
臨床予測モデル検証の要点2:どのように外的検証研究を行うか?

Part 1の概要と解説記事はこちらからどうぞ。
今回はそのPart2に関してまとめました(CC BY 4.0)
Riley RD, Archer L, Snell KIE, Ensor J, Dhiman P, Martin GP, Bonnett LJ, Collins GS. Evaluation of clinical prediction models (part 2): how to undertake an external validation study. BMJ. 2024 Jan 15;384:e074820. doi: 10.1136/bmj-2023-074820. PMID: 38224968; PMCID: PMC10788734.
2. どのように外的検証研究を行うか?
近年では回帰以外にもランダムフォレストやニューラルネットワークなどの機械学習手法を用いたモデル作成が急増していますが、どのようなモデルであっても外的検証研究の役割に変わりはありません。そこでpart 2では、そのような外部検証研究をどのように行うか?に関して、統計的手法と必要な尺度に焦点を当てて概説しています。
2-1. Summary points
外的検証は、開発プロセスのデータセットとは異なるデータセットでの予測性能の評価。
外的検証研究には5つの主要なステップがある:①適切なデータセットの取得、②アウトカムの予測、③予測性能の評価、④臨床的有用性の評価、⑤明瞭な結果報告。
外的検証のデータセットは、モデルが実装される予定の対象集団とセッティングを代表するものであるべき。
最低限、検証データセットには、モデルが適用可能で(予測因子が全部ある)、かつ実際のアウトカムがないといけない(予測値と実測値両方が取得できること)。
モデルの予測性能は、全体的な適合性(overall fit)、較正(calibration)、識別能(discrimination)の観点から、集団全体および主要なサブグループ(eg, 性別や人種)で検討されるべき(part 1の"fairness")。
較正は、予測値の全範囲かつ予測が行われる各関連時間点で、smoothed flexible calibration curveなどを含むcalibration plotで評価されるべき。
予測の目的が意思決定である場合、net benefitやdecision curveなどを用いてその臨床的有用性についても評価されるべき。
よく較正されたモデルが理想的である一方、較正不足(miscalibration)なモデルでも臨床的に有用である可能性がある。
TRIPOD声明をちゃんと読んで従うこと。
ちなみにここでは"External validation is the evaluation of a model’s predictive performance in a different (but relevant) dataset, which was not used in the development process. It does not involve refitting the model to compare how the refitted model equation (or its performance) changes compared to the original model. Rather, it involves applying a model as originally specified and then quantifying the accuracy of the predictions made."と書いてある通り、モデルを新しく当てはめて係数やモデルがどう変化するかを見るのではなく、あくまで開発したモデルをそのまま当てはめた場合にその性能がどうか?を定量的見るものだよ、という意味です。
2-2. Step 1-1. 外的検証のための適切なデータセットの取得
外的検証研究の最初のステップは、適切で高品質なデータセットを取得すること。
外的検証データセットで考慮すべき品質の問題は何か?
当然ながら、理想的には外的検証用の前向き研究を行うことですが、時間とコストがかかります。そこで電子カルテレビューやclaims(DPCやレセプト)などの既存のデータセットを用いることが多いのですが、予測因子が欠けていたり、アウトカムや予測因子の評価が実臨床と異なっている、定義が異なる、イベントの時間が記録されていないなどの問題があります。また、一部のデータセットは患者集団が限定されているため、十分な検証ができません。例えばUK Biobankは40歳から69歳までの個人を対象としているため、それ以外の年齢の人たちにおける検証ができません。
外的検証用のデータセットは目的に沿っているべきで、
モデルが対象とする集団を代表している
患者集団の選択基準と除外基準に従うことができる
「予測時点での」予測因子が入手できる
予測因子とアウトカムの測定方法が確実である
アウトカムが発生する期間がカバーされている
適切なサンプルサイズがあること(part 3)
欠測データがないこと
が理想的なデータセットになります。
既存のデータセットが外的検証研究に使用するのに適しているかを判断するために、予測モデルのリスク・バイアス評価ツール(PROBAST)の「Participant Selection」、「 Predictors」、「Outcome」の領域におけるsignalling questionを用いることを推奨しています。
Domain 1:Participant Selection
予後予測モデル研究にコホートやランダム化試験、診断予測モデル研究には横断研究を使用するなど、適切なデータソースが使用されたか?
参加者の選択・除外基準は適切に行われたか?
Domain 2:Predictors
予測因子は全ての参加者に対して同様の方法で定義され、評価されたか?
予測因子の評価はアウトカムデータの知識なしに行われたか?
予測因子はモデルが使用される予定の時点で利用可能か?
Domain 3:Outcome
アウトカムは適切に決定されたか?
事前に定義された、または標準的なアウトカム定義が使用されたか?
アウトカム定義から予測因子は除外されたか?
アウトカムは全ての参加者に対して同様の方法で定義・決定されたか?
アウトカムの決定は、予測因子の情報の知識なしに行われたか?
予測因子の評価とアウトカムの間の時間間隔は適切か?
個人的にはrisk of biasのこれらの項目はそれなりの経験者じゃないと適切に評価できないのではないかと思っていますが、指標にはなります。
2-3. Step 1-2: 予測モデルの外的検証にはどのような集団とセッティングを用いるべきか?
大事なのは、モデルがターゲットとする集団におけるvalidityです。つまり、外的検証研究は、モデルが用いられる予定の対象集団とセッティングを代表するものでないと意味がありません。外的検証の意義はPart 1の記事の1-11を参照してください。
ほとんどの外的検証研究は、利用可能なデータ(いわゆる既存のデータ)や簡単に収集できるデータ(convenient sample)に基づいているため、特定の対象設定やサブグループでのモデルの性能のみを評価していることになります。つまりデータセットに代表性がないことが問題になります。
ではどうすれば外的検証の対象が明確になるのか?に関してDebrayらが開発データセットと検証データセットの関連性を定量化し、外部検証の焦点が再現性かtransportabilityかを明確にすることを推奨しています。
Part 1でも書きましたが、再現性は、外部検証データセットがモデル開発に使用された集団や設定と類似している場合で、transportabilityは、意図的に異なる母集団や設定での外的検証の場合です。例えば成人向けのモデルを小児で検討してみる、というのはtransporatbilityになるでしょう。
2-4. Step 1-3: どのような情報が外的検証用データセットに含まれているべきか?
最低限、モデルを適用するために必要な予測因子と、実際に観察されたアウトカムの情報が含まれている必要があります(実際に観察されたアウトカムと、予測されたアウトカムを比べる必要があるため)。
イベントまでの時間(time-to-event)アウトカムの場合、任意の打ち切り時間(つまり、フォローアップの終了)とアウトカム発生の時間も記録されている必要があります。
予測因子もアウトカムも信頼性を持って測定されるべきで(reliably measured)、当然ながら、予測因子が手に入るタイミングと予測を行うタイミングの時間関係は重要です。例えば、手術前に手術後28日の死亡率を予測するために使用されるモデルの場合、手術前に利用可能な予測因子を使用し、術中や術後の予測因子は使用してはいけません。
予測因子のタイミングとその取得方法は非常に重要で、これが時系列的におかしい、あるいは信頼性がない場合はそのモデルに大幅な影響を与えます。時々これが記載されていないことがあるので、僕は注意して見ています。
2-5. Step 2:モデルからの予測の作成
このセクションは単にモデルを当てはめて予測しろ、ということが書いてあるだけなので割愛します(図を見て貰えばわかりますが、解説しても仕方ないです)。
そもそもこのプロセスを手動で行うことはなく(行ってはいけない)、RやSAS、Pythonなどの解析ソフトを用いるべきです。近年のブラックボックス型の機械学習に基づく場合は開発者からソフトウェアオブジェクトとして提供してもらうか、特定のシステム・サーバーを介してアクセス可能にしてもらうなどの方法があります。最近ではwebで入力するような形式もありますが、さすがにこれに毎回入力していくのは手間でしょう。
予測を作成したら、下図のように予測値をプロットして評価してみましょう。ここで明らかにおかしな分布をしていたら、それが本当なのかどうかを検討する必要があります。

2-6. Step 3: モデルの予測性能の定量化
Step 3は、全体的な適合性(overall fit)、校正(calibration)、および識別能(discrimination)の観点からモデルの予測性能を定量化することで、https://www.prognosisresearch.com/softwareに本論文で用いたコードやパッケージがまとめられています。
下図はoverall fit, calibration, discriminationが綺麗にまとまっているので、論文を書く際にはこれを参考にすると良いのではないでしょうか。

2-7. Step 3-1: Overall fit
アウトカムが連続変数の場合、R2(モデルによって説明されるアウトカム値の全体的な分散の割合)によって定量化され、1に近い値が好ましいとされます。%で表示されることもあり、説明される変動の割合として示されます。また、予測の平均二乗誤差(mean squared error, MSE)、すなわち「予測値と正解値の差(=誤差)」の二乗値を計算し、その総和をデータ数で割った値(=平均値)も用いられます(0に近い方がよい)。
二項アウトカムならCox-Snell R2、NagelkerkeのR2(Cox-Snell R2のスケールされたバージョンで、最大値が1)、O’QuigleyのR2、RoystonのR2、RoystonとSauerbreiのR2Dなどがありますが、特にCox-Snell R2値の報告が重要で、これは将来のモデル開発研究のためのサンプルサイズ計算に必要だからです。
また、二項アウトカムやイベントまでの時間アウトカムに対する平均二乗誤差の拡張はBrier scoreであり、観察されたアウトカムと推定された確率を比較します。
嫌われがちなR2ですが、実際に表示しろと求められることもあまりないです。因果推論の文脈では基本的に用いないです。多くの場合は二値アウトカムなので、あまり馴染みがないかもしれませんがCox-Snell R2、NagelkerkeのR2を出せばいいと思います。これらはあくまで予測モデルのoverall fitを見ているだけで臨床的価値を見ているわけではないことに注意が必要です。
https://pubmed.ncbi.nlm.nih.gov/31093548/
2-8. Step 3-2: Calibration plot
較正(calibration)は、観察された値と予測された値が一致しているかどうかを評価することを指します。たとえば、観察されたイベントの確率がモデルによって予測されたイベントの確率(リスク)と一致しているかどうかです。
較正という単語はなかなか聞き慣れませんが、測定された値が基準となる値からどれだけずれているかを調べて、測定器が正しい値を示すように調整することです
二値アウトカムの場合、個々のイベント確率は観察できませんが(アウトカムが発生したかどうかしか分からない)、個々の観察されたアウトカムとモデルの推定イベント確率を用い、smoothing calibration curvesをfitさせることで較正を評価することができます(具体的な方法は補足資料にあります)。
外的検証時には、較正不足(miscalibration)が予想されます(注:適切な日本語の単語が分かりませんが、理想的なslopeを描きにくくなるということです)。主な理由として下記が挙げられています。
検証データセットと開発データセットの違いによるもの
母集団におけるcase-mix(疾患群分類の分布の違い)
アウトカムイベントの割合の違い
予測因子のタイミングと測定の違い
アウトカム定義の違い
モデル開発時の質が悪いことに起因するもの
開発時のデータセットが小規模
開発時のデータセットに代表性がない
ペナルティなしの回帰を用いて作成されたモデル

よく較正されたモデルが理想的とはいえ、較正不足のモデルにも臨床的な意義が(多少は)あります。例えば上図では、0.10程度までの場合は有用である可能性がありますし、0.40のところでも0.35と差がありますが、この差が臨床的なdecision-makingを可能性はあまり高くないと思われます。
強力なキャリブレーションは個別化された意思決定支援には望ましいのですが、非現実的であり、過度に複雑なモデルの開発を刺激して逆生産的とも言われています。モデル開発と外的検証は、中程度のキャリブレーションに焦点を当てるべきという意見もあります。
https://pubmed.ncbi.nlm.nih.gov/26772608/
2-9. Step 3-3: 較正性能の定量化
Calibration plotを図示してもやはり数字での評価は欲しいところ。よくあるのが、Hosmer-Lemeshowテスト、Nam-D’Agostinoテスト、Gronnesby-Borganテストのような関連テストが挙げられますが、これらを使用して評価されるべきではありません。
というのも、これらのテストでは、参加者の恣意的なグループ化が必要であり、サンプルサイズによってP値が影響を受けるのと、実際にどの程度較正不足かの定量化をしないためです。
較正の定量化には
・Calibration slope(理想的な値は1。傾きが大きいということは過小評価しがちなモデル、傾きが小さければ過大評価しがちなモデル)
・Calibration-in-the-large(理想的な値は0)
・Oservation/expected ratio(O/E)比(理想的な値は1。E/Oでも可)
があります。詳細は補足資料にありますが、論文を読む上では上記でいいでしょう。これらの値を信頼区間と共に報告するのがベストです。サブグループにおいても同様に報告した方が良いです。
また、較正曲線に基づく全体的な校正不足を定量化するために、Estimated/Integrated Calibration Indexといった指標があります。これらはそれぞれ、推定された校正曲線と理想的な校正の45度(対角線)線との間の二乗または絶対差の平均を測定します(MSEなどの指標の考え方に近いですね)。
Calibration plotとこれらの値を総合して判断することが大事です。
2-10. Step 3-4. 識別能の定量化
識別能は、そのモデルがアウトカムありとなしの群をどの程度正確に分類するかの指標です。岡田先生の記事が非常にわかりやすいです。当然ながら連続変数がアウトカムの時には使えません。
識別能はc統計量で定量化され、いわゆるROCの曲線下面積であるAUROCと同等です。0.5なら偶然よりも優れず、1.0なら完璧に識別できるということになります。
c統計量が高いか低いか?は文脈により、強力な予測因子が存在する分野では、c統計量が0.8であれば高いと考えられますし、予測が難しい分野では、0.6でも十分かもしれません。
ちなみにc統計量(AUROC)に加えてROC曲線を提示することはほとんど意味がありません(そうかもしれないけど…)。同様に、古典的によく用いられる感度や特異度などは、予測モデルにおいてはあまり意味がありません。なぜなら、予測モデルの価値はあるポイント(閾値)でいわゆる高リスクと低リスク群を定義することではなく、モデルの予測の全体的な性能にあるべきだからです。
これは結構難しくて、単純にモデルそのものに意味があるのかで悩みそうです。確かにROC曲線はc統計量だけあれば十分なのですが、やっぱり見た目的に欲しいですよね…。僕は査読者に要らないと言われない限り入れると思います。
臨床上の意思決定で閾値が重要である場合は、その閾値で臨床的有用性を評価すべきで、STEP 4で出てくるnet benefitやdecision curve analysisがあります。
Time-to-eventに対するc統計量に関してはHarrell’s c-indexが有名ですが、他にもEfronの推定量、Unoの推定量、GönerとHellerの推定量、case-mix調整推定量などがあります(どれもあまり見たことない…)。また、RoystonのD統計量は、識別性の別の尺度で、D統計量の値が高いほど、大きな識別性を示します。たまに出てきます。
一方、Harrell's c-indexとRoystonのD統計量は、すべての時点における全体の識別能になってしまうため、時間ごとの識別能をみるには時間依存性AUROCが良いでしょう(inverse probability of censoring weighted estimate of the time dependent area under the ROC curve for the time point of interest (t))。
2-11. Step 4. 臨床的有用性の定量化
予測モデルは予測して終わりではない、はよく聞く話ですが、最終的にどう臨床にインパクトを与えるのか?が重要です。
例えば、ある予測モデルで20%以上の死亡率があるから、「じゃあこういう介入(検査や治療、モニタリング)しよう」ということはあるでしょう。これを数値化したものとして、モデルを外的検証する際の臨床的有用性を評価する方法の一つとして、net benefitがあります。これは、利益(e.g., 改善された患者アウトカム)と害(e.g., 悪化した患者アウトカムや追加コスト)を比較する方法です。
ある検査を行った時に、
・結果が真陽性で得られるベネフィット(正確に診断がつく)
・結果が偽陽性であった場合に被るリスク(出血や誤診)
の差分を取れば、検査するかしないかが分かりますよね。
でも、どちらを重視するか?という「重み」は医師や患者さんによって違うので、その「重み」として考慮して計算した差分を求めたのがnet benefitになります。
補足資料としては、岡田先生やironmanさんのnoteがよくまとまっています。
そしてこのnet benefitがどの閾値で、どの程度他の選択肢と比較してメリットがあるのか?を図示化したものがdecisin curveです。面白いことに、decision curveの意味を正しく説明できる人は非常に少なく、図として出しているけど理解していないというケースもあるようです(ドキッ)。
折角なので別論文ですが(CC BY 4.0)、上記をさっくり解説します。例として、『前立腺がんの疑いがある場合、どのような患者さんに生検をするか?』という状況を考えましょう。
【前提事項】
・生検を行うことで悪性度の高い前立腺がんを見つけることができる(メリット)
・不要な生検は低悪性度のがんの過剰診断や出血等のリスクとなる(デメリット)
・悪性度の高い前立腺がんの有無をスクリーニングするための既存の検査X(感度40%、特異度90%)と、新規開発したAUC 0.79のモデル(model)を評価する
この場合、Decision curveは下記のように記されます。

図はY軸に利益、X軸に「検査による利益と害のどちらが重要か」の選好性がありますが、アウトカムの確率ではないことに注意が必要です。高悪性がんが心配なら図の左側に、生検による過剰診断が嫌なら右側に寄ります。医者にとって、高悪性度のがんを見逃すことが生検の害より大きいなら左側になります(おそらく多くの医者が左側に偏るのではないかと思います)。一方、90歳の患者さんなど、早期発見の価値に懐疑的なら、過剰診断などを懸念して右側に寄るでしょう。
この図には、testとmodelだけでなく、さらに二つの線があります。全員に生検する(intervention for all)と全員に生検をしない(intervention for none)です。全員に生検を行うという戦略が前者、絶対に生検をしないのが後者です。ここで大事なのはbenefitは良い結果であり、preferenceは医者・患者さんそれぞれであるということ。
その視点で見ると、どのような選好性であっても、左側の一部を除いてmodelの利益が大きいということになります。左側の一部は、とにかく高悪性がんを絶対に見逃したくない群なので、modelよりも「絶対に検査」の方が良いためinterventionl for allの方がやや上回ります。
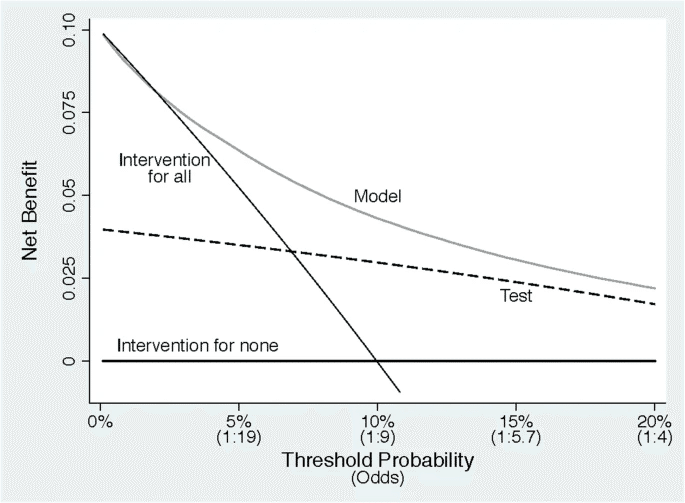
Decision curveからは、とにかく癌が心配なら、閾値確率が2%または3%未満の場合にのみ(見逃しが32〜48倍くらい悪いと思っている時)、モデルの使用を避けて検査した方がいいということがわかります。
Decision curveは図を見てどれが良いかを見るだけなら直感的なのですが、仕組みを理解しようとすると結構難しいです。特にX軸の解釈が難しく、「利益と不利益のオッズ・差分がどれくらいか」を表していて、アウトカムの確率ではないことに注意しましょう。例えば上記の例なら、X軸が悪性前立腺がんの確率ではない、という事です。
2-12. Step 5: 明瞭なデータ報告
とにかくTRIPOD Statementはちゃんと読んで従いましょう。著者らはこれに加えて、外的検証・モデル更新・新規モデル開発のためにCox-SnellまたはNagelkerkeのR2を報告すること、および予測分布(例えば、2-8の図に示されているように、アウトカムイベントのある人とない人のヒストグラム)を報告することを推奨しています。
2-13. Special topics(欠測・公平性・複数の外的検証・競合イベント)
欠損データの扱い
外的検証においてデータセットに欠測がある場合、complete case analysisや、単一代入、multiple imputationなどありますが、実は外的検証中の欠損データの取り扱いは未解決の問題で、現在進行中の研究分野です(そうなのか…)。もしモデル開発者が欠測の扱い方を指定していた場合(例えばmissing indicatorを用いる)は、外的検証もそれに従うべきです。とはいえそのようなケースはほとんど無いため、実際には外的検証は単一代入や複数代入などの妥当なオプションの範囲を検討することになります。
個人的には外的検証データセットに代入したデータを用いるのは気持ち悪いのですが、case-completeも変だしというジレンマ。
サブグループとアルゴリズムの公平性のチェック
Part 1参照。外的検証では、重要なクラスター(例えば、国、地域)やサブグループ(例えば、性別、民族グループで定義される)でのモデルの予測性能をチェックすることが重要と繰り返し述べられています。
複数の外的検証研究と個々の参加者データメタアナリシス
色々なの集団やセッティングへの適用に興味がある場合は複数の外的検証が必要になりますが、データ共有イニシアチブもしくはindividual patient data meta-analysisを用いて異質性を示すことができます。
競合イベント
例えば再手術を予測するモデルを構築した際に、術後早期の死亡が起こってしまうと再手術が発生しないことになります。もしモデルの予測が現実世界(つまり、競合するイベントが主要イベントの発生確率を減少させる状況)の文脈で評価される場合、予測性能を評価する際に競合イベントを考慮に入れる必要があります(下記論文参照)。
2-14. Part 2の結論
Part 1でも書きましたが、モデルが完全に検証されることはありません。予測性能はセッティング、対象集団、サブグループによって変化する可能性があり、医療の質の改善によって時間とともに劣化する可能性があるためです(これにより校正のずれ、すなわちcalibration driftが生じる)。
つまり、最終的に外的検証研究は、モデルの性能を評価するための必要かつ継続的な部分として見なされるべきであり、それがちゃんと研究コミュニティによって高く評価されるべきと書かれています。
それはもうプラットフォーム作るしかないような気がします。
専用の雑誌とかがあれば案外上手くいくかもしれません。
僕はこの2本を読んで色々疑問が湧いてCollinsにメールしたのですが返事をもらえませんでした笑
実際にどうするの?という部分はかなり雑誌や査読者によるであろうことを思うと、中々すぐにプラクティスを変えるのは難しいなという気持ちはあります。
1&2合わせてここまで読んで良かったと思う方は記事のサポートからお疲れ様していただけるとスタバのコーヒー代が浮いて喜びます。
この記事が気に入ったらサポートをしてみませんか?