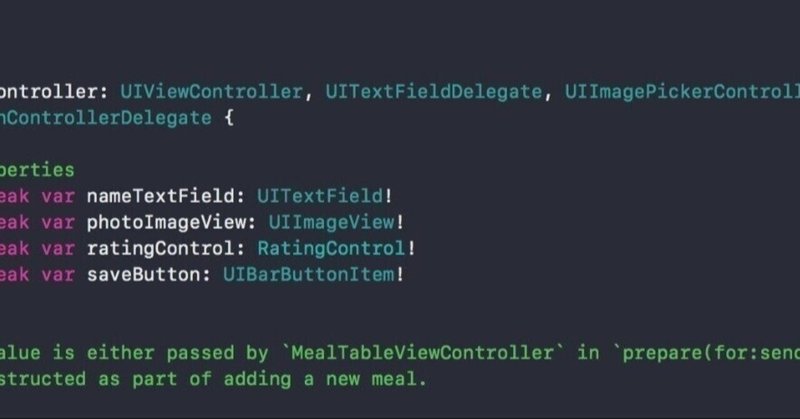
サンプルプログラム以下公式サイトより引用
import argparseparser.add_argument("square", type=int, help="display a square of a given number")parser.add_argument("-v", "--verbose", action="store_true", help="increase output ver
hugoを導入するにあたってのメモ
環境Mac OS Big Sur
ローカルの作業hugoのインストール
brew install hugo
hugoでプロジェクトの作成hugoで任意の名前のプロジェクトを作成する。 今回は"quickstart"とした。
この名前はなんでもいい。
hugo new site quickstartcd quickstartgit init
hugoのthemeの追加今回はmainroadを選択した。
cd themesgit