ビジネスに必要な情報を世界中から集めるクローリングの仕組みと今後の課題

Stockmarkのプロダクトは、5,000万件を超えるビジネス記事を基盤として提供されています。これらのデータがプロダクトの根幹の1つであり、記事を収集するクローリングは要といえます。
本記事では、1) 現在のクローリングの仕組み、2) 現在抱えている課題、 3) 未来へのアプローチ(新規チーム立ち上げ) の3点をご紹介いたします。
クローリングの仕組み
そもそもクローリングという言葉に耳慣れない方もいらっしゃるかもしれません。非常に簡単に説明すると、クローリングとは "WebページのHTMLを保存し、HTMLからURLを抽出すること" です。クローリングするプログラムは、一般に "クローラー" と呼ばれます。(詳細は英語版の Wikipedia 記事を参照ください。)
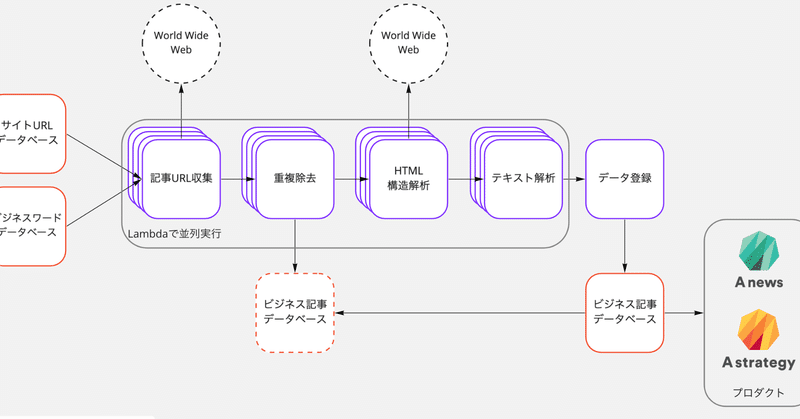
Stockmarkのプロダクトは、日々発生する膨大なビジネス記事(10万件以上)を常にクローリングし続けています。クローリング対象のURL群を起点として、短期間でURL群を巡回して記事を収集します。収集した記事は、必要なデータのみを取得するため、構造を解析し・余分な情報を削除します。
大量の記事に対して、これらの処理を、短期間・低コストで実現するためにAWS Lambdaを利用したスケーラブルなアーキテクチャで実装しています。
簡易アーキテクチャ図は次のとおりです。
Google検索じゃダメなのか?
ここまで、お読みいただいた方の中には「えっ、Googleも同じようにクローリングしているのでは?」と思われた方もいるかと思います。
もちろん、Google検索は網羅性のある素晴らしい情報を提供しています。一方で、Google検索だけでは迅速な解決が難しい課題も存在しています。
たとえば、プロダクト企画職の方が新規事業企画のために "AIでどういうビジネスを、だれがどのように提供しているのか知りたい" と考えたとします。このとき単にGoogleにて "AI" と検索すると、 "AIとは" という説明記事が大量に表示されます。そこで、他のクエリを並べてAND・OR検索を活用して、必要な情報をなんとか見つけだすわけです。
これは顧客にとって大きなペインの1つとなります。そこでStockmarkでは、必要なビジネス記事を、AIの力を用いてお客様に効果的に提供することで、ペインを解決しています。(本記事は、AIの裏側にある機械学習については説明しません。機械学習関連の記事を是非ご覧ください!)
このように、Stockmarkのプロダクトで多くのペインを解決しているわけですが、実際にはまだまだ解決すべき技術的課題が多く残っています。以下で、代表的な課題を2つピックアップして紹介します。
課題1. 記事収集の網羅率
実際にお客様からいただいた声として「Googleに比べると、検索ヒット数が少ない」というものがあります。
Stockmarkの収集する記事は、人力メンテで厳選されたURL群を起点として収集されています。起点からたどるリンクの深さを制限しているため、仮にURL群から遠い記事があると、収集漏れが発生してしまうのです。
今後、網羅率をさらに向上させていくためには、人力には限界があり、自動化が必要となります。また単に自動化するだけでは、記事ノイズも増えてしまうため、精度良くノイズを除去し、不要な記事をフィルタリングする必要があります。
また、収集する記事の情報構造(HTML構造)も常に一定というわけではありません。そのため、同じ記事抽出アルゴリズムを利用していると、誤った情報を抽出してしまう・そもそも抽出できない、といった課題が発生します。そこで、常に記事抽出アルゴリズムもアップデートしていく必要があります。
参考までに、Stockmarkでは情報抽出を
1. DOM操作を中心とした、HTMLセマンティクスを考慮した処理(Node.js)
2. 統計処理や機械学習処理を中心とした、記事テキストを考慮した処理(Python)
の2段構えで実装しています。今後、HTML構造やテキストに対してロバストな情報抽出アルゴリズム[^1]を構築したいと考えています。
課題2. 過去記事の活用
クローリングして保存した記事は、ノイズを減らしプロダクトで提供できるように、日々R&Dチームと連携してアルゴリズムをアップデートしています。このアルゴリズムアップデートにおいても現状で大きな課題が存在しています。
たとえば、ある時点で収集した記事についてはアルゴリズムAが適用されていたとします。後日、アルゴリズムが改良されて、アルゴリズムBが生まれたとします。このとき、アルゴリズムBのリリース以降に収集された記事は、アルゴリズムBが適用されるので問題ありません。しかし、アルゴリズムBが生まれる前の記事は、アルゴリズムAのみが適用されたままとなっています。
もちろん、遡ってアルゴリズムBを提供できればいいのですが、記事件数が5,000万超と膨大なことや、記事の保存形態に差分があるなど、細かな課題[^1]が存在しています。そのため、単純に最新のアルゴリズムを過去分に適用すればいいわけではないのです。
[^1]: 具体的なアルゴリズムや課題に興味のある方は、カジュアル面談を実施しておりますのでぜひそちらで話させてください。応募はこちらから!
オープンデータエンジニアリングチームを新規に立ち上げます!
幸いなことに、Stockmarkのプロダクト成長は右肩上がりとなっています。プロダクト成長を一気に加速するため、既存課題・新規に発生する課題を技術的観点で解決するオープンデータエンジニアリングチームを新規に立ち上げることにしました!
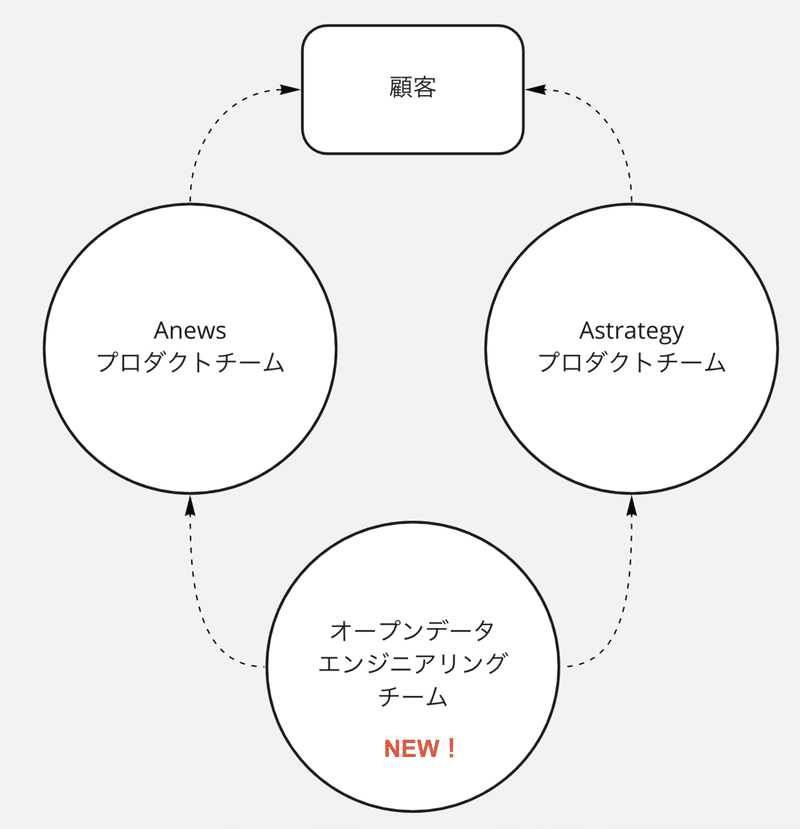
「あらゆるビジネスデータを網羅し、インサイトを提供する」
これが、新チームのミッションです。Stockmarkの全プロダクトの基盤となるオープンデータプラットフォームの開発に取り組んでみたい方、一度お話してみませんか!? ぜひ、お気軽に応募してみてください!