
画像解析を高速化させるためのTipsわかりやすくまとめてみた(5)

前回(第4回)は、整数型での四捨五入を、AVX2の整数型で実装しました。
今回は、もっと単純なお題で、SSE2とAVX2の比較をしてみたいと思います。
お題
乱数の入った80000000個の符号なし8bit整数型の配列を2つ(X, Y)を用意し、XとYの要素同士の平均値Zを求めます(ただし、小数点以下は切り上げ)。つまり、Z[i] = ceil(X[i] + Y[i]) です。
実装
前回までは、32bit整数型でしたが、今回は8bit整数型です。SSE2の場合はレジスタが128bitなので16個、AVX2の場合はレジスタが256bitなので32個、同時に計算できることになります。
さらに、なんと、SSE2とAVX2では、平均値の計算が1命令でできちゃいます。(_mm_avg_si128, _mm256_avg_si256)
// 通常版
uint8_t average_normal(uint8_t x, uint8_t y)
{
return (x + y + 1) >> 1;
}
// SSE2版
void average_sse2(const __m128i* px, const __m128i* py, __m128i* pans)
{
__m128i mx = _mm_load_si128(px);
__m128i my = _mm_load_si128(py);
__m128i mans = _mm_avg_epu8(mx, my);
_mm_store_si128(pans, mans);
}
// AVX2版
void average_avx2(const __m256i* px, const __m256i* py, __m256i* pans)
{
__m256i mx = _mm256_load_si256(px);
__m256i my = _mm256_load_si256(py);
__m256i mans = _mm256_avg_epu8(mx, my);
_mm256_store_si256(pans, mans);
}// ベンチマーク
void benchmark(uint8_t (*func)(uint8_t, uint8_t), int n, const uint8_t* x, const uint8_t* y, uint8_t* ans)
{
auto start = std::chrono::system_clock::now();
for (int i = 0; i < n; ++i) {
ans[0] = func(x[0], y[0]);
}
auto end = std::chrono::system_clock::now();
auto elapsed = std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count();
std::cout << elapsed << std::endl;
}
void benchmark_sse2(void (*func)(const __m128i* x, const __m128i* y , __m128i* ans), int n, const uint8_t* x, const uint8_t* y, uint8_t* ans)
{
auto start = std::chrono::system_clock::now();
for (int i = 0; i < n; i += 16) {
func(reinterpret_cast<const __m128i*>(&x[0]), reinterpret_cast<const __m128i*>(&y[0]), reinterpret_cast<__m128i*>(&ans[0]));
}
auto end = std::chrono::system_clock::now();
auto elapsed = std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count();
std::cout << elapsed << std::endl;
}
void benchmark_avx2(void (*func)(const __m256i* x, const __m256i* y , __m256i* ans), int n, const uint8_t* x, const uint8_t* y, uint8_t* ans)
{
auto start = std::chrono::system_clock::now();
for (int i = 0; i < n; i += 32) {
func(reinterpret_cast<const __m256i*>(&x[0]), reinterpret_cast<const __m256i*>(&y[0]), reinterpret_cast<__m256i*>(&ans[0]));
}
auto end = std::chrono::system_clock::now();
auto elapsed = std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count();
std::cout << elapsed << std::endl;
}int main()
{
static const int N = 800000000;
std::random_device rd;
std::mt19937 mt(rd());
std::uniform_int_distribution<> rand256(0, 255);
std::vector<uint8_t, aligned_allocator<uint8_t, 32>> x(N);
std::vector<uint8_t, aligned_allocator<uint8_t, 32>> y(N);
std::vector<uint8_t, aligned_allocator<uint8_t, 32>> ans1(N);
std::vector<uint8_t, aligned_allocator<uint8_t, 32>> ans2(N);
std::vector<uint8_t, aligned_allocator<uint8_t, 32>> ans3(N);
std::generate(x.begin(), x.end(), [&](){ return rand256(mt); });
std::generate(y.begin(), y.end(), [&](){ return rand256(mt); });
benchmark(average_normal, N, x.data(), y.data(), ans1.data());
benchmark_sse2(average_sse2, N, x.data(), y.data(), ans2.data());
benchmark_avx2(average_avx2, N, x.data(), y.data(), ans3.data());
std::cout << "ans1 == ans2: " << std::equal(ans1.begin(), ans1.end(), ans2.begin()) << std::endl;
std::cout << "ans1 == ans3: " << std::equal(ans1.begin(), ans1.end(), ans3.begin()) << std::endl;
return 0;
}ベンチマーク
実行環境:
・CPU: 8th Generation Core i7
・OS: Ubuntu (WSL2)
・Compiler: clang version 6.0.0-1ubuntu2
・Compile Options (通常版): -O3
・Compile Options (SSE2版): -O3 -msse2
・Compile Options (AVX2版): -O3 -mavx2
ベンチマーク結果(5試行平均):
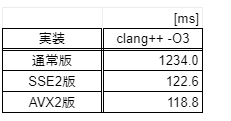
ほとんどかわりませんね…😇
おそらく、メモリアクセスに時間がかかっているのでは…
そこで、メモリアクセスをなくすため、80000000個の配列すべてを計算するのではなく、配列の先頭部分だけを80000000回繰り返し計算してみましょう。
ベンチマーク結果(5試行平均):
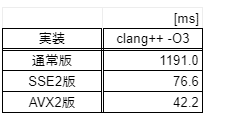
やりました! SSE2→AVX2で、約1.8倍になりました!
<次回に続く>
メンバー募集中です
アダコテックは上記のような画像処理技術を使って、大手メーカーの検査ラインを自動化するソフトウェアを開発している会社です。
機械学習や画像処理の内部ロジックに興味がある方、ご連絡下さい!
我々と一緒にモノづくりに革新を起こしましょう!
この記事が気に入ったらサポートをしてみませんか?