
画像解析を高速化させるためのTipsわかりやすくまとめてみた(4)

前回(第3回)は、整数型での四捨五入を、SSE2~SSE4.1の整数型で計算する方法を説明しました。
今回は、AVX2の整数型で計算してみます。レジスタ長が2倍になるから2倍速くなってくれるよね…?
割り算を使わない割り算のAVX2での実装
前回のコードとの違いは、変数の型が m128_t から m256_t に、 関数のプレフィックスが _mm128 から _mm256 になっているところです。また、アラインメントは、SSEの場合は16バイトに合わせましたが、AVXの場合は32バイトに合わせる必要があります。
#include <immintrin.h>
// __m256i を int32_t の配列としてアクセスするための共用体
union m256i_i32
{
__m256i m;
int32_t i[4];
};
// 逆数テーブル クラス
template <int NumBits, int DenBits>
class InvTable
{
int r[1 << DenBits] = {};
public:
constexpr InvTable() {
for (int i = 1; i < 1 << DenBits; ++i) {
r[i] = (1 << (NumBits + DenBits)) / i;
}
}
constexpr int operator[](int n) const {
return r[n];
}
};
constexpr int NUM_BITS = 9; // 分子のビット数
constexpr int DEN_BITS = 8; // 分母のビット数
// 逆数テーブル
constexpr auto inv_table = InvTable<NUM_BITS, DEN_BITS>();
// 割り算 (int32_t の __m256i)
inline __m256i div_int_avx2(__m256i mx, __m256i my)
{
auto a = reinterpret_cast<m256i_i32*>(&my);
__m256i mr = _mm256_set_epi32(
inv_table[a->i[7]], inv_table[a->i[6]],
inv_table[a->i[5]], inv_table[a->i[4]],
inv_table[a->i[3]], inv_table[a->i[2]],
inv_table[a->i[1]], inv_table[a->i[0]]);
__m256i mc = _mm256_mullo_epi32(mx, mr);
__m256i md = _mm256_add_epi32(mc, _mm256_set1_epi32(1 << NUM_BITS));
__m256i me = _mm256_srli_epi32(md, NUM_BITS + DEN_BITS);
return me;
}
// int型 avx2版
void div_round_int_avx2(
const __m256i* px, const __m256i* py, __m256i* pans)
{
__m256i mx = _mm256_load_si256(px);
__m256i my = _mm256_load_si256(py);
__m256i ma = _mm256_srli_epi32(my, 1);
__m256i mb = _mm256_add_epi32(mx, ma);
__m256i mans = div_int_avx2(mb, my);
_mm256_store_si256(pans, mans);
}ベンチマーク
実行環境:
・CPU: 8th Generation Core i7
・OS: Ubuntu (WSL2)
・Compiler1: gcc version 7.5.0 (Ubuntu 7.5.0-3ubuntu1~18.04)
・Compiler2: clang version 6.0.0-1ubuntu2
・Compile Options: -O3 -mavx2
ベンチマーク結果(5試行平均):
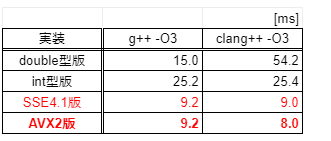
あれー。SSE4.1版とAVX2版で、ほとんど変わっていません。
(しかも、double型版が前回の結果とぜんぜん違う…)
考察
テーブルをランダムアクセスしたりしてるから、メモリアクセスで遅くなっているのだろうか?🤔
ちょっとお題が良くなかったような気がするので、次回は別のお題でやってみたいと思います。
ちなみに、テーブル使わずに、AVXの単精度浮動小数点数の割り算でやっても、速度変わらなかった…😇
// 割り算 (single float)
inline __m256i div_int_avx2_ps(__m256i mx, __m256i my)
{
__m256 mxs = _mm256_cvtepi32_ps(mx);
__m256 mys = _mm256_cvtepi32_ps(my);
__m256 mzs = _mm256_add_ps(
_mm256_div_ps(mxs, mys), _mm256_set1_ps(0.5));
__m256i mz = _mm256_cvttps_epi32(mzs);
return mz;
}
// int型 avx2版 (single float)
void div_round_int_avx2_ps(
const __m256i* px, const __m256i* py, __m256i* pans)
{
__m256i mx = _mm256_load_si256(px);
__m256i my = _mm256_load_si256(py);
__m256i mans = div_int_avx2_ps(mx, my);
_mm256_store_si256(pans, mans);
}メンバー募集中です
アダコテックは上記のような画像処理技術を使って、大手メーカーの検査ラインを自動化するソフトウェアを開発している会社です。
機械学習や画像処理の内部ロジックに興味がある方、ご連絡下さい!
我々と一緒にモノづくりに革新を起こしましょう!
この記事が気に入ったらサポートをしてみませんか?