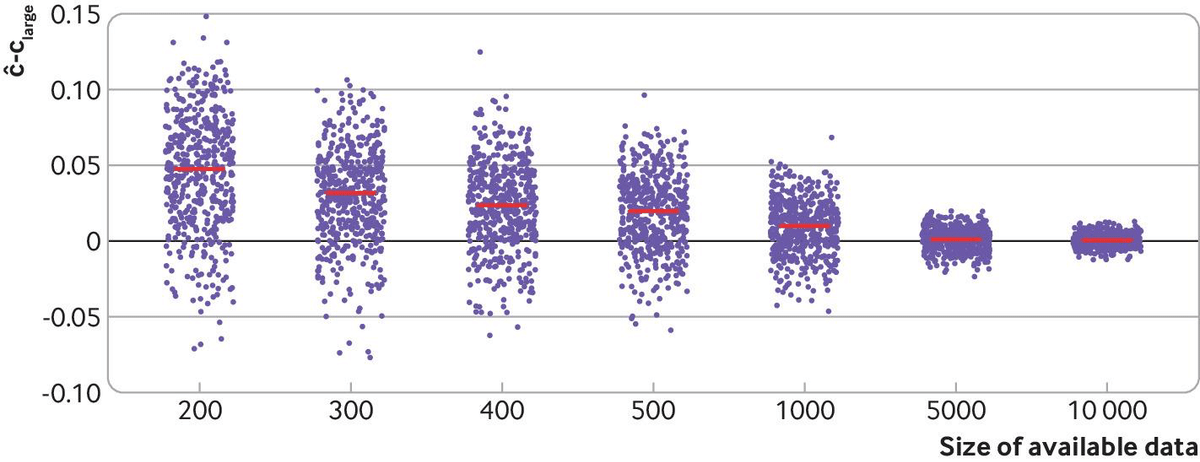
紫のドットは各サンプルサイズでのc統計量(C^)とC_largeの差分、500回の平均値が赤線。Collins GS, et al. Evaluation of clinical prediction models (part 1): from development to external validation. BMJ. 2024 Jan 8;384:e074819.
上記の通り、サンプルサイズが小さい場合、apparent performanceにおける推定値はかなりoptimistic(全体的に図の上の方、すなわち良い方に触れている)で、c統計量は0.7から1.0弱の範囲と大きなばらつきがあります。
このモデル(変数14個のロジスティック回帰)ではApparent performanceで推定値が安定するのは数千〜のサンプルサイズになります。
1-7. モデル開発時の内的検証:Random split
ランダムに分割しているから良いというわけでない、といきなり書かれています。昔の論文で僕は結構やってました(白目)。また、ランダム分割したデータセットをそれぞれ「独立した2つのデータセット」と書くことは誤りであると(元々同じデータなため)。これはその通り。
データを分割する欠点は二つ。
・モデル開発時のデータセットが小さくなり、overfittingの可能性が高まる
・テスト用のデータセットが小さくなり、モデルの性能を正確に評価できない
では具体的にどの程度変化するのか?を同様にCRASH-2 trialのデータと先ほどのモデルを使って示しています。

Splitした場合、サンプル数が少ないと、70%の開発データでのapparent performanceはoverfittingしているためかなりoptimisticです。一方30%しか使っていないデータで検証してもあまりにばらつきが大きく、c統計量が0.5から1.0近くまでを取りうるため何の意味もありません(つまり、意図的に良い結果だけをピックすることもできる)。やめましょう。
サンプルサイズが大きくなるにつれて、開発データセットにおけるapparent performanceとsplit後のテストセット(30%)の性能の差は小さくなります。
したがって、データ分割は不要。
ちなみにこの話は新しいものではなく、20年以上前に方法論の文献で述べられていますが、中々主流になっていないと筆者らが苦言を呈しています。
これは過剰に(external) validationが叫ばれ続けた故の弊害ではないかと思うんですよね。20年前はビッグデータがまだ多くなかったと思いますが、ビッグデータの増えた現在は、逆にsplitしても十分すぎるサンプルサイズがあることもあり、難しいところですね。論文として出すならsplitしてしまう気がします。
また、特殊なケースにおいてはsplitせざるを得ないことはあります。
・複雑なモデル(例えばdeep learner)、全データセットのresampling(例えばbootstrap)が利用できない
・データ共有制限のため、複数のデータを一つにまとめることができない
このような状況では、とにかく大規模な開発データセットとテストデータセットを持つことが強く推奨されています。一方、サンプルサイズが小さい場合の評価は、不安定性のプロットや不確実性の測定するなどの対応があります(下記参照)。
1-8. モデル開発時の内的検証:Resampling approach - bootstrapping and k-fold cross validation
Bootstrappingはsplitとは違って、モデル構築プロセス自体(予測変数の選択や回帰係数の推定など)を評価することで、overfittingによるoptimismを推定します。そして、その推定量を用いることで、よりunbiasedな推定値を出そうという流れです。何言ってるか分からんという人もいると思うので、具体的な方法を示します。
オリジナルの全データを用いて予測モデルを作成し、apparent performanceを求める
置換ありのbootstrapでデータセットを作り、1と同様にして予測モデルを開発する。そしてその性能を、
開発したbootstrap データセットで評価する(apparent performance)
オリジナルの全データで評価する
2-1と2-2の差分がoptimismなので、それを求める
上記2と3を繰り返し(例えば500回)、optmismの平均を求める
1で求めたapparent performanceから4で求めた平均optimismを引いて、最終的な性能として評価する
とりあえずApparent performanceを評価しますが、それだとoptimisticなので、これを補正したいわけです。Bootstrapを用いた仮想のサンプルデータでoptimisticなモデルを作り、そのモデルをそのbootstrapデータとオリジナルデータで評価したら、当然bootstrapデータでの性能が高く評価されます(overfittingしてるので)。その差分(optimism)は当然ばらつくので、500回くらい回した平均のoptimismを算出して、一番最初のモデルからその平均のoptimismを引けばいいよね、という感じ。
上記の2-3のプロセスは、200回程度でも結構正確にoptimismを推定できますが、少なくとも500回は行うことを筆者らは推奨しています。

先ほどの図でもbootstrapの結果が効率的であることを示しています。ただし、非常に大きなデータセットの場合はbootstrapが(コンピューターの性能的に)不可能なことがあります。でもそれくらいデータが大きいならapparentでも十分なことがほとんどです。
もう1つのresampling手法であるk-fold cross validationは、多くの場合ブートストラッピングと同等の性能を発揮します(説明短い)。今はこれが主流じゃないでしょうか。k-fold cross validationはsplit sampleの拡張で、モデル性能の推定におけるバイアスとばらつきを減少させることができます。
個人的にはk-fold cross validationが非常に楽なので、これで良いと思いますが。本文にある通り、bootstrapとの差は気にすることはないです。
1-9. モデル開発時の内的検証: Non-random split(時間的/空間的検証)
時間的検証(temporal validation)と空間的検証(geographical/spatial validation)の話。
時間的検証
時間的検証における一番の問題は、『どの期間をモデルの開発に使用し、どの期間を評価に使用するか』です。モデルの開発に古いデータを使うと、現在の患者特性(予測因子とアウトカム)や現在の医療の質を反映していない可能性があります。逆もまた然りで、新しいデータでモデルを開発すると、古いデータしかないので性能評価が難しくなります。正直、どちらの選択肢も微妙なので(モデル開発の時点では)この方法は推奨されません。例えば、手術手技の発展により、手術成功の患者が増えると、予測される転帰の発生が経時的に減少し、モデルの較正性能に影響を与えます。
したがって、もしこのような変化を考慮するなら、時間的検証よりも較正の変化などを防ぐために、継続的な(モデルの)更新のような方法を考慮すべきとのこと。時間的再較正(temporal recalibration)も選択肢の一つで 、予測変数の効果はデータセット全体で推定されますが、ベースラインリスクは最新の期間で推定されます。
地理的・空間的検証
地理的・空間的検証でも、多くの場合、分割することで得られるものはほとんどありません。むしろ利用可能なすべてのデータを使用してより一般化可能性(汎化性能)を持つモデルを開発する機会を逃していることが多いと(マジすか)。
日本でもよくあるDPCなど、施設が非常に多くresamplingがコンピューターの性能的に難しい場合、一部を分割してもそれほどは不利にならないかもしれません。ただし、分割するなら一回だけにしましょう(先ほど書いたようにcherry pickingするなという話)。
1-10. モデル開発時のInternal-External Cross Validation(内的-外的交差検証)
最近は大規模レジストリやclaims/administrative dataなどのビッグデータが利用可能なので、ついつい上記の時間的あるいは空間的な分割をして一部を開発に、残りを検証に、としたくなりますが、著者らはこれらを勧めていません。これらのようなsplittingが可能なほどのデータセットであれば、コンピューターの性能が許す範囲でresamplingや内的-外的交差検証を行う事を勧めています(特にモデル性能の異質性を見たい場合)。
何をしているかというと、k-fold cross validationと同じで、データセットの分割が各施設(or 国などのクラスター)になるというだけです。下記の図で"cluster"を"施設"に置き換えて貰えば分かりやすいです。施設ABCDとあったら、まずは施設Aを外して施設BCDでモデルを作り、Aの施設で評価します。次に施設Bを外して…と繰り返していきます。
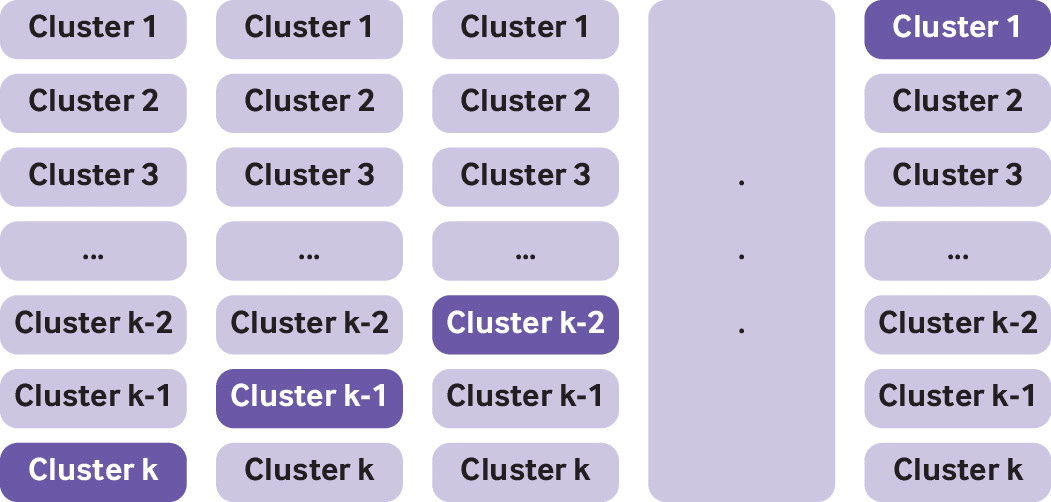
このように検証し、メタ解析の手法を用いることでクラスター間におけるモデル性能の一般化可能性と異質性を評価することができます。最終的には結果をフォレストプロットで提示、(ランダム効果)メタアナリシスを用いて要約推定値を算出します。
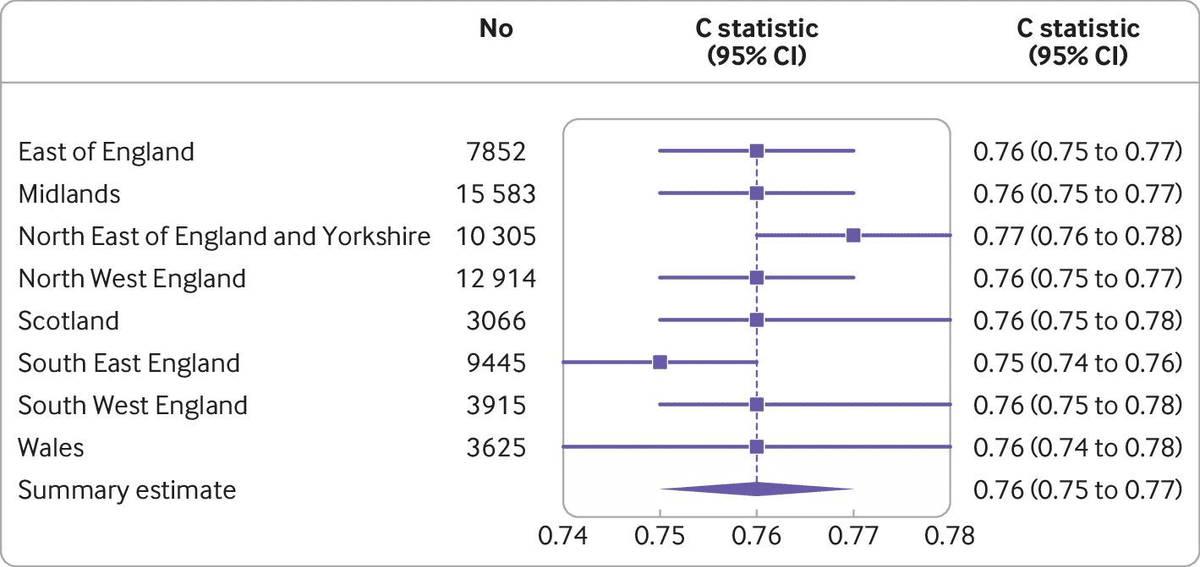
1-11. 外的検証(External validation):新規データを用いた外的評価
外部検証とは、モデル開発に使用されたデータ(および使用されたソース)とは異なる新しいデータセットで、既存のモデルの性能を評価するプロセスです。いくらデータセットが大きくても、分割したりソース源が同じであれば外的検証とは言えないと書かれています。
外的検証の重要な点は、generalizabilityとtransportabilityを示すこと。
例えば、Collins(この論文の著者)とAltmanらは、QRISK2とFramingham risk scoreを独立した外部データセットで検証し、系統的な誤較正・較正不足(miscalibration)、現在の(当時の)治療閾値での正味の利益がないこと(no net benefit)、および異なる治療閾値の必要性を示しています。
さて、一部の学術誌は、外的検証なしでモデル開発研究を公開することを拒否していますが、この立場は時代遅れで誤解を招くものであり、研究者が意味のない、誤解を招く外的検証を行うことを促す可能性があると述べています。
それをまずTRIPODに書くか雑誌のeditorやreviewer達に言って欲しい
確かに無理やり行おうとして、
・とりあえず集めた代表性のないデータ
・小さすぎる検証データ
・外的検証という名目が必要だからと、実は同じデータなのに外的検証と呼んでいるデータ分割などは少し前までよく見られていたと思います(今でも?)。
モデル開発データセットが大きく、ターゲットとなる母集団(結果と予測因子の測定を含む)を代表し、そして内的検証が適切に行われている場合、直ちに外的検証が必要でないことさえあります。
ただ、実際にそのようなデータというのは限られているから外的検証が必要です。例えば下記のような要素が存在するため、内的検証だけでは不十分になります。
・元々のデータが、モデルのターゲットとなる対象集団を反映していない可能性(代表性の欠如)
・測定の変動(測定誤差を含む)や標準化の欠如
・不適切な統計手法
・不十分なサンプルサイズ(単純にnが正義)
・欠損データの処理(重要な予測因子の欠損を含む)
・医療の変化や発展
外的検証が『予測モデルを開発する研究』に含まれていることもありますが(最近はそちらの方が多いのでは…)、筆者らは、開発段階では利用可能なすべてのデータを使用してモデルを構築し、十分な内的検証もしくは内的-外的交差検証を行うことを推奨しています。
外的検証はあくまでも、モデルを開発した研究の『外』で行われるべきであり、各人が用いたい集団を念頭に置いて行う必要があります。つまり、研究者が想定する母集団の数だけ外的検証があるとのこと。当然外的検証研究が多ければ多いほど、そのモデルが未検証の集団でも役に立つ可能性がありますが、保証はされません。
外的検証研究は非常に重要ですが、その研究自体は少ないです。
その理由は想像に難くないのですが、
・特に問題となるのは出版バイアスで、favorableな結果のみが出版されること
・学術誌が外的検証研究をに興味がないこと(おそらく大して引用されないから)
・モデル開発者が外的検証して、仮に性能が悪かった場合、それを報告しないこと
・外部の独立した研究者にとっても、雑誌が取らないならわざわざ研究しない
・外的検証者にモデルの所有権がないので、モチベーションが上がらない
これらを踏まえると、相当な雑誌に掲載されて、かつ正しくvalidationされた研究以外はほとんどがoverestimateされているであろうことは想像に難くないです。このことは機械学習領域で顕著であり、最近のScience誌でも取り上げられていました。
https://www.science.org/doi/10.1126/science.adg8538
ちなみにrapid responseにはbiological variabilityにも注意しろとありましたが、その通りだと思います。つまり採血なんかは結構結果が容易に変わり得るので、そのようなばらつきも考慮すべきと。
1-12. サブグループでの検証: 公平性を評価する
モデル性能の評価は一般的に、データセット全体に対して行われます。例えば検証データセットに当てはめた場合のc統計量やcalibration plotなど。これがなぜかというと、『検証データセットはターゲットとなる母集団の近似的代表(proxy)である』という仮定を置いているからです。
しかし、実際には対象集団によってモデルの性能は異なるはずで、この潜在的な異質性をちゃんと探索して、モデルの一般化可能性を探る努力をしましょうというのが大事な点です。施設間差などはもちろん、特に性別/ジェンダー、人種/民族グループなどの重要なサブグループでの性能評価が求められて(期待されて)います。
特にモデル性能が悪いと考えられるサブグループを報告すべきと書かれています。確かに、あるモデルの性能が良いからと用いていた場合、ある特定のグループにおいてのみ予測性能が低かったら、それは患者さんに害を及ぼす可能性すらあるわけです。
これはおそらく、海外では黒人が医療的な差別を受けやすい、男女で異なる可能性がある、などのpolitical correctnessの視点も含めているのではないかと思います。そういう意味での"fairness"なのかなと。日本と米国ではこの辺の意識の差がかなりあると思います。でもこれはかなり大事な点なので、モデルを作るときには意識したいですね。
人工知能や機械学習への関心と投資の急増もあり臨床に新技術(予測モデルなど)を導入することが期待されていますが、それによって新たな格差を生み出したり、既存の格差を悪化させるべきではありません。したがって、デザインおよびデータ収集、解析、報告、および解釈それぞれにおいて重要なサブグループを考慮することが重要です。
1-13. Part 1の結論
予測モデルの性能を評価することは極めて重要で、検証研究は不可欠です。
モデル開発時点でのデータ分割は避けるべきで、resamplingによる内的検証や、内的-外的交差検証を効果的に活用しながら、利用可能なすべてのデータを活用することを目指しましょう。
そして外的検証研究は、できれば独立した別の研究者により、その後の研究において検討されるべきです。このシリーズの次の論文パート2では、そのような研究の実施方法について説明します。
結局のところ、nが大事という話。疾患やモデルにもよりますが、今後の臨床研究において数百例では正直厳しいでしょう。よほど意味のあるものでなければやめた方がいいと思います。
そして外的検証を行わないことをどこまで雑誌側が許容するのか?多分そんなにすぐには変わらないので、外的検証も含めた論文じゃないと厳しいのではないかなと思います。

https://alu.jp/series/金田一少年の事件簿外伝_犯人たちの事件簿/crop/XQQqf72puqibtpVGCOyO
この記事が気に入ったらサポートをしてみませんか?