
データを伝える技術 第1回 データを読む

執筆:荻原和樹
データをわかりやすく・印象的に可視化するためには、まずデータを読みこんで「腹落ち」するまで理解することが不可欠です。データの意味や構造によって最適な切り口や表現方法は異なりますが、データの名前やタイトルだけを見て分析や可視化に踏み込むのは、たとえるなら記事の見出しだけを読んでシェアしたりコメントするようなものです。特に官公庁の公表するような規模の大きいデータは、複雑な定義や集計方法をとっていることも少なくありません。
今回は、データの内容が比較的想像しやすく、国・地域別や時系列での分析が可能な「観光」に関するデータを実例として、私がふだん気をつけている読み方を紹介します。観光に関する統計はいくつか存在しますが、ここでは最もオーソドックスなもののひとつであるJNTO(日本政府観光局)の発表する「訪日外客統計」を取り上げます。可能な方はリンクから実際のデータを見ながら読むと、よりわかりやすいと思います。

データの定義を確認する
まずはデータの定義を確認します。データは何を集計していて、何がデータに含まれ、何が含まれないのかをクリアにします。そもそも「訪日外客」とは何でしょうか? すぐに思い浮かぶのは、アメリカや中国などから観光目的で日本を訪れる外国人旅行客でしょう。JNTOによる「統計に関するよくあるご質問(FAQ)」のページにも、「日本を訪れた外国人旅行者の数です」と明記されています。
ただ、それだけを頼りにデータを見ると、データの定義を見誤る可能性があります。もう少し詳しく定義を確認します。まず、説明には「旅行者」とありますが、ビジネス目的は含まれるのか? 「外国人」の定義は何か? 国籍か、居住地か? たとえば「イギリスに留学中の日本人学生」や「日本の永住権を持つフランス出身者」は含まれるか? 飛行機のパイロットや貨物船の乗組員は含まれるか? アメリカから日本を経由して、飛行機のトランジット時間の関係で1日だけ空いた時間を空港の外で過ごし、それから香港や北京に向かう人は含まれるか?
データの範囲に該当するかどうかが微妙なこれらのケースは、ITソフトウェア開発の分野ではエッジ・ケースと呼ばれます。重箱の隅をつつくような検討ですが、ここでデータの範囲や定義をきちんと理解しておかないと、その後の可視化や分析が抽象的で的の外れたものになりかねません。
では実際の定義はどうか。先ほどのFAQページに詳しい定義が書いてあるので引用します。
②訪日外客数の定義
国籍に基づく法務省集計による外国人正規入国者から、日本を主たる居住国とする永住者等の外国人を除き、これに外国人一時上陸客等を加えた入国外国人旅行者のことです。駐在員やその家族、留学生等の入国者・再入国者は訪日外客数に含まれます。乗員上陸数(航空機・船舶の乗務員)は訪日外客数に含まれません。
この定義から先ほどの答え合わせをすると、留学中の日本人学生は国籍が日本であるため訪日外客には含まれません。また、日本の永住権を持つ海外出身者も「日本を主たる居住国とする永住者等の外国人を除き」とあるので含まれません。飛行機のパイロットや貨物船の乗組員もここには含まれません。アメリカから日本を経由して、さらに第三国に出る人は、入国した時点でデータに含まれます。
これらの極端なケースは大勢には影響しないでしょうが、データ可視化の作り方によってはユーザーに混乱を与える可能性があります。たとえば日本と韓国など、(コロナ前の数字ですが)年間何百万人も行き来する国同士では少しの定義の違いは問題にならないでしょう。一方、小さな国で観光客数が数人しかいない場合、その1人が純粋な観光客なのか、それとも閣僚と会談に来た政府関係者の家族なのかによって受け取り方が違ってきます。
余談ですが「世界最小の共和国」として知られるナウル共和国では、コロナ前の2019年度に日本から訪れた観光客は3人だったそうです。
【速報】
— ナウル共和国政府観光局(公式) (@nauru_japan) July 7, 2021
コロナ禍の影響で、ナウル共和国への2020年度の日本人観光客は0人と判明。前年度比3人減となった。
データを概略だけでなく細かな分類・時系列で体験できるのはデータ可視化の大きな価値ですが、その反面、私たちが作るデータ可視化がわかりやすいほど、数字の矛盾や偏りにユーザーが気付きやすいものです。
集計方法と調査範囲
また、データの数え方や集計方法も必ず確認しておくべきポイントです。「訪日外客数」では以下のように表記されています。
③訪日外客数の数え方
入国手続きを受ける毎に1人と数えます。(例: 同一人物が1月と9月に入国した場合には、2人とカウントされます。)
これを読むと、厳密には同一人物であっても重複してカウントされる場合があるようです。このような場合、実際にどの程度重複が含まれるのか、データの内容や集計方法から予想します。
今回の場合、日本への入国手続きは、それほど実態と乖離するような極端なケースはなさそうです。年に何度も海外と日本と往復する人はそれほど多くないでしょうし、統計によってはごく一部の人が極めて大きな数値を記録することもありますが(たとえば保有資産など)、それも物理的な手間と時間から考えにくいでしょう。
もしこれが無視できないくらいに重複が大きい場合、表現方法や数え方に注意する必要があります。たとえば訪日外客と同じく「人の移動」を表すデータに、JRなどが発表する駅ごとの平均利用者数があります。週や年単位で集計した場合、同じ人が通勤や通学で何度も使うことが容易に考えられるため、同じ人数でも「延べ」と表現されます。

分析においても、たとえば新宿駅のような通勤・通学利用が多い駅と、箱根湯本駅のように観光利用が多いと考えられる駅を同列に扱うことはあまりないはずです。
こうした重複は統計データの性質上、必ず発生しうるものです。もし重複の程度が具体的にわかるのであればそれに越したことはありませんが、データからは把握できない場合、定義や集計方法から推測し、可能な限り誤解を与えないように表現方法に配慮する必要があります。
もうひとつ注意する点は、そのデータが扱う対象をすべて網羅しているかどうかです。公的な統計の中には、対象となる人やモノをすべて調査するケースがある(統計学で「全数調査」と呼ばれます)一方で、調査に応じた人やランダムにピックアップしたモノだけを調べることもあります(同様に、こちらは統計学で「標本調査」と呼ばれます)。
訪日外客数は、上の定義を見る限り全数調査ですが、もしこれが標本調査である場合、全体の件数をもって「昨年日本を訪れた外国人は◯◯人だった」といった表現はできません。このような統計と実態との差を「暗数」と呼びます。
たとえば新型コロナやインフルエンザなどの感染は、検査などを伴う診断が基準となっているため、新型コロナで広まった「無症状感染」はほとんどの場合、統計に含まれません。また、犯罪統計においても、特に性犯罪被害に関する暗数は大きな課題となっており、法務省は「犯罪被害実態(暗数)調査」などの調査を行っています。
標本調査である場合に気を付けるもうひとつの点は、全体(統計学で「母集団」といいます)からの偏りです。たとえば、特に点数の調整などを行わずに支持政党に関する調査をした場合、調査を行うウェブサイトやメディアによって大なり小なり結果は異なるでしょう。長くなるので詳細は省きますが、新聞やテレビ各社の世論調査や内閣支持率調査などは、このような偏りがないようにさまざまな工夫を凝らして調査や集計を行なっています。
多くの場合、公開されているデータからデータそのものの偏りを類推することは困難ですが、そのような場合にも、調査や集計方法から推測してユーザーに注意喚起をすることが重要です。

不完全なデータをどう扱うか
今回の統計にはありませんが、データの欠測や異常値、あるいは基準変更にも注意が必要です。欠測とは、何らかの原因でデータの収集や集計がうまくいかず、その時点だけデータが存在しないことを指します。異常値も同様に、何らかの原因で数値が通常考えられないような値になっていることを示すものです。特にセンサーによる定点観測を使う統計データでしばしば見かけます。また、統計データの時系列が長くなるほど、途中で基準の変更を行い、それまでの推移と連続性が保てなくなる場合があります。
欠測や異常値のわかりやすい例が気象庁です。気象庁では全国各地の気温や風速などを1時間ごとに計測していますが、観測ができなかったりした場合の記号表現が細かく決められています。

気象庁は150年近く前から観測データを公開しており、欠測や異常値のルールも細かく明確に分けられていますが、多くの場合では注記で「ただし2021年12月分のデータはXXXのため参考値」などとだけ記載されていることがほとんどです。
もしこうした欠測や基準変更などが発生した場合、重要度に応じて対応を考えます。私はざっくりと4段階に分けることが多いです。
・レベル1……何も対応しない:データの読み取りにほぼ影響しないケース。
・レベル2……注記に載せる:概要を読み取る分には基本的に問題ないが、データを再利用したり分析したりするユーザー向けに注記を記載しておくケース。
・レベル3……視覚表現を変える:データ全体の傾向や概要に影響を与えるケース。データを流し読みする一般のユーザーにも知ってほしいので、視覚表現を通常時と変えることで気づいてもらう。
・レベル4……当該データを掲載しない:明らかな異常値であったり、もともと表現したかったデータからかけ離れた集計基準になったことで、そもそもデータを載せること自体に問題があるケース。視覚表現での対応にも限界があるため、データの更新を止めたり、該当の箇所だけ非表示とする。
「実際の数値にどれだけブレが生じるか」「データの意味内容がどれだけ変わるか」の2点を主に勘案して場合分けを行います。とはいえレベル4は滅多に起こりませんし、レベル1もあまり悩むことはないでしょう。現実的に問題となるのは「この問題はレベル2と3のどちらに分類するか?」だと思います。
結論から述べると、「可能な限りレベル3として扱った方がよい」というのが私の意見です。というのも、現実問題としてデータ可視化の注記はほとんど読まれません。社内で限られたユーザーが見るものであれば口頭などで説明を補うこともできますが、報道など社会に開かれたデータ可視化の場合、注記を割愛した状態でスクリーンショットを撮られ、拡散されてしまうことも珍しくありません。最悪の場合は「◯◯社は間違った情報を流している」という不公平な批判だけがシェアされることもあります。
こうした事態を未然に防ぐため、視覚表現で対応できるものは可能な限り対応しておくのがよいと私は考えています。具体的には折れ線グラフを破線にする、「!」など記号を含んだフキダシを添えておき、フキダシを選択すると詳しい解説が出てくる、などです。たとえば以下の例では棒グラフの色を変えることで基準が変わったことを表現しています(注記にもその旨を記載しています)。

こうしたデータの例外対応は最初にデータ可視化の諸々を設計する時点でわかっていればよいのですが、継続的に更新されるデータにおいては、突然「今回のデータから集計基準を変えた」と発表されるケースも珍しくありません。というより私の経験上、特に行政機関が発表する公的統計は事前に基準変更が示されるケースの方が稀です。
特に怖いのは、数値上では何も変化がなく、注記などにさらっと変更した旨が書かれているパターンです。あなたがデータをプログラムで自動的に取得している場合、数値部分だけでなくヘッダー(Excelなど表形式のファイルでいう1行目や見出し)部分や注記部分も取得して、前回の取得時から変わっていないかどうか確かめることを勧めています。
更新タイミングと随時訂正
続いて、データの更新タイミングや修正予定を確認します。訪日外客統計では「推計値」「暫定値」「確定値」という3種類の値が存在するようです。
④訪日外客数における推計値、暫定値、確定値の違い
推計値は、当該月の翌月にJNTOが発表する概算値で、100の位まで算出しています。暫定値は、推計値発表の2ヶ月後に発表する確定に近い数値で、1の位まで算出しています。また、観光、商用、その他といった目的別の数値も明らかになります。確定値は、該当年の翌年6月以降に、法務省の年計確定をもってJNTOが算出する最終値で、暫定値と同様に1の位まで算出します。
これを読む限りでは、ざっくりでもよいので早く概要を知りたい場合は推計値を使い、きちんと確定した値を知りたい場合は確定値を使うのがよさそうです。ただし暫定値も確定値と同じ目的別の数値まで網羅しており、発表も3ヶ月後と確定値よりもはるかに早い(確定値は6〜18ヶ月後)ため、実務的には暫定値を使うことが多くなりそうです。
ここで重要になるのが、推計値や暫定値の精度です。一口に推計といっても、その精度は統計によってまったく異なります。今回は同じ期間・同じ対象の確定値に対応する推計値や暫定値が確認できるため、新型コロナ禍前の2019年における訪日外客数の推計値・暫定値・確定値を比べてみます。

これを見ると、暫定値と確定値は1の位に至るまでまったく同じ、推計値も有効桁数として設定されている100の位までは(四捨五入して)ほぼ同じであることがわかります。この統計に関しては、たとえ推計値と確定値が一緒に使われていたとしても、前述の「レベル2」=視覚的な表現は特に変えず注記に書いておくくらいの対応で問題なさそうです。
なお、もしこの差が無視できないくらい大きい場合、予想される差異の大きさによって「視覚表現でわかるようにする(たとえば棒グラフであれば棒の色を変える)」「そもそも推計値は掲載しない」といったレベル別の対応を行います。ケースバイケースなので一概には言えませんが、私の場合は「このデータはむしろ掲載する方が誤解を招く」と判断された場合には掲載自体しないこともあります。
これとあわせて確認するのが、データの随時訂正がないかどうかです。通常、統計は対象となるデータがすべて集まってから集計や公開が行われますが、日次統計など公開ペースが早いデータでは、最初の発表から時間が経っても判明し次第随時データを追加していくケースがあります。
最近の事例でいうと、首相官邸が公開する新型コロナのワクチン接種数が該当します。ワクチンの接種情報は日次で更新され、ある日の接種回数が翌日には明らかになりますが、日を追うごとに後から報告された分が積み上がっていきます。

たとえば1・2回目のワクチン接種が進んでいた2021年9月13日における一般(医療従事者、高齢者、職域を除く接種)の1・2回目接種回数は、翌日の発表では572,799回でした。そこから翌々日、さらにその翌日と、徐々に数字が積み上がっていき、2021年12月21日の発表では、9月13日の接種回数は1,016,187回と2倍近くになっています。
このようなデータを扱う場合、2つのことに気をつけます。
1つ目は純粋なデータと増加分の違い。たとえば「12月13日に接種XXX回」と発表されたとき、それが「12月13日に接種があった回数」なのか、それとも「過去分の増加を含めた数字なのか」を確認する必要があります。
ワクチン接種の場合、トップページに表示されている数字は累計の接種回数と「増加回数」です。増加回数とは紛らわしい表現ですが、前日に接種が行われた回数ではなく、前日と最新の累計接種回数を比べた差分です。したがって、過去分の遅れた報告分や、場合によっては数値の訂正による増減が含まれています。
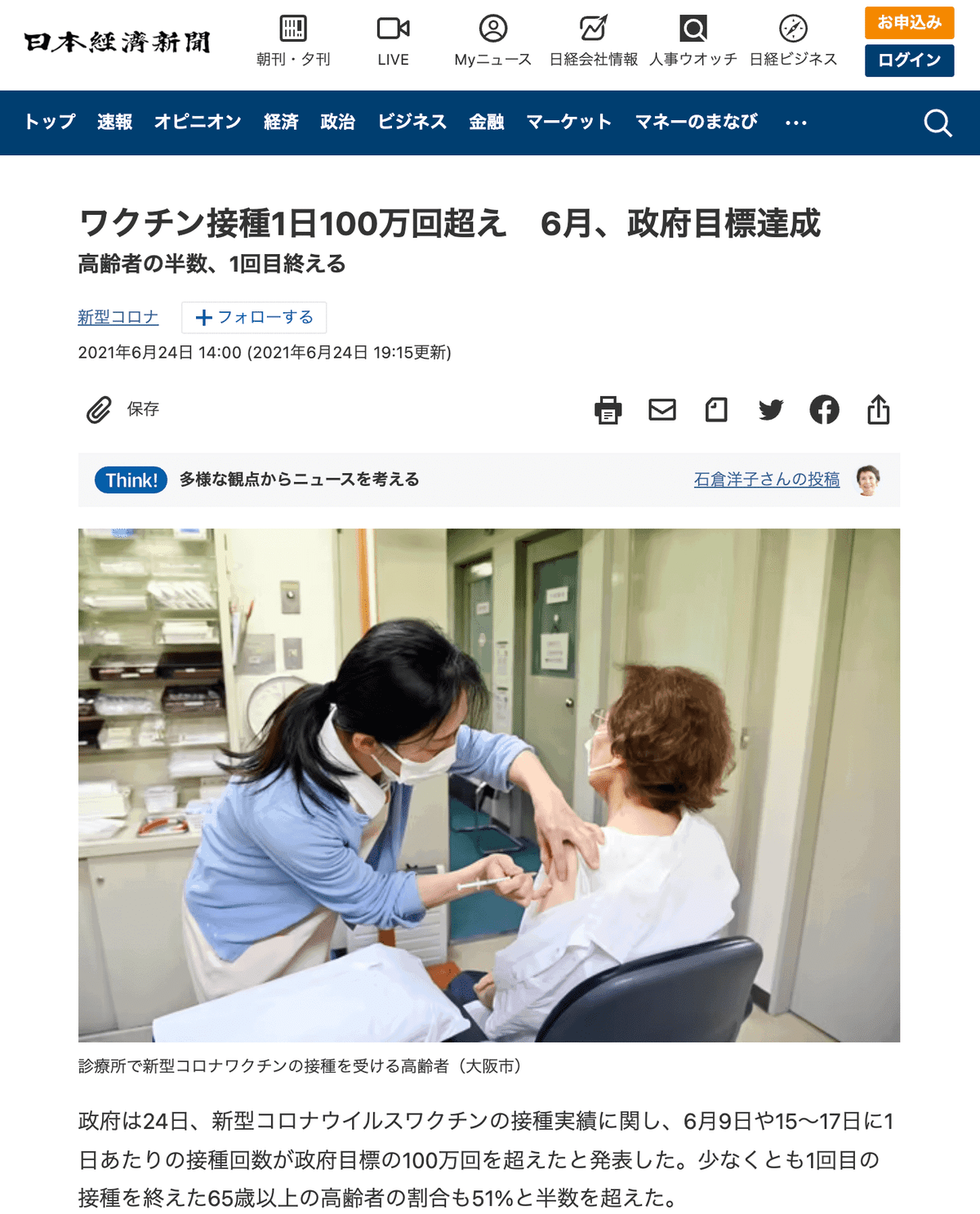
増加回数をめぐっては、かねてから菅義偉首相(当時)が「1日100万回接種を目標とする」と明言していたためか、一部報道で混乱が起こりました。たとえば産経新聞は6月8日に『ワクチン接種、発表ベースで「1日100万回」達成』とする速報を公開しています。しかしここでの「100万回」は増加回数であり、過去分の積み上げが含まれます。素直に考えれば1日100万回と言われて過去の訂正を含むと解釈する人は極めて少ないでしょう。
なおその後、首相官邸は6月24日の発表において、6月9日や15〜17日に100万回を達成していたことを報告しています。
2つ目に気を付けるのは、日付の種類です。1つ目と似ていますが、同じ時系列のデータであっても、「接種日」ベースなのか「公表日」ベースなのかで過去分の扱いなどが変わってきます。たとえば1ヶ月前に計上したデータに誤りが判明した場合、前者であれば1ヶ月前の日付を変更できますが、後者の場合は判明した日の増減として計上されます。この結果、実際の変動とは関係ないタイミングで数値が変わることがあります。多くの場合、過去分の訂正はまとめて行われるものですから、特定の日に妙に大きな数字が計上されたりします。
新型コロナの感染者データにおいても同様のことがありました。感染の初期(2020年前半)には、厚生労働省は時系列でのデータを公開しておらず、その時点での累計数字(累計の検査陽性者数やPCR検査人数など)を公開する形を取っていました。上の例でいう「公表日」ベースと同じですが、大きな訂正があるとその日の実検査人数を上回り、マイナスになってしまうことがしばしばありました。こうなってはデータから元の値を復元・推測するのは困難なので、泣く泣く注記をつけてデータを更新した記憶があります。
この場合も、可能であれば視覚的にわかるように色を変えたり吹き出し(アラート)をつけるとよいでしょう。注記に書くのもよいですが、「注記に書いたからよいでしょ」という姿勢は「PDFで数字を公開したからよいでしょ」という消極的なデータ公開と同じです。現実的に難しいことも多々ありますが、データを可視化する過程においては、理想的には訂正や基準変更などもすべて視覚表現に可視化すべきだと考えています。
ちなみにワクチン接種データには「接種日」「公表日」の他に、医療従事者への接種分のみ「集計日」という日付を使っています。実はワクチン接種に関するデータを格納するデータベースは2つあります。厚生労働省が所管するワクチン接種円滑化システム(V-SYS)と、政府CIOポータル(内閣官房)が所管するワクチン接種記録システム(VRS)です。医療従事者への接種は前者、それ以外は後者で管理されています。首相官邸が公開するワクチン接種情報は基本的にVRSがベースとなっていますが、医療従事者への接種分のみV-SYSから集計したデータを掲載しているため、このような込み入った表記になっています。
これらの確認によって、徐々に数字上のデータが具体的なイメージを伴うものになってきたはずです。ここまでの作業をざっくり説明するとき、私はいつも「データの『1』を理解する作業」と表現しています。そのデータの「1」にあたる単位が1人なのか1件なのか、重複がありうるのか、エッジ・ケースにあたる場合ではどうなるかを理解する作業という意味です。
裏を返せば、時間をかけて調べても「1」のイメージが湧かないデータは可視化を行ってもユーザーに響かない場合が多い。たとえば映画やイベントの「経済効果」をシンクタンクやコンサルティング会社が発表することがあります。経済効果を予測することはもちろん有益な試みなのでしょうが、多くの場合その詳細な計算過程が公開されることはありませんし、「経済効果」が具体的に何を含んでいるのかも発表を読んだだけではわからない場合があります。これをそのまま「◯◯イベントの経済効果は200億円」として可視化を行っても、満足な比較や意味づけができずに終わるのではないかと考えます。
データ可視化において避けたい事態は、可視化がユーザーに響かず「ふーん」で終わってしまうことです。その大きな原因は、数字が数字にしかならない、つまり私たちの目の前にある生活や実例に結びつかないためだと考えています。これを避けるために、まずデータを読み込んで作り手自身が腑に落ちるまでデータを理解することが必要です。
つづく