
画像解析を高速化させるためのTipsわかりやすくまとめてみた(6) プリフェッチ

前回(第5回)は、SSE2とAVX2の比較をしました。ベンチマークの結果、同じメモリに対して繰り返すだけなら約1.8倍高速化出来ましたが、大きな配列に対して連続して計算すると、約1.03倍にしかなりませんでした。
キャッシュメモリ
CPUの中にはキャッシュメモリと呼ばれる高速なメモリがあります。低速なメインメモリへのアクセスを隠蔽するために、よく使うデータを演算装置の近くに高速なメモリに置いておくことで、速度性能を向上させています。
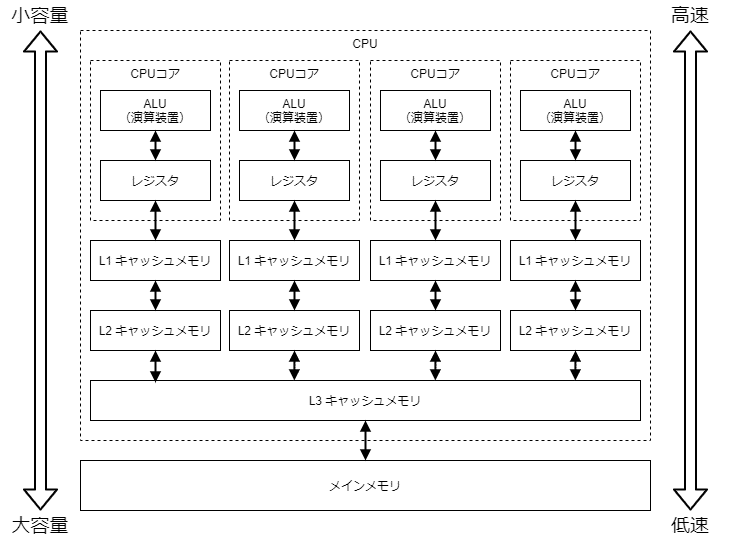
よく使うデータはキャッシュメモリに入っているのですが、時々使うデータは入っていません。そのときは、より外側のメモリから取り出す必要があります。より外側のメモリは容量は大きいのですが、速度は遅いため、演算装置の近くまでデータを持ってくるのに、時間がかかってしまいます。
前回のお題のように、大きな配列に入っているデータを使う場合は、逐次データを読み込むことになってしまい、時間がかかってしまって、メモリアクセスが足を引っ張る結果になってしまいます。
プリフェッチ
使う予定があるデータがあるのなら前もって演算装置の近くのメモリに読み込んでおけるとよさそうですね。プリフェッチという機能があります。
プログラマは前もって使うことが予想されるメモリを指定して、キャッシュメモリに読み込ませて置けることができます。SSEでは、_mm_prefetchという命令を使います。
実装
前回との違いは、_mm_prefetchを追加しただけです。引数に今後使う予定があるメモリアドレスを指定します。今回は4096バイト先のメモリを指定しました。どのメモリを先読みしておくと効率的かは、場合によると思いますが、今回は試行錯誤して決めました。
void benchmark_sse2_prefetch(void (*func)(const __m128i* x, const __m128i* y , __m128i* ans), int n, const uint8_t* x, const uint8_t* y, uint8_t* ans)
{
auto start = std::chrono::system_clock::now();
for (int i = 0; i < n; i += 16) {
_mm_prefetch(&x[i + 4096], _MM_HINT_T0); // ←追加
_mm_prefetch(&y[i + 4096], _MM_HINT_T0); // ←追加
func(reinterpret_cast<const __m128i*>(&x[i]), reinterpret_cast<const __m128i*>(&y[i]), reinterpret_cast<__m128i*>(&ans[i]));
}
auto end = std::chrono::system_clock::now();
auto elapsed = std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count();
std::cout << elapsed << std::endl;
}また、計算結果は直近では使わないので、キャッシュメモリには必要ないです。そういう場合は、_mm256_store_si256ではなく、_mm256_stream_si256を使うことで、キャッシュメモリには保存せず、直接メインメモリに格納することができます。
void average_avx2(const __m256i* px, const __m256i* py, __m256i* pans)
{
__m256i mx = _mm256_load_si256(px);
__m256i my = _mm256_load_si256(py);
__m256i mans = _mm256_avg_epu8(mx, my);
//_mm256_store_si256(pans, mans);
_mm256_stream_si256(pans, mans); // ←変更
}ベンチマーク
実行環境:
・CPU: 8th Generation Core i7
・OS: Ubuntu (WSL2)
・Compiler: g++ version 7.5.0-3ubuntu1~18.04
・Compile Options (通常版): -O3
・Compile Options (SSE2版): -O3 -msse2
・Compile Options (AVX2版): -O3 -mavx2
ベンチマーク結果(5試行平均):

プリフェッチなし版と比べて、約1.15倍速くなりました。
めでたしめでたし。
メンバー募集中です
アダコテックは上記のような画像処理技術を使って、大手メーカーの検査ラインを自動化するソフトウェアを開発している会社です。
機械学習や画像処理の内部ロジックに興味がある方、ご連絡下さい!
我々と一緒にモノづくりに革新を起こしましょう!
この記事が気に入ったらサポートをしてみませんか?