
6/22に発生したCloudFlareの障害メモ

はじめに
コンテンツ配信ネットワーク(CDN)のCloudflareが米国時間6月21日に発生させた大規模障害について、同社のblogで解説していたので、要旨をメモします。
ルーターのポリシーを書き換えるという作業は、IXが運用されるようになった四半世紀以上前から行われていたと思いますが、世界最大のユーザ数を誇るCDNでも、このような障害が発生したということに驚きを感じています。
保守作業効率化のための変更作業で、障害を起こしてしまったという胃が痛くなるような話ですが、ここからどのような教訓が得られるのでしょうか。
障害概要
まずZDNetの記事を引用します。
コンテンツ配信ネットワーク(CDN)のCloudflareは米国時間6月21日、同日に発生した大規模障害について原因を発表し、謝罪を表明した。
障害は保守性を重視する新しいアーキテクチャーへの移行作業中に発生したとしている。
同社によると、障害は東京や大阪を含む世界19カ所のデータセンターを結ぶ内部ネットワークを新しいアークテクチャーの構成に移行する作業中に発生した。MCPは、内部ネットワークにメッシュを構成する追加的なルーティングといい、これによって顧客サイトへの接続性を損なうことなく保守作業効率を高められるため、18カ月をかけて実装を準備してきたとしている。
移行作業は、協定世界時(UTC)の6月21日午前3時41分に開始し、19カ所のデータセンターに展開した午前6時27分に通信障害が発生した。午前6時58分に設定を元に戻す復旧作業に着手し、午前7時42分に復旧作業を終え、午前8時に障害対応を完了したという。
障害の影響が及んだのは同社ネットワークの4%だったものの、通信リクエストでは50%に及んだといい、世界各地でCloudflareのサービスを利用している膨大なウェブサイトへのアクセスなどが一時できなくなった。
同社は、MCPへの移行作業手順に問題があったとして、障害の影響を受けた顧客に謝罪した。なお、MCPはサービスの可用性を高める重要なものだとし、再発防止のために各種作業手順などを見直して慎重に移行を行っていくとしている。
背景
以下CloudFlareのブログを引用します。
Cloudflareは過去18か月間に渡ってアーキテクチャをより柔軟で復元力のあるものに移してきた。
その時も19のデータセンタでMulti-Colo PoP(MCP)とよぶアーキテクチャの変更作業を実施していた。
アーキテクチャはClosネットワークとして設計されていた。
これにより、信頼性が大幅に向上し、顧客のトラフィックを中断することなく、メンテナンスを実行できるようになった。
ただ、今回の作業対象はCloudflareで多くのトラフィックを処理しているところであり、ここでの問題は非常に幅広い影響を与える可能性があり、それが実施におこってしまった。
MCP構成のClosネットワークとは以下のようにL3でファブリックを構成するというもので、GoogleやFacebook、yahooなどが採用しているようです。今回、CloudFlareもこちらの構成に移行したようです。
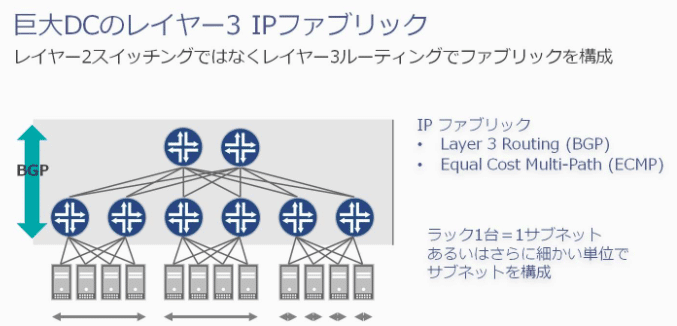
インシデントのタイムライン
事象発生の時系列は以下の通りとなります。
03:56 UTC:最初の変更実施
06:17:最繁トラフィックポイントの変更。ただしMCPに展開なし。
06:27:MCP対応に変更→オフライン化が展開されインスデント発生。
06:32:Cloudflareにてインシデント検知
06:51:原因調査のための設定変更実施
06:58:根本原因の特定。復旧作業開始
07:42:復旧が完了するも、切戻し作業を元に戻すなどし、一部再発。
08:00:インシデント終了
インシデントの影響
ではこのインシデントによってどのくらいの影響があったのでしょうか?
CloudFlareのblogでは、ネットワーク全体のわずか4%の影響で、リクエスト全体の50%に影響を与えたとのことです。

インシデントの原因
CloudFlareのblogでは具体的な問題が挙げられています。
ルーターに以下のような変更を行っていたところ、・・・・!?
policy-optionsの構文でアドバタイズのprefixを指定するところで、rejectが先に来てる!!!orz
これでは先にREJECTされてしまいます。
[edit policy-options policy-statement AGGREGATES-OUT]
term 6-DISABLED_PREFIXES { ... }
! term 6-ADV-TRAFFIC-PREDICTOR { ... }
! term 4-ADV-TRAFFIC-PREDICTOR { ... }
! term ADV-FREE { ... }
! term ADV-PRO { ... }
! term ADV-BIZ { ... }
! term ADV-ENT { ... }
! term ADV-DNS { ... }
! term REJECT-THE-REST { ... } ← REJECTがADVより前にきている! orz
! term 4-ADV-SITE-LOCALS { ... }
! term 6-ADV-SITE-LOCALS { ... }
[edit policy-options policy-statement AGGREGATES-OUT term 4-ADV-SITE-LOCALS then]
community delete NO-EXPORT { ... }
+ community add STATIC-ROUTE;
+ community add SITE-LOCAL-ROUTE;
+ community add AMS07;
+ community add EUROPE;
[edit policy-options policy-statement AGGREGATES-OUT term 6-ADV-SITE-LOCALS then]
community delete NO-EXPORT { ... }
+ community add STATIC-ROUTE;
+ community add SITE-LOCAL-ROUTE;
+ community add AMS07;
+ community add EUROPE;こちらのミスを複数のエンジニアによるピアレビューも行うも、検出できず、本番作業をしてしまったとのことです。
※ところでルーターはJUNOSなんですね。
この結果、サイトローカルプレフィックスのアドバタイズが停止され、オリジンサーバーへの到達性が削除されました。
オリジンに接続できないことに加えて、内部負荷分散システムが機能しなくになり、MCP内の小さいコンピューティングクラスターが過負荷になったようです。
修復とフォローアップの手順
CloudFlareではいくつかの改善領域を特定し、再発防止に取り組んでいくようです。
以下具体例です。
プロセス:データセンターを更新する方法に問題があり、MCP構成が考慮されない手順になっていました。今後はMCP固有のテストと展開の手順を含めるようにします。
アーキテクチャ:誤ったルーティングアドバタイズメントを引き起こしたポリシーステートメントは、意図しない誤った順序付けを防ぐために再設計します。
自動化:自動化された「commit-confirm」ロールバックを自動化できるように改善します。インシデント中の解決までの時間を大幅に短縮します。
最後に
内容は非常にイージーで、適切な有識者がレビューしていれば防げたように思えます。よくある事故が起こる背景には、相当数のヒヤリがあったのではないでしょうか。CloudFlareさんが根本原因まで立ち返って対処されることを望みます。
この記事が気に入ったらサポートをしてみませんか?