機械学習のめもめもめもめも

損失関数はバリアンス、バイアス、ノイズに要素分解できる(ただし回帰のみ)
・バリアンス 予測値の分散。でかいと過学習状態
・バイアス 予測値のEと正解のEの差分。でかいと未学習(単純に正解と予測の乖離がでかい状態)
・ノイズ MLでフィッティングできない
バイアスとバリアンスはトレードオフ(そりゃそうだ)
L1正則化 ラッソ 変数選択 スパース性(少ない特徴でいい精度 的な)
L2正則化 リッジ 過学習防止
スパース性
「あらゆるものごとに含まれる本質的な情報はごくわずかである」
⇨【背景】オッカムの剃刀 「ある事柄を説明するためには、必要以上に多くを仮定するべきでない」
機械学習における「validation」は、一般的に「モデルの汎化性能の検証」のこと
=テスト誤差 求める方。
ホールドアウト検証 (Hold-out Validation)
学習データとテストデータ(検証データ)に分割するやつ
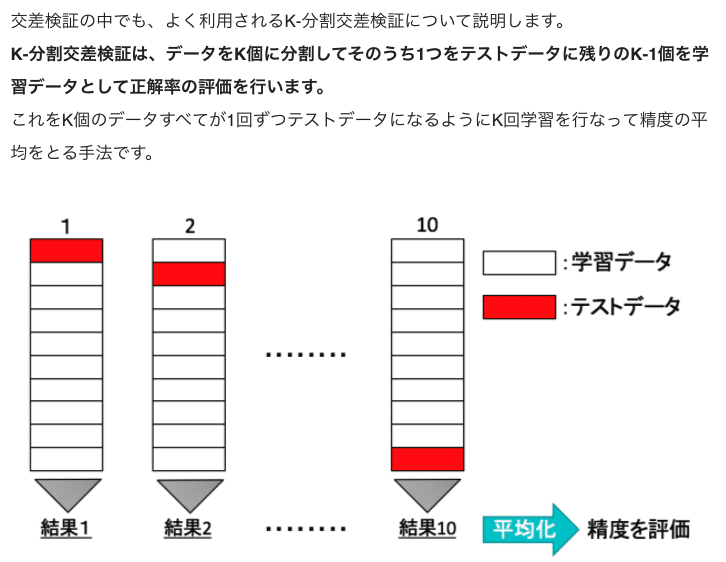
交差検証 (Cross Validation)
用意したデータを複数個に分割して分割した回数分学習、評価を繰り返す。K分割交差検証(K-fold Cross Validation)はK個に分割してK回学習・評価繰り返す。
精度は平均とる。
precision 適合率 TP/TP+FP 正確性に関する。ポジティブと判定したもののうち本当にポジティブだった確率
recall 再現率 TP/TP+FN 網羅性に関する。実際はポジティブなデータのうちポジティブと予測できた確率
真陽性=TP 偽陰性=FN 偽陽性=FP 真陰性=TN
ドロップアプト
学習時には学習ステップごとにランダムにノードを消去する。
推論時は全ノードを利用。よって学習時に消去されたノードについても重みの学習はしておく必要がある(ステップごとに消去されるノードが異なるため可能)
ドロップアプトはアンサンブル学習(バギング)と捉えることができる。
バギング=過学習を抑えることが可能
画像認識分野の歴史
1982 ネオコグニトロン 画像の濃淡パターンを検出する単純型細胞(S細胞)と物体の位置変更を許容する複雑型細胞(C細胞)の2つの層が交互に積み重なっている
1998 LeNet
2012 AlexNet ILSVRC2012で初めてNNがSVMよりも良い精度を出した
2014
1位 GoogLeNet インセプションモジュール(Inception モジュール)。
2位 VGG 3×3のカーネルを何回も繰り返す。デッカいカーネルよりも小さなサイズのカーネルを何回もかける方が計算量は小さい
2015 ResNet 層が深くなると勾配消失する問題に対してスキップ構造で解決。152層。
Inceptionモジュール
1 つの入力画像に対して、複数の畳み込み層(1×1, 3×3, 5×5)を並列に適用し、それぞれの畳み込み計算の結果を最後に連結している。この一連の作業をモジュールとしてまとめられ、Inception モジュールと呼ばれている。
CEC(Constant Error Carousel, 記憶セル)LSTMにおいて情報を記憶する構造。忘却ゲート、入力ゲート、出力ゲート
GRU(Gated Recurrent Unit) LSTMを少し簡易化したやつ。リセットゲートと更新ゲート
入力重み衝突問題
「今の時点では関係ないけど将来は関係ある」という入力が与えられた場合=今は小さくしたいけど将来は大きくしたいという矛盾
出力重み衝突問題
上記の出力ver
セグメンテーション ピクセルごとに領域予測やクラス化 SegNet, U-net
物体検出 矩形でくくるやつ
⇨検出&分類を同時にやるやつ YOLO, Faster R-CNN, SSD
Attention エンコーダ(入力分を処理するモデル)の出力を固定長の系列としてデコーダ(出力分を予測するモデル)に渡す
Transformer Attentionのみを使用したモデルであるGPUを有効活用できる。従来のRNN/LSTMは時系列に逐次的に処理するためGPU活用・並列化が困難。
BERT
2018年 Google。双方向Transformerモデル。代表的なタスクにMLM(Masked Language Model, 穴埋め問題)とNSP(Next Sentence Prediction, 連続した2文かどうか)
2018年1月 Google が Cloud Auto MLを公開。NAS(Neural Architecture Search)と呼ばれるモデルのアーキをのものを最適化する理論
NASは強化学習のアーキテクチャを応用。Controller RNN が設定したChild Networkを学習。学習後のChild Network のAccuracy をController RNN の報酬とする。この報酬をもとに方策勾配法(REINFORCEアルゴリズム)によってController RNNを更新

XAI(Explainable AI)
LIME, SHAP 特定のデータサンプルに着目し、単純なモデル(線形回帰とか)で近似することで予測に寄与する因子を推定する。表形式データ(csvとか)を入力とするモデルの出力根拠を示す技術。入力にカテゴリカル変数や順序変数があるなら必ずone-hot表現にする必要がある。
CAM, Grad-CAM 画像データの解釈性に用いられる手法。最終畳み込み層の出力特徴マップを活用して、画像内で予測に寄与した箇所を可視化する
米国国防先端研究計画局(DARPA)は、XAIプログラムとして、COGLE (COmmon Ground Learning and Explanation)を開発しているXeroxのPARC研究所をはじめとする企業や大学が複数参画するプロジェクトに投資を行なうなどXAIの様々な手法追求の取り組みを本格的に展開している。
派生モデル 既存の学習済みモデルを転移学習させたモデル
蒸留モデル 既存のモデルの入力値と出力値を利用して、そこから新たなプログラムを作成することで得られたモデル

ディープフェイクへの対策
Deep Vision まばたきの不自然さを検出
オプティカルフロー 動画内のオブジェクトの動きをベクトルで表現。ディープフェイクとリアル動画のフローを比較することで検出
アーティファクト 画像加工の証拠を検出する手法。GANには画像生成時に特定のフィンガープリントが残る(らしい)。そいつを使う。
ELSI(Ethical, Legal and Social Implications) 倫理的・法的・社会的な課題
AIに対する責任体制、セキュリティ、不正対策
オプトアウト制度(オプトアウト方式)
「オプトアウト方式」とは、個人情報を第三者提供するにあたって、その個人情報を持つ本人が反対をしない限り、個人情報の第三者提供に同意したものとみなし、第三者提供を認めること。
GDPR(General Data Protection Regulatio)
2018年5月25日から適用開始。EEA内に拠点がなくとも適用される可能性がある。適用範囲は主に以下の2つ。(出典)
・GDPRは、管理者又は処理者がEEA内で行う処理に対して適用される。
・GDPRは、管理者又は処理者がEEA内に拠点を有しない場合であっても、以下のいずれかの場合には適用される。
①EEAのデータ主体に対し商品又はサービスを提供する場合
②EEAのデータ主体の行動を監視する場合

ここでいうデータ主体はEEAの個人なりなので、管理者、処理社者(=例えばEEAに拠点を持たない日本の会社)がEEA顧客にサービスを提供すると対象になる可能性がある。
人間中心のAI社会原則
3つの基本理念
・人間の尊厳が尊重される社会(Dignity)
・多様な背景を持つ人々が多様な幸せを追求できる社会(Diversity&Inclusion)
・持続性ある社会(Sustainability)
7つのAI社会原則
1. 人間中心の原則
2. 教育・リテラシーの原則
3. プライバシー確保の原則
4. セキュリティ確保の原則
5. 公正競争確保の原則
6. 公平性、説明責任及び透明性の原則
7. イノベーションの原則

限定提供データ
業として特定の者に提供する情報として電磁的方法により相当量蓄積され、 及び管理されている技術上又は営業上の情報をいいます(不競法2条7項)。
1.限定提供性 ー業として特定の者に提供する情報であること
2.相当蓄積性 ー電磁的方法により相当量蓄積されていること(相当量の定義はデータにより異なる)
3.電磁的管理性 ー電磁的方法により管理されていること
デンドログラム(=樹形図)
⇨これを活用するクラスタリングが階層型クラスタリング(群平均法、ウォード法など)
次元圧縮(削減)
・t-SNE 高次元データを2次元又は3次元に変換して可視化するための次元削減アルゴリズム。ヒントン教授が開発。"t-" はt分布の"t-"
・主成分分析
Cutout Dropoutは全結合層には効果があるがCNNでは正則化効果限定的。入力画像をマスクで欠落させることでより強い正則化の効果を作り出した。マスクの形状は単純なサイズ固定の正方形(固定値0)を利用
Random Erasing
・画像に対してマスクを行うか行わないかランダムに決定
・マスクする場合は画像の何%にマスクするかハイパーパラメタ範囲内でランダムに決定
・次に、同じく予め決められた範囲内でマスクのアスペクト比を決定
・マスクないの画素を0から255のランダムな値に変更
data argumentation, 画像データ拡張
・CutMix Cutoutの改良版。画像を二枚用意し一つの画像をもう一枚にコピーする手法
・Mixup 2つの画像を合成して新しいサンプルを作成する手法
MobileNet 2017(V1),2018(V2)がGoogle によって発表された。モデルのサイズが小さく計算量・必要メモリも少なく済んで精度もそれなりに高い水準を維持しているモデル。エッジ専用というわけではなく計算リソースの限られたサーバーなどでの利用も想定している。Depthwise Separable Convolution を利用している
Depthwise Separable Convolution 畳み込みの計算を分割することで,計算量の減少を達成した
NASNet 2017年Google発表。検出データセット「COCO」や画像分類データセット「ImageNet」といった大規模データセットに適応するためのAutoMLアーキテクチャ。CNNの畳み込みやプーリングをCNNセルと定義し,CNNセルの最適化を行う
MNASNet AutoMLを参考にしたモバイル用のCNNモデル設計
インスタンスセグメンテーション 矩形で物体抽出
セマンティックセグメンテーション ピクセルで物体抽出だが、同一クラスで異なる対象が隣接しているとその境界を識別するのが困難
パノプティックセグメンテーション セマンティックセグメンテーションとインスタンスセグメンテーションを組み合わせたタスク。2020年にGoogle が初めてのEnd-to-End Model のMax-DeepLabを開発。Max-DeepLabはTransformerとCNNをうまく組み合わせたモデル
U-net
FCN(fully convolution network)の1つであり、画像のセグメンテーション(物体がどこにあるか)を推定するためのネットワーク。FCNは全結合層を畳み込み層に置き換え、物体がどこにあるかを識別可能とした。何度も畳み込みを行い小さくなったヒートマップ(特徴マップ)をUp sampled層という層を通して復元(Up sampling)し入力と同じ解像度の出力を得る。(De- convolutionが有名)
Dilation convolution(Dilated Convoluton)
Dilated Convolution は、フィルターとの積を取る相手の間隔をあける畳み込みのことです。

Open Pose
カーネギーメロン大学のZhe Caoらが2016年に論文発表した,2D画像の複数人物の姿勢を可視化し,効率的に推定する,Bottom-up approachのモデルである.手法として,まず入力画像から部位の位置の推定(S・confidense maps)と,部位の連関を表す(L・Part Affinity Fields(PAFs))を算出し,
その後SとLの集合から同じ人物の部位を組み合わせ、姿勢の状態を出力する。
Backpropagation Through Time(BPTT) RNNで使う逆誤差伝播法。時間軸を遡って勾配計算を行うためこのように呼ばれる。
音声スペクトルから得られる情報
・音声信号スペクトル 声帯の振動に対応した、個人が持つ「声の高さ」
・スペクトル包絡 声道・鼻腔における共振・反共振特性に関連した各音韻ごとの違い
メル周波数ケプストラム係数 音声認識や音楽ジャンル検索などで使われる特徴量であり,人間の聴覚特性を考慮した周波数スペクトルの概形
フォルマント周波数
言葉を発してできる複数の周波数のピークをフォルマントと呼び、声道の共振周波数をフォルマント周波数と呼ぶ。なお、周波数の低いものから順に第1フォルマント周波数,第2フォルマント周波数,…と呼ばれる
メル尺度 心理学者のStanley Smith Stevensらによって提案された。人間が感じる音の高さに基づいた, 音高の知覚尺度
音素 意味の違いに関わる最小の音声的な単位を音素(phoneme)といい,音声認識では音声データから特徴量を抽出するために,音素の抽出やノイズ除去のようなデジタル信号の波形に変換を行う
音韻論 音素について研究する言語学の一部門。音韻とはある特定の言語の音の体系のことを指し、例えば日本語の「あ」は「あ・い・う・え・お」という体系の一部である
WaveNet 音声認識や音声合成に利用できるモデルで、量しかされた音声を一つずつ、1秒間に16000個の音声データを学習データとして学習する
スキップグラム ある単語を与えて周辺の単語を予測するモデル
CBOW スキップグラムの逆で周辺の単語からある単語を予測するモデル
fastText 個々の単語を高速でベクトルに変換しテキスト分類を行うモデルである. word2vecとの違いとして、単語の表現に文字の情報を含めて, 存在しない単語を表現しやすくすることができる。
ELMo 文脈から意味を演算するモデル。双方向のLSTMで学習することにより, 同じ単語でも文脈によって異なる表現を獲得することができる手法である。
CTC(Connectionist Temporal Classification)
音声認識において,入力された音声を音素として出力したいが,その音素数が必ずしも入力された音声と一致するわけではなく矛盾が生じる場合がある。これを,空文字を追加することで解決する手法。
sequence-to-sequence(Seq2Seq) 入力も時系列なら出力も時系列。
Self-Attention Transformerで採用されているネットワーク機構。入力Queryと索引Memoryが同じAttentionです。
Source-Target Attention(Encoder-Decoder Attention)
入力Queryと索引Memoryが別物のAttention。過去の内容からsource(入力)とtarget(出力)の内容が違うものの関連を求めるもの。
画像は「お腹が減った」(過去の発話)→「ラーメン食べよう」という発話応答を学習する場合です。

MNIST
さまざまな画像処理システムの学習に広く使用される手書き数字画像の大規模なデータベース。
GLUE
言語理解タスクをベンチマークするためのデータセット
Vision Transformer
自然言語処理の分野で発展したTransformerを画像処理に流用したもの。画像を単語のように分割することによりCNNを使用せず,Transformerに近いモデルを使用している。
DQN
強化学習のQ学習にディープラーニングを組み合わせたもの深層強化学習
Double DQN
DQNはたまたまQ値が高いところを学習してしまう場合があり,それを防ぐ手段にDQNを二重化したもの
デュエリングネットワーク
行動価値を状態価値関数(状態)とAdvantage関数(行動)に分割することにより,行動にかかわらず状態を学習することができるようにしたものである。
noisy network(ノイジーネットワーク)
DQNでは常にその時点で価値の高い行動をとり続けた場合,別の行動をとる可能性がなくなってしまう.この問題点をネットワークそのものに学習可能なパラメータと共に外乱を与え,それも含めて学習させていくことでより長期的で広範囲に探索をすすめることで改善するという方法。
noisy networkはネットワークそのものに学習可能なパラメータと共に外乱を与え,それも含めて学習させていく手法。
マルチエージェント学習
マルチエージェント機械学習は複数の強化学習エージェントが同時に学習をして行動し、相互に影響を与える。
状態表現学習
深層強化学習において環境の状態をあらかじめ学習しておき、学習効率を高める手法
SAC(Soft Actor-Critic)
連続値制御の深層強化学習モデル。方策関数(Actor)とsoftQ関数を,ニューラルネットワークで実装する。
報酬成型(Reward Shaping)
通常の報酬値に,追加の値を加えることで学習速度を向上させることができる。
オフライン強化学習
強化学習をオフラインで過去に蓄積されたデータのみで学習を行う手法である.医療・ロボティクスなどの実環境との相互作用へのリスクの大きい分野で期待されている。
Sim2Real(Simulation-To-Real)
シミュレーションを用いて方策を学習し,その学習した方策を現実に転移させる手法。
ドメインランダマイゼーション(Domain Randomization)
ランダム化されたプロパティを使用して様々な学習用のシミュレーション環境を作成する手法。実データをほとんど必要としない。教師なし学習。
Deep Residual Learning, ResNet
2015年のILSVRCで優勝したモデルであり,152層ものニューラルネットワークで構成されている.残差ブロックを導入することで勾配消失問題に対処し,飛躍的に層を増やすことに成功。
剪定
決定木において過学習を防ぐために枝数を制限する手法
プルーニング(Pruning)
ニューラルネットワークの重みの一部を取り除く(値を0にする)ことでパラメータ数や計算量を削減するNeural Network Pruningと呼ばれる手法が提案されている
営業秘密 有用性、秘密管理性、及び、非公知性等
活性化関数の初期値
シグモイド関数 Xavierの初期値
ReLU Heの初期値
東京大学の松尾豊准教授による4つのレベルのAI
レベル1 単純な制御プログラム
レベル2 古典的人工知能。推論・探索を行っていたり、知識ベースを入れていたりすることによる。
レベル3 機械学習を取り入れた人工知能
レベル4 特徴表現学習と呼ばれ、特徴量自体を学習する
松尾豊准教授が提唱しているAIの定義
人工的に作られた人間のような知能,ないしはそれを作る技術
スタンフォード大学のアーサー・サミュエルの機械学習の定義
明示的にプログラミングをしなくても学習する能力を,コンピュータに与える研究分野
知能の全体像、3つの階層
1. パターン処理
2. 記号の処理
3. 他者とのインタラクション
シンギュラリティ レイ・カーツワイル提唱。2045年には人工知能が自らの能力を上回る人工知能を自ら生み出せるようになり、無限に知能の高い存在を作る
音声を入力とし、単語列を出力するモデル
プロセス1 雑音・残響抑圧(in 音声 out 音声)
音声を認識したい対象以外の雑音を分離する
プロセス2 音素状態認識(in 音声 out 音素)
音声の周波数スペクトル、すなわち音響特徴量をインプットとして、音素状態のカテゴリに分類
プロセス3 音素モデル(in 音素 out 文字列)
音素がどの文字であるかを推定する
プロセス4 単語辞書(in 文字列 out 単語)
認識した文字列から単語を特定し認識する
プロセス5 言語モデル(in 単語 out 単語列)
単語系列仮説の尤度を評価する
End-to-End音声認識 プロセス1〜5をまとめて in 音声 out 単語列とする学習手法のこと
HMM(HIdden Markov Model, 隠れマルコフモデル)
従来、音声合成、あるいは音声認識の分野で使われてきた統計的手法
CNTK Microsoft が提供するディープラーニングフレームワーク
照応解析 文章内に存在する代名詞などが何を指し示しているのかを突き止めさせる解析
常識推論タスク 南カリフォルニア大学の Andrew Gordon の研究グループが提案したCOPA(Choice of Plausible Alternatives)が有名
CNTK 2016年 Google が発表した機械翻訳モデル
AIが製作したものの知財制度
日本では(2018年時点において)、AIが生成した創作物はそれを生み出す過程において人間による創作的寄与がある場合において著作物性が認められる
2018年時点、著作権法47条の7では、インターネット上のデータ等の著作物から学習用データを解析することは営利目的の場合まで含む著作権侵害には当たらない
諸外国においてもAI性生物の知財制度上の取扱は基本的には日本とスタンス同様
英国の著作権法では、コンピュータ創作物について著作権による保護が認められている
AAAI 米国人工知能学会。2008年にPresidential Panel on Long-Term AI Futures: 2008-2009
OpenAI イーロン・マスクが2015年に非営利団体として設立。
Partnership on AI(Partnership on Artificial Intelligence to Benefit People and Society)
人工知能(AI)普及を目指す非営利団体。2016年9月にFacebook, Google, DeepMind, Microsoft, Amazon, IBM の6社で創立。2017年にAppleも参加。
Microsoft社のAI開発原則
1. 人間の「拡張するもの」
2. 透明性の確保
3. 多様性の確保
4. プライバシーの保護
5. 説明責任の義務
6. 偏見の排除
SVM
スラック変数 グループ分けの際に誤った分類をどれだけ許容するかのパラメータ
ハイパーパラメータを求める方法
グリッドサーチ 全通り総当たり
ランダムサーチ ランダムにパラメータを組み合わせる
AIC 説明変数として利用する変数ができるだけ少なくするようなモデルを高くする評価指標
MOOCs(Massive Online Open Courses) インターネットを通じて無料で世界各国の有名大学の授業を受けることができる学習環境のことです。
米国ネバダ州では自動運転の走行や運転免許が許可制にて認められた
新産業構造ビジョン IoT、ビッグデータ、人工知能(AI)、ロボットに代表される第4次産業革命へ的確に対応するための官民の羅針盤とすべく、経済産業省が2017年5月に取りまとめた日本の戦略。「2030年に向けて、どのような社会を目指すのか」を提案。
諸外国の経済成長戦略
英国 RAS2020
ドイツ デジタル戦略2025(2016), Industries 4.0(2011)
中国 インターネットプラスAI3年行動実施法案
タイ Thailand4.0(2016)
インドネシア Making Indonesia 4.0(2019)
マレーシア Indestry4WRD(2018)
ノーフリーランチ定理 あらゆる問題を効率よく解ける様な”万能”の「教師あり学習」や「探索/最適化のアルゴリズム」など存在しない
ブートストラップサンプリング ランダムフォレストの様にランダムに一部のデータを取り出して学習に用いること
自動運転のレベル分け
レベル1 運転支援
レベル2 特定条件下での自動運転
レベル3 条件付き自動運転。システムが全ての運転タスクを実施するが、システムの介入要求に対してドライバーが適切に対応することが必要
レベル4 特定条件下における完全自動運転。特定条件下においてシステムが全ての運転タスクを実施
レベル5 完全自動運転
日本では官民 ITS 構想・ロードマップ 2017」の中で、
2020年までに自家用車はレベル2相当の「部分て駅運転自動化」を実現し、2020年代前半には高速道路におけるレベル3相当を実現するとしている。
さらに、2025年前後には高速道路において自家用車でレベル4の達成を目標に掲げる。
道路運送車両法の改正(2019年5月) 「自動運行装置」を定義し保安基準(装置が満たすべき技術基準)の対象とした。まとめ
arXiv(アーカイブ) 研究論文の電子ファイルを受け付けているリポジトリ。物理学、数学、コンピューターサイエンス、量的生物学、計量ファイナンス、統計学、電子工学、システム科学、経済学などの分野。
単位
ヨタ 10の24乗
ゼタ 10の21乗
エクサ 10の18乗
モラベックのパラドックス 伝統的な前提に反して「高度な推論よりも感覚運動スキルの方が多くの計算資源を要する」というもの。
要は、人間にとって簡単なことほど機械がやるのは難しいということ。
LOD(Linked Open Data)
ウェブ上に存在する他のデータと「リンク」されているデータ(リンクトデータ、Linked Data)であることと、誰でも自由に利用できるように「オープン」なライセンスで公開されたデータ(オープンデータ)であることを兼ね備えたデータ。ウェブ上でコンピュータ処理に適したデータを公開・共有するための方法。
Define-and-run と Define-by-run
Define-and-run
TensorFlowなど。日本語で訳すと「定義して実行する」。まず予め静的なネットワーク(計算グラフ)を記述した後、実際にデータを用いて実行する形式です。
Define-by-run
PyTorchなど。「実行ごとに定義する」。実行を行いながら動的にネットワークの構築を行っていくものです。
DeepFace 2014年にFacebookが公表したディープラーニングを用いた顔認識システム。
Security by Design(セキュリティ・バイ・デザイン) 内閣サイバーセキュリティセンター(NISC)により「情報セキュリティを企画・設計段階から確保するための方策」として定義されている。
Privacy by Design(プライバシー・バイ・デザイン)
1990年代にカナダのオンタリオ州 情報・プライバシー・コミッショナーであるアン・カブキアン博士が提唱した概念で、「技術」、「ビジネス・プラクティス」、「物理設計」のデザイン(設計)仕様段階からあらかじめプライバシー保護の取り組みを検討し、実践すること。
OpenPose カーネギーメロン大学の研究チームが2017年に公表した、深層学習を用いて人物の姿勢を推定するアルゴリズム。
OpenCV Intelが開発・公開した画像認識ライブラリであり、2006年に1.0がリリースされ、2015年には3.0がリリースされている。
ELIZA(イライザ) 簡単なルールベースの対話型プログラムであり、人工無能とも言われた最初期のチャットボット。
GPGPU(General-purpose computing on graphics units) GPUによる汎用計算
隠れマルコフモデル 確率モデルのひとつであり、観測されない(隠れた)状態をもつマルコフ過程である。音声データ等の時系列データのモデルとしてよく利用される。
混合正規分布モデルに基づく隠れマルコフモデルとして、GMM-HMMがある
AlphaFold DeepMind社が開発した、AIを使ってタンパク質の構造を見出し新薬開発に活かすモデル。CASP13, CASP14コンテストで優勝。
AI特許出願件数 2018年時点で 中国 > 米国 > 日本
ボルツマンマシン 1985年ジェフリー・ヒントンらによって提案される。確立的に動作するニューラルネットワークの一種。
RNNにおける教師強制(Teacher forcing)
訓練の際に”1時刻前”の正解データを現時点の入力として用いる手法を指す。とくに自然言語の領域では、教師強制は”翻訳”のモデルなどに適用される。
アフィン変換 画像の拡大縮小、回転、平行移動などを行列を使って座標を変換する。
AI戦略2019
内閣府が2019年に公表。
・「⼈間尊重」、「多様性」 、「持続可能」の3つの理念を掲げている。
・2025年には、エキスパート人材を年に2,000人育成する目標を掲げている。
・高校過程で2022年から「情報Ⅰ」を必修とすることを掲げている。
AI関連の主要国際会議
・ICML NeurIPSと並んで機械学習の世界トップの国際会議会議です。
・NeuralIPS ICMLと並び機械学習では世界最高峰の国際会議。ニューラルネットワーク技術を主にテーマとしているが、機械学習関連も多数。
・ICJI 記号推論のでの伝統的なテーマを含む人工知能技術全般をテーマとしている学会
・CVPR 画像認識を主にテーマとしている学会
より詳細はこちら
トロリー問題(トロッコ問題)
「ある人を助けるために他の人を犠牲にするのは許されるか?」という形で功利主義と義務論の対立を扱った倫理学上の問題・課題。自動運転などのAIに関する倫理観の議論となる問題の1つ。
Fashion-MNIST 10種類に分類できる衣類品画像のデータセット
PyCharm JetBrainsによるPython IDE(統合開発環境)
Adversarial Example(敵対的サンプル)
入力データに微小な摂動(ノイズ)を加え学習済みのDNNに誤った予測をさせるもののこと。人間が目にみてもわからなぐらいのノイズを画像に混入させAIに判断を誤らせるなど
画像キャプション生成
CNN + RNN。元ネタこちら
・学習済みCNNで画像の特徴量を抽出する。
・LSTMで文章の特徴量を抽出する。
・CNNとLSTMの特徴量を結合する。
・Softmax関数で次に来る単語を予測する。

オントロジー 哲学用語では「存在論」。情報科学の分野では「概念化の明示的な仕様」
透明性レポート
利用者のデータがどのように収集され、どのように活用されているのかを示したのが透明性レポートです。 特に、企業がどの程度政府等への情報を提供しているのかが示されているもののことを指します。
PDS(Personal Data Store)
個人情報やライフログを個人自身が蓄積・管理して、企業に販売したり、情報銀行に委託したりする仕組み。パーソナルデータストア。パーソナルデータサービス。
A3C(Asynchronous Advantage Actor-Critic)
2016年に発表された強化学習アルゴリズム。A3CはこれらのDQNの発展と、並列化の流れが合体したような手法で、DQNの次の世代的存在。
赤池情報量規準(An Information Critetion, AIC) 統計モデルの良さを評価するための指標である。単にAICとも呼ばれる。
アクタークリティック(actor-critic)
強化学習のフレームワークの一つ。acotr(行動器)が行動を選択し、critic(評価器)がactorを評価(TD誤差のの計算)する。 はDQNはactor-critic を応用したアルゴリズム。
ELSI(エルシー) 新規に開発された技術の「倫理的・法的・社会的な課題」
E ・・・Ethical(倫理的)
L・・・Legal(法的)
S・・・Social(社会的)
I・・・Issues(問題)
KLダイバージェンス 2つの確率分布がどの程度にているかを表す尺度。非負。
価値反復法 強化学習アルゴリズムの1つ。行動価値と状態価値の2種類の価値を定義しTD誤差が可能な限り小さくなるまで学習を行う。
R-CNN(Regions with Convolutional Neural Networks)
画像内のオブジェクト検出と分類するプロセス。物体検出と畳み込みニューラルネットワークの特徴と組み合わせる。
Leaky ReLU ReLUの拡張版です。 関数への入力値が0より下の場合には出力値が入力値をα倍した値(※αの値は基本的に0.01)、入力値が0以上の場合には出力値が入力値と同じ値となる関数です。
割引率(時間割引率)
強化学習において報酬に掛け合わせて、未来に行くほど報酬が小さくなるようにする値。
具体例として、ゲームなどでは短い手で勝利できる方が1手に「価値」があると考えられ歌め、同じ報酬でも時間が経過するごとに最大値が減っていくように割引率がかけられる。
MAML
メタ学習のアルゴリズムの1つ。
回帰、分類、強化学習等のタスクに適用可能である。
最適化処理において、勾配の勾配を求める。
更新後の目的関数の値の和が小さくなるように初期パラメータを決定する。
AIの社会実装を進めていくにあたって想定されるリスクとして、「AI自身のリスク」、「人間がAIを利用して引き起こすリスク」、「既存の社会秩序への負の影響」、「法律・社会の在り方のリスク」が議論されている。
この記事が気に入ったらサポートをしてみませんか?