”犬か猫か”を判別する画像認識アプリを作ってみた

はじめに
新しいことにチャレンジしてみよう!ということでAidemyさんのプログラミング講座を受講しました。AIアプリ開発コースを受講。
最終的に成果物として、読み込んだ画像が「犬」か「猫」かを判別する画像認識アプリを作成しました。
↓↓実際の成果物はこちらです↓↓
本記事では学習のまとめを兼ね、犬猫判別アプリができるまでの過程をまとめております。
初心者の視点で書いているので、ご参考程度にお願い致します。
筆者の経験値と学習言語
読者さんに参考になるように、Aidemyさんの受講前の筆者のプログラミングレベルについて。
と、言っても書けるほどのスキルが全く無い初心者です。
・約10年前にC 言語を独学で学ぼうとして挫折(お恥ずかしい…
・Aidemyさん受講を決めた頃に、progateを利用。HTML&CSSを中級編まで
ちょこっとかじった程度、というのが伝わるでしょうか…
ちなみに、今回Aidemyさんの講座で学習したのはPython言語がメインですが、アプリ制作にあたってHTML&CSS、コマンドラインなども学びました。
開発環境
・PC
MacBook Air (13インチ, 2017) MacOS(BigSur ver11.5.2)
1.8 GHz デュアルコアIntel Core i5、メモリ8GB
・Google Colaborabory
・Visual Studio Code ver1.60.0
・Python ver 3.8.8
アプリ制作の流れ
今回行ったのが大きく分けて5つ。こちらをそれぞれまとめていきます。
・学習用犬猫画像の準備(kaggleのデータセット活用)
・犬猫判別用学習モデルの作成(pythonによる転移学習)
・アプリ動作用コードの作成(pyrhonのFlaskコード)
・HTML&CSS(webサイトの作成)
・アプリのデプロイ
モデル学習用画像の準備
犬か猫かをAIに判別してもらうために、事前にAIに覚えさせるために大量の画像を用意しなきゃいけないわけですが…
今回はkaggleで公開されているデータセットを活用させていただきました。
こちらのトレーニングセット、犬猫それぞれ約4000枚。合計およそ8000枚。
データ収集の際に便利だなぁ、と喜んだものの、その大量のデータをどうやってモデル学習に利用するかでつまづきました…
こちらの大量の画像は、GoogleColaboraboryで利用するわけですが、PCやGoogle Driveにダウンロードするのは得策ではないと判断。なるべく負担の少なく、今後とも利用できるようより効率的な方法を模索し、ほぼGoogleColaborabory内で処理できるようにしました。
まずはじめにkaggleのユーザー設定ページでAPIキーを取得して、PCにダウンロード。Google Driveにもkaggleフォルダを作成し、こちらは保存しておきます。
その後、専用のコードがあるのでそちらを使ってGoogleColaborabory内にダウンロード。
#kaggle.jsonのダウンロード
from googleapiclient.discovery import build
import io, os
from googleapiclient.http import MediaIoBaseDownload
from google.colab import auth
auth.authenticate_user()
drive_service = build('drive', 'v3')
results = drive_service.files().list(
q="name = 'kaggle.json'", fields="files(id)").execute()
kaggle_api_key = results.get('files', [])
filename = "/content/.kaggle/kaggle.json"
os.makedirs(os.path.dirname(filename), exist_ok=True)
request = drive_service.files().get_media(fileId=kaggle_api_key[0]['id'])
fh = io.FileIO(filename, 'wb')
downloader = MediaIoBaseDownload(fh, request)
done = False
while done is False:
status, done = downloader.next_chunk()
print("Download %d%%." % int(status.progress() * 100))
os.chmod(filename, 600)認証に成功すると、「Download 100%.」となります。
その後、GoogleColaboraboryのファイル内で利用できるように次のコードを入れてみました。
#PCからkaggleのjsonファイルのアップロード
from google.colab import files
files.upload()
#ディレクトリの新規作成
!mkdir -p ~/.kaggle
#作成したディレクトリにkaggle.jsonファイルを移動
!mv kaggle.json ~/.kaggle/
#kaggleのインストール
! pip install -q kaggle
#所有者のみ読み書き可能に設定
!chmod 600 /root/.kaggle/kaggle.jsonファイル選択が求められるので、事前にダウンロードしておいたkaggle.jsonを使います。当初はchmodのコードを入れていなかったのですが、安全を考慮して入れました。
ここまでのコードが正常に作動すれば、kaggleからデータセットを活用できるようなるので、次に使用したいkaggleのデータセットのAPIコマンドをコピペします。
#使用したいkaggleのデータセットのAPIコマンドをコピペ(URL:https://www.kaggle.com/tongpython/cat-and-dog)
!kaggle datasets download -d tongpython/cat-and-dog/contentフォルダにzipデータがダウンロードされました。
zipをダウンロードしたら、次はGoogleColab内で解凍しないといけません。
!unzip "cat-and-dog.zip"確認したところ、contentフォルダにtest_setフォルダ、training_setフォルダが出現。無事解凍に成功しました。
ようやくモデル学習に利用できる状態にこぎつけました。
※参考にしたサイト(一部)
学習モデルの作成
画像のダウンロードに成功したので、学習モデルの作成に進みます。こちらはAidemyさんの講座内で学習した内容を参考にさせていただいてます。
まずインポートの一覧
#ディレクトリの取得やモデルの保存
import os
from google.colab import files
#画像の読み込みと表示
import cv2
import numpy as np
import matplotlib.pyplot as plt
#転移学習
#tensorflow.の部分は省略しても良い
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.layers import Dense, Dropout, Flatten, Input,Activation
from tensorflow.keras.layers import Conv2D, MaxPooling2D
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras import optimizers画像処理のためにOpenCV、計算をしやすくするためにNumpy、モデルの動作確認を可視化するためにmatolotlib、機械学習を行うためにtensorflowを利用しています。
まずはじめに、用意した犬猫画像をリスト化
# 使用するデータセットのあるディレクトリを指定してファイル名の取得
training_dog = os.listdir('./training_set/training_set/dogs/')
training_cat = os.listdir('./training_set/training_set/cats/')
#.jpg抽出用のリストを作成しておく
path_dog = []
path_cat = []
#.jpgのみを抽出
for file in training_dog:
base, ext = os.path.splitext(file)
if ext == '.jpg':
path_dog.append(file)
for file in training_cat:
base, ext = os.path.splitext(file)
if ext == '.jpg':
path_cat.append(file)
#モデルに使用するリストを作成しておく
img_dog = []
img_cat = []
#読み込み→リサイズ→リストに追加
for i in range(len(path_dog)):
img = cv2.imread('./training_set/training_set/dogs/'+path_dog[i])
img = cv2.resize(img, (250,250))
img_dog.append(img)
for i in range(len(path_cat)):
img = cv2.imread('./training_set/training_set/cats/'+path_cat[i])
img = cv2.resize(img, (250,250))
img_cat.append(img)contentフォルダがカレントディレクトリになっていることが作業の過程で分かったので、そこから犬猫それぞれの画像を取得しました。
また、作業の過程で分かったのですが、今回利用したデータセット内に拡張子の無いファイルが紛れ込んでいるため、それを除外しないと学習時にエラーが起きることが判明。ディレクトリに1つ紛れてるだけでエラー…侮れません。
今回の場合、各ディレクトリに1つずつしか不要なファイルが紛れ込んでなかったので手動で消すこともできたのですが、コードを作成して.jpgのみ抽出するようにしました。
print("[抽出時の画像数]")
print("dog",len(path_dog))
print("cat",len(path_cat))検証を兼ねて出力して問題ないことを確認しつつ先へ進みます。
配列の作成(X→データセット、y→正解ラベル)
X = np.array(img_dog + img_cat)
y = np.array([0]*len(img_dog) + [1]*len(img_cat))
#ランダムに並び替え
rand_index = np.random.permutation(np.arange(len(X)))
X = X[rand_index]
y = y[rand_index]
# データを分割(トレーニング8:テスト2)
X_train = X[:int(len(X)*0.8)]
y_train = y[:int(len(y)*0.8)]
X_test = X[int(len(X)*0.8):]
y_test = y[int(len(y)*0.8):]
#正解ラベルをone-hotにする(分かりやすくする)
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
学習用の配列を作成。画像は計8,005枚利用。学習用に8割使用することにしました。
#VGG16のインスタンスの生成
input_tensor = Input(shape=(250, 250, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
#モデルの構築
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dropout(rate=0.25))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(rate=0.5))
top_model.add(Dense(2, activation='softmax'))
#モデルの連結
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
#VGG16の重みを固定(19層までVGG16で転移学習)
for layer in model.layers[:19]:
layer.trainable = False
#コンパイル
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(lr=1e-4, momentum=0.9),
metrics=['accuracy'])
#モデルの学習
history = model.fit(X_train, y_train, batch_size=100, epochs=10,validation_data = (X_test , y_test))モデルの学習については、講座で学習したVGG16を用いて転移学習を行なっています。19層までは転移学習、その後より精度を上げるべく自分なりに手を加えています。
ここまでで、学習がひと段落したので、次に関数を作成
# 画像を一枚受け取り、犬か猫かを判定して返す関数を作成
def pred_animal(img):
img = cv2.resize(img,(250,250))
pred = np.argmax(model.predict(np.array([img])))
if pred == 0:
return 'dog'
else:
return 'cat'webサイトで画像を読み込んだ際に、「犬か猫か」判別するようになってます。
その後、検証するべく幾つか出力
# モデルの精度分析(評価)
scores = model.evaluate(X_test, y_test, verbose=1)
print('Test loss:', scores[0])
print('Test accuracy:', scores[1])
# データの可視化
#pred_animal関数に写真を渡して10回犬か猫かを予測
for i in range(10):
img = cv2.imread('./training_set/training_set/dogs/' + path_dog[i])
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
plt.imshow(img)
plt.show()
print(pred_animal(img))
#モデルを表示
model.summary()・モデルの精度分析
・試しに犬の画像を10回読み込んで予測
・モデルの表示
以上の3つを行なってます。
最終的な結果はこちらになりました。
※犬の予測は一部抜粋

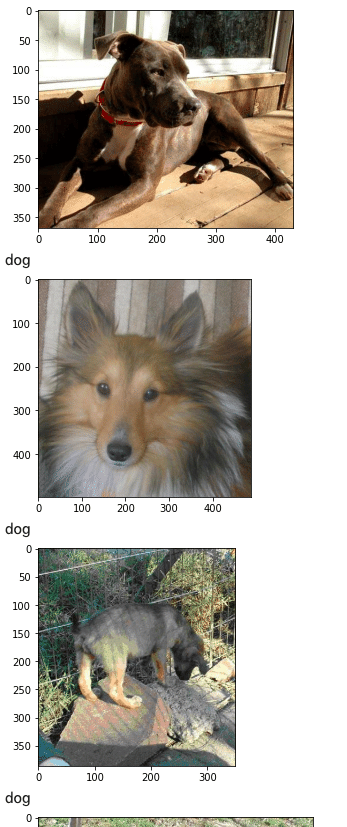

Test lossが0.12684059143066406、Test accuracyが 0.9831355214118958となりました。
#epoch毎の予測値の正解データとの誤差
#バリデーションデータのみ誤差が大きい場合、過学習
loss=history.history['loss']
val_loss=history.history['val_loss']
epochs=len(loss)
plt.plot(range(epochs), loss, marker = '.', label = 'loss')
plt.plot(range(epochs), val_loss, marker = '.', label = 'val_loss')
plt.legend(loc = 'best')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()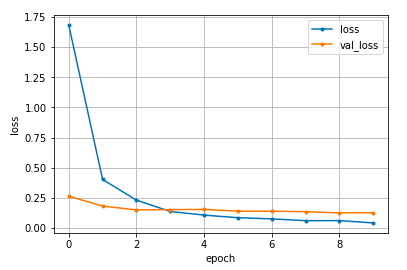
過学習していないかも念の為検証。エポックを重ねるごとに誤差が少なく安定しているようです。
精度や予測結果を確認し、最後に作成したモデルを出力しました。
#resultsディレクトリを作成→学習モデルを保存→ダウンロード
result_dir = 'results'
if not os.path.exists(result_dir):
os.mkdir(result_dir)
model.save(os.path.join(result_dir, 'model.h5'))
files.download( '/content/results/model.h5' ) 精度向上に向けて
完成後のコードしか上げていないのですが、当初エラーなく出力に成功した段階ではTest lossが0.64572、Test accuracyが0.69144でした。正解率が約69%から最終的に98%まで向上した要因として、実際に調整してみたところは2点。
・DropOutを追加
→元々rate=0.5のみ設定していたのですが、rate=0.25を追加。約4%ほど正解率に変化が見られました。
・画像のサイズを変更
→最初は画像サイズを(50,50)にリサイズしていたのですが、最終的に(250,250)へ変更。正直98%まで引き上げられたのは、画像サイズを大きくしたことが一番強いです。(300,300)も検討したものの、出力時の負荷と時間がかかるため、断念しました。
より精度を上げようとその他エポック数やバッチサイズの変更も試してみました。エポック数に至っては5~15,バッチサイズに関しては15~150あたりを小刻みに繰り返し試行しましたが、明らかな変化が見えませんでした。
画像を水増しして学習精度を上げよう、とも考えました。試しに約8000枚の画像を反転させて倍にしたところ、精度が5%ほど下がったので水増しも無しに。
精度を上げるには更なる時間が必要そうです。
Flaskコードの作成
webページで画像を読み込んで予測結果を出すためのコードをPythonで作成
こちらはVScodeを利用しました。実際のコードはこちらです↓↓
import os
from flask import Flask, request, redirect, render_template, flash
from werkzeug.utils import secure_filename
from tensorflow.keras.models import Sequential, load_model
from tensorflow.keras.preprocessing import image
import numpy as np
classes = ["dog","cat"]
image_size = 250
UPLOAD_FOLDER = "uploads"
ALLOWED_EXTENSIONS = set(['png', 'jpg', 'jpeg', 'gif'])
app = Flask(__name__)
def allowed_file(filename):
return '.' in filename and filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS
model = load_model('./model.h5')#学習済みモデルをロード
@app.route('/', methods=['GET', 'POST'])
def upload_file():
if request.method == 'POST':
if 'file' not in request.files:
flash('ファイルがありません')
return redirect(request.url)
file = request.files['file']
if file.filename == '':
flash('ファイルがありません')
return redirect(request.url)
if file and allowed_file(file.filename):
filename = secure_filename(file.filename)
file.save(os.path.join(UPLOAD_FOLDER, filename))
filepath = os.path.join(UPLOAD_FOLDER, filename)
#受け取った画像を読み込み、np形式に変換
img = image.load_img(filepath, grayscale=False, target_size=(image_size,image_size,3))
img = image.img_to_array(img)
data = np.array([img])
#変換したデータをモデルに渡して予測する
result = model.predict(data)[0]
predicted = result.argmax()
pred_answer = "これは " + classes[predicted] + " です"
return render_template("index.html",answer=pred_answer)
return render_template("index.html",answer="")
if __name__ == "__main__":
port = int(os.environ.get('PORT', 8080))
app.run(host ='0.0.0.0',port = port)こちらのコードはAidemyさんの講座のコードをほぼ利用させていただいたのですが、読み解くので精一杯でした。
webページで画像を読み込み後、結果が出ずにエラーになる問題が起き、原因を理解するのに時間がかかりました…
改めて抜粋するとこちら↓
#受け取った画像を読み込み、np形式に変換
img = image.load_img(filepath, grayscale=False, target_size=(image_size,image_size,3))
img = image.img_to_array(img)
data = np.array([img])モデル作成時のリサイズ条件と、しっかり一致しているかが肝だったようです。
条件が一致していないとそりゃあ予測できないよなぁ、と反省しました。
HTML&CSSのコード作成

webページの作成に関しては、事前にProgateで学習していたことを参考にしつつ作成しました。
素材に関してはこちらのサイトの素材を活用しています。
HTMLのコード
<!DOCTYPE html>
<html lang='ja'>
<head>
<meta charset='UTF-8'>
<meta name='viewport' content="device-width, initial-scale=1.0">
<meta http-equiv='X-UA-Compatible' content="ie=edge">
<title>Dog or Cat …??</title>
<link rel='stylesheet' href="../static/stylesheet.css">
</head>
<body>
<header>
<div class="header-contents">
<a class="header-logo" href="#">Dog or Cat …??</a>
<img class="header-img" src="https://cdn.pixabay.com/photo/2014/04/03/00/42/footprints-309158_960_720.png" alt="Pad">
</div>
</header>
<div class='main'>
<div class="main-contents">
<div class="main_logo">
<img src="https://cdn.pixabay.com/photo/2012/05/07/03/55/animals-47877_960_720.png" alt="DogCat">
<h1>Dog or Cat ...??</h1>
</div>
<br>
<h3>あなたが選んだ写真は</h3>
<h3>犬ですか?</h3>
<h3>猫ですか?</h3>
<br>
<p>読み込んだ画像が「犬」か「猫」かを判別します。</p>
<p>「犬」か「猫」と思われる画像をお選び下さい。</p>
<form method='POST' enctype="multipart/form-data">
<input class='file_choose' type="file" name="file">
<input class='btn' value="送信" type="submit">
</form>
<div class='answer'>{{answer}}</div>
</div>
</div>
<footer>
<div class="footer-contents">
<img class='footer_img' src="https://cdn.pixabay.com/photo/2014/04/03/00/42/footprints-309158_960_720.png" alt="Pad">
</div>
</footer>
</body>
</html>CSSのコード
/* CSSのリセット */
html, body,
ul, ol, li,
h1, h2, h3, h4, h5, h6, p, div {
margin: 0;
padding: 0;
}
body {
font-family: 'Hiragino Kaku Gothic ProN W3', sans-serif;
}
li {
list-style: none;
}
a {
text-decoration: none;
}
/* ここまで */
header {
background-color: #f0fff0;
height: 60px;
width:100%;
z-index:10;
position:fixed;
top:0;
left:0;
}
.header-contents {
margin:0 auto;
width:95%;
}
.header-img {
float:right;
height:60px;
}
.header-logo{
float:left;
padding:15px 0;
font-size:20px;
color:#444444;
}
.main {
width:100%;
background-color:#fff0f5;
color: #444444;
text-align: center;
padding:30px 0 180px 0;
}
.main-contents{
width:95%;
margin:0 auto;
}
.main-contents img{
height:300px;
}
h1{
position:relative;
top:-35px;
text-decoration: underline ;
}
h3 {
padding: 2px 0;
opacity:0.9;
}
p {
padding:2px 0;
opacity:0.9;
}
.answer {
padding:40px 0;
}
form {
padding:30px 0;
}
footer {
background-color: #f5f5f5;
height: 110px;
width:100%;
border-top:3px solid #eee;
}
.footer-contents{
margin:0 auto;
width:95%;
}
.footer_img {
height: 100px;
padding:5px 0;
float:left;
}上部緑部分は固定されるようにしました。
サイド部分も画面表示の状況に応じて表示が変わるように工夫したつもりです。(つもりでした…)
※デプロイ後に分かったのですが、スマホよりアクセスすると表示がおかしいようです。
今後PC以外のデバイスでの表示の改善も考えようと思います。
HTML&CSSのコーディングは事前学習の効果もあってか比較的短時間で終わりました。
個人的に頭抱えたのは、VScodeでHTML&CSSのコーディング状況をどうやって随時確認するか。
相性の良い拡張機能を探して使い方を理解するのに時間がかかりました。
私個人としては、こちらのLive Serverが使いやすかったです。
Web公開について(デプロイ)
アプリの公開にあたってHerokuを利用させていただきました。
Aidemyさんの講座内でデプロイ方法をご教授いただいたのですが、Macのターミナルとの戦いでした…
最初、教わった通りにターミナルにコードを打ち込んでるのに何度も試してもエラーが起きるので原因を模索するのに苦労しました。
個人的に引っかかって印象的だったところを一点
・PCを家族で共有していた
特殊事例かもしれませんが、実は家族のMacBookを借りてました。(自分のが古すぎて処理が重いため)
デプロイする際は、自分自身のPCアカウントが「管理者設定」になっているかどうかをよく確認した方がいいです。状況次第ではエラーが起きます。
動作検証、考察
モデル精度としては正解率約98%ということだが本当に…???と、いうことで検証。
そもそも今回「犬猫判別アプリ」にした理由としては、飼い犬の写真ばかりスマホにあるからだったりします。せっかくなら我が愛犬の画像を検証の際に使ってみたい…という己の欲望が発端。
何回か試して大半は犬判定だったのですが、正解率98%ってそれは嘘じゃないかい…?という感覚になる頻度で猫判定になりました(泣)家族にも試してもらいましたが100回も試さぬ内に何度か猫判定になってます。
やはり動物の品種だったりカットだったり、毛色だったり撮影時のポーズだったりで判別を間違ってしまうことが考えられます。
最後に
今回accuracyの数値重視してしまったのですが、より学習を深めて精度を上げていくのであれば、画像の量をより多く増やした上で高い精度を上げられるのが理想ではないかと思いました。
8000枚ってそこそこの枚数だと思ってましたが、私の直近の愛犬フォルダの画像数を見たら4600枚ほど入ってました。「犬の写真」「猫の写真」と言ってもバリエーションはかなり多くあるので、まずはより多くのデータを収集する。改めてデータ収集の重要さを感じます。
時間の兼ね合いもあるのですが、記事を振り返ると「精度が低くなるから画像の水増しをやめた」という結果に落ち着いてしまったところを特に反省しています。
実際に使用した際に、正確な結果が出るのが望ましいですよね…。
講座で学ぶ主な学習言語はpythonだったのですが、アプリ制作にあたってHTML、CSS、コマンドの使い方やデプロイの方法など触れるものが沢山ありました。
制作の過程でチューターさんにご教授いただくこともありましたが、自身で調べることで知見を広げることの大切さも感じています。
エラーに何度も苦しめられましたが、乗り越えていく度に理解が深まる上に、結果としてアプリを一つ作ることができたのは、貴重な経験になりました。
今後、講座で学んだことをベースにしつつ、より精度を高めるために引き続きトライ&エラーで学習に励もうと思います。
自分の成長に繋げるためにスキルアップ資金にしたいと思います。差し支えなければご支援お願いします!