
SkyWayで録音した音声ファイルを合成してAWS post-call Analyticsで通話分析をする

SkyWayでは、2024年4月22日に録音・録画機能を提供開始しました。
https://support.skyway.ntt.com/hc/ja/articles/31515639103001-録音-録画機能を提供開始しました
本記事では、SkyWayで録音した音声ファイルを用いて、AWS post-call Analyticsで会話の品質を分析する方法をご紹介します。
AWS post-call Analyticsは、会話の品質を分析することができる機能で、以下のような指標を計測できます。
会話のスピード(捲し立てるように喋っていないか等)
会話のバランス(一方的に喋っていないか等)
声から読み取れる感情(聞き手がポジティブな感情になっているか等)
NGワードを使っていないか・キラーワードを使えているか(聞き手に刺さるような単語を支えているか等)
声の大きさが適切か
SkyWayで録音した音声ファイルをAWS post-call Analyticsで分析することで、会議や商談の品質を計測し、より良い会議や商談を行うためのきっかけにすることができるでしょう。
以前書いた記事では、リアルタイムに分析を行うのCall Analyticsを利用しており、こちらは英語のみの対応でしたが、通話後に分析を行うpost-call Analyticsでは、日本語にも対応しています。
SkyWayの録音方式
SkyWayの提供する録音・録画機能では、個々のPublicationごとに録音ファイルが作成されます。そのため、AWS Transcribeのように一つの音声を分析するような場合は、出力された録音ファイルのまま利用することができますが、AWS post-call Analyticsのように複数の音声を合わせて分析するようなサービスを利用する場合は、合成しなければ利用することができません。
SkyWayの録音・録画における合成機能は現在検討を進めています。ご意見・ご要望についてはSkyWay公式サイトよりお問い合わせください。
SkyWayの録音・録画機能の詳しい情報については以下を参照してください。
AWS post-call Analyticsの要件
AWS post-call Analyticsは、コールセンターのような1対1で通話しているような状況を前提として、サポートと顧客の二つの音声が一つの音声ファイルに合成されたものを分析する仕様になっています。
よって、サポートと顧客の音声を二つのチャネルに分け、2チャネルの音声ファイルとして合成する必要があります。
詳しくは、AWS post-call Analyticsのドキュメントを参照してください。
SkyWayで録音した音声ファイルを合成してAWS post-call Analyticsで分析する
録音ファイルをGCS/S3から入手する
まずは、SkyWayで録音ファイルを作成するために、以下のチュートリアルに従ってサンプルアプリを実装してください。クラウドストレージはGCSとS3が選択できます。
サンプルアプリをローカルで起動し、roomにjoinすると、以下のように1対1の通話が始まります。そして、 start recording ボタンを押すことで、録音・録画が開始され、停止ボタンを押すまで録音・録画が継続します。

停止ボタンを押してから、GCS/S3を確認すると、publisherごとにフォルダが作成されており、音声・映像ファイルが格納されます。
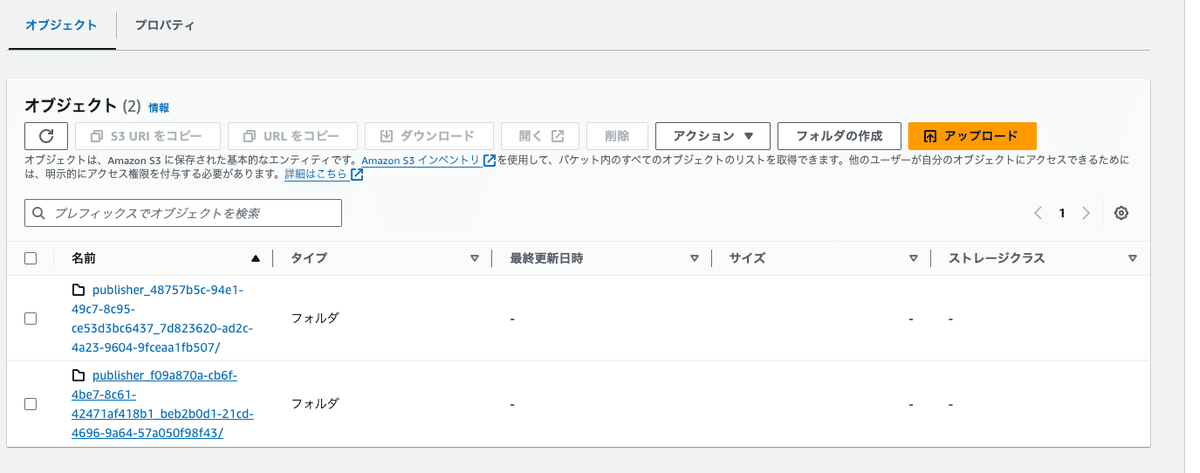
この音声ファイルをAWS CLIか、手動でDLします。
二つの音声ファイルを一つの音声ファイルに合成する
今回は、Pythonを用いて音声ファイルを合成します。
メディア処理をすることができるffmpeg-pythonをインストールしておきましょう。ffmpegは多くの主要なプログラミング言語から利用できますので、Python以外で合成を行いたい場合でも、似たように実装することができます。
SkyWayの録音ファイルはwebm形式であり、AWS post-call Analyticsはwebm形式に対応していますので、合成ファイルもwebm形式としています。
import ffmpeg
def mix_audio_with_delay(file1, file2, delay_ms, output_file):
# 各ファイルを読み込み
input1 = ffmpeg.input(file1)
input2 = ffmpeg.input(file2)
# 第二のファイルの開始をミリ秒単位で遅らせる
delayed = ffmpeg.filter(input2.audio, 'adelay', f'{delay_ms}|{delay_ms}')
# 2つの音声をマージ
mixed = ffmpeg.filter_([input1.audio, delayed], 'amix', inputs=2, duration='longest')
# ステレオチャンネルとして出力を設定
output = ffmpeg.output(mixed, output_file, acodec='libvorbis', ac=2)
output.run()
# audio2.webm を遅らせて、audio1.webmと合成
file1 = 'audio_5a6083e6-c763-4e00-93e3-c17656a55ca8_20240424_1548_16264599852.webm'
file2 = 'audio_17364e26-0e53-4d7e-a225-062aa847dc89_20240424_1548_16262105730.webm'
file1_start_timestamp = int(file1.split('_')[-1].split('.')[0])
file2_start_timestamp = int(file2.split('_')[-1].split('.')[0])
mix_audio_with_delay(file1, file2, 10000, 'delayed_stereo_output.webm')合成した音声ファイルをAWS post-call Analyticsにかける
合成した音声ファイルは、S3にバケットを作り、格納してください。
その後、AWS Consoleにログインし、その後 Amazon Transcribe > 通話後分析ページに移動して「ジョブを作成」します。
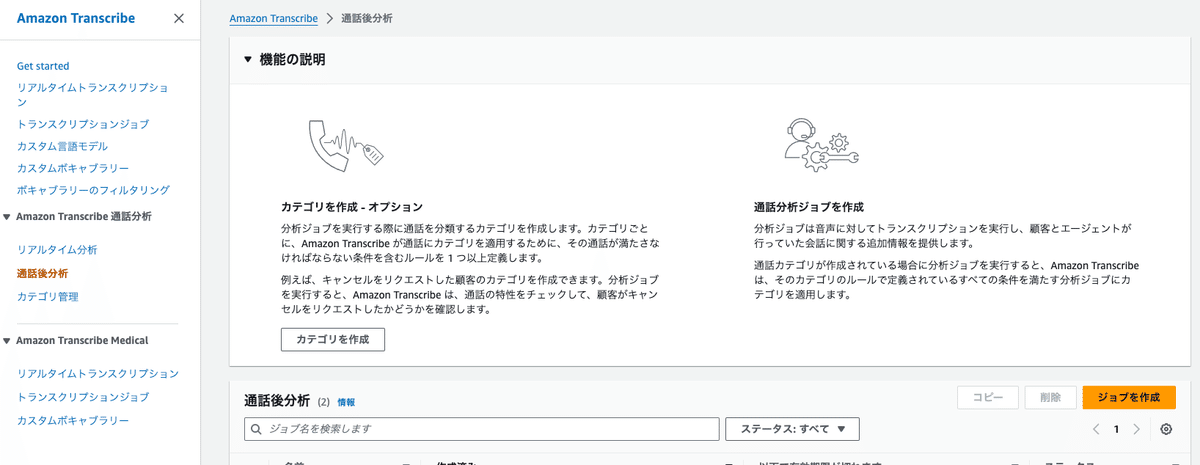
ジョブの設定では、言語の指定・音声ファイルの保存場所の指定をします。
ここで、先ほど合成した音声ファイルの、AGENT側の音声が0チャネルと1チャネルのどちらなのかを指定しなければいけないことに注意してください。
その後、ジョブを作成すると分析が開始します。
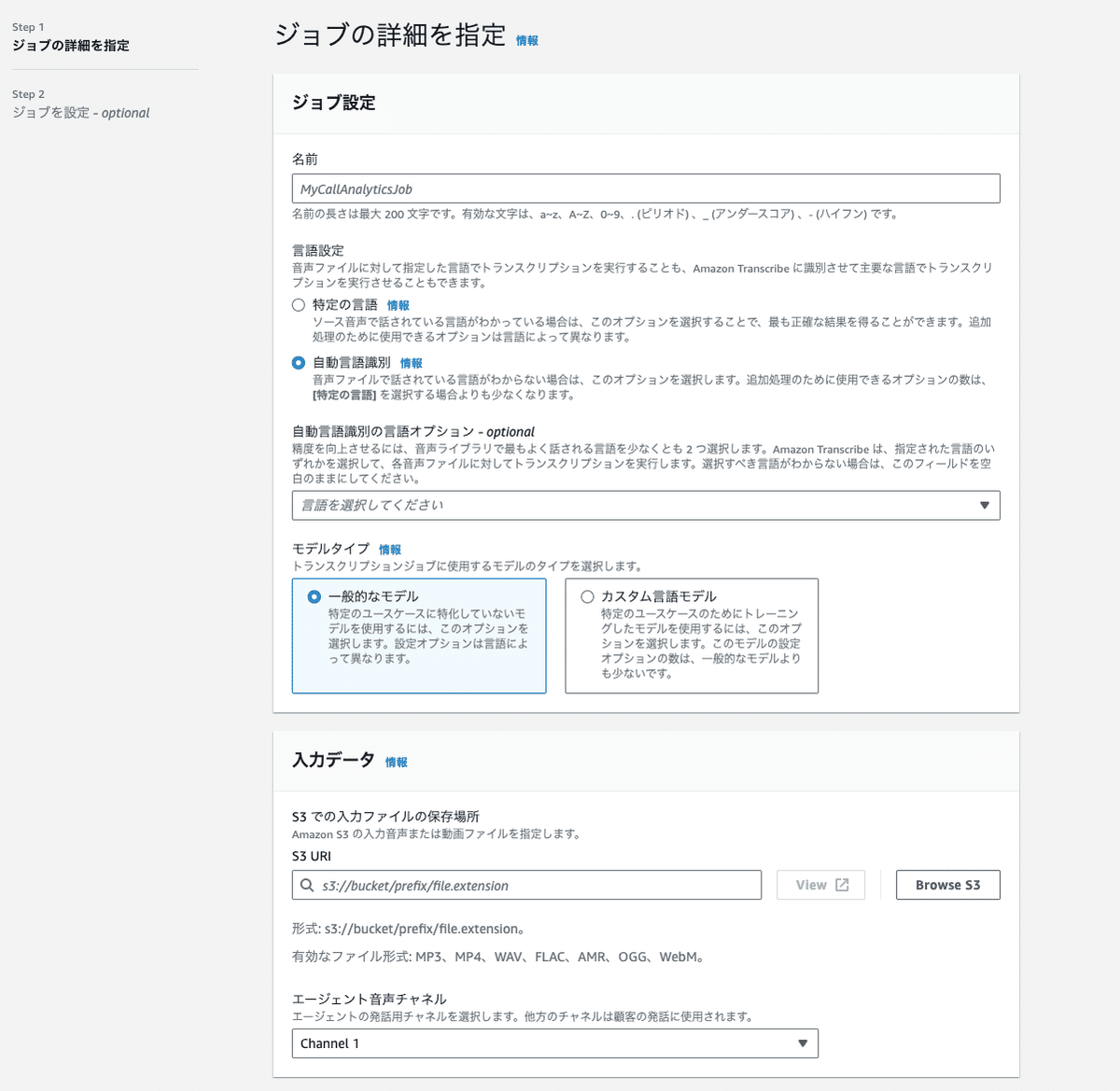
AWS post-call Analyticsは、SDKを使っての分析も可能なので、自動化したい場合はAWS SDKを利用してください。
トランスクリプトをダウンロードする
ジョブが完了するとステータスが完了となり、分析結果をダウンロードできるようになります。

トランスクリプトをダウンロード ボタンを押すと、分析結果と書き起こし結果が含まれたjsonファイルがダウンロードできます。
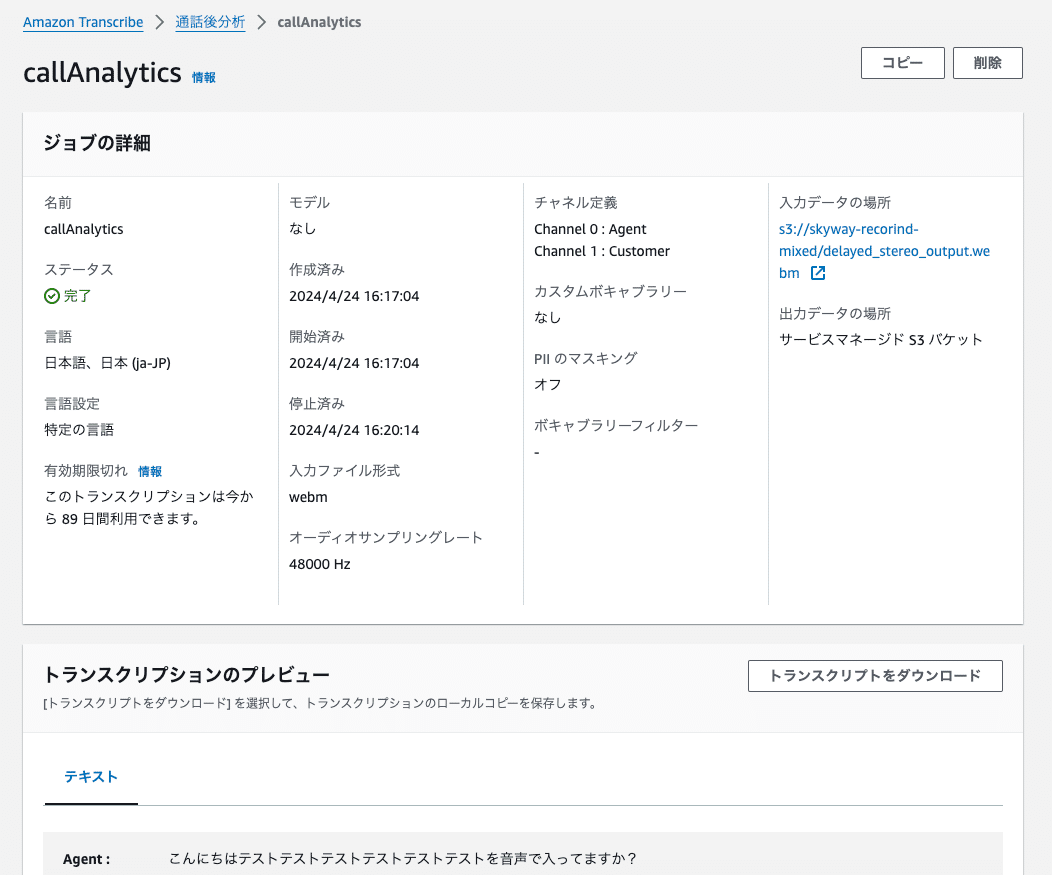
分析結果の内容は以下のようになっており、ある程度の単位で声の大きさが数値化されていたり、感情分析の結果が格納されていたります。
この結果を用いることで、会話の品質を評価することができるでしょう。
会話のスピード ⇒ TalkSpeed
会話のバランス ⇒ NonTalkTime
声から読み取れる感情 ⇒ Sentiment
NGワードを使っていないか・キラーワードを使えているか ⇒ Categories
声の大きさが適切か ⇒ LoudnessScores
{
"JobStatus": "COMPLETED",
"LanguageCode": "ja-JP",
"Transcript": [
{
"LoudnessScores": [82.13, 83.85],
"Content": "こんにちは",
"Id": "1d9f86e2-130e-40d0-a0c8-a7b2494e13ed",
"BeginOffsetMillis": 3735,
"EndOffsetMillis": 4345,
"Sentiment": "NEUTRAL",
"ParticipantRole": "AGENT"
},
.....
],
"AccountId": "181181909946",
"Categories": {"MatchedDetails": {}, "MatchedCategories": []},
"Channel": "VOICE",
"Participants": [
{"ParticipantRole": "AGENT"},
{"ParticipantRole": "CUSTOMER"}
],
"ConversationCharacteristics": {
"NonTalkTime": {
"Instances": [
{
"BeginOffsetMillis": 48985,
"DurationMillis": 3550,
"EndOffsetMillis": 52535
}
],
"TotalTimeMillis": 3550
},
"Interruptions": {
"TotalCount": 4,
"TotalTimeMillis": 131020,
"InterruptionsByInterrupter": {
"AGENT": [
{
"BeginOffsetMillis": 9665,
"DurationMillis": 14600,
"EndOffsetMillis": 24265
},
]
}
},
"TotalConversationDurationMillis": 155705,
"Sentiment": {
"OverallSentiment": {"AGENT": 0.3, "CUSTOMER": 0.3},
},
"TalkSpeed": {
"DetailsByParticipant": {
"AGENT": {"AverageWordsPerMinute": 144},
"CUSTOMER": {"AverageWordsPerMinute": 145}
}
}
まとめ
SkyWayの録音ファイルを合成してAWS post-call Analyticsにかけることで会議・商談の品質を可視化することが可能です。
SkyWayの録音・録画における合成機能は現在検討を進めています。ご意見・ご要望についてはSkyWay公式サイトよりお問い合わせください。
会話のスピード(捲し立てるように喋っていないか等)
会話のバランス(一方的に喋っていないか等)
声から読み取れる感情(聞き手がポジティブな感情になっているか等)
NGワードを使っていないか・キラーワードを使えているか(聞き手に刺さるような単語を支えているか等)
声の大きさが適切か
リアルタイムに分析を行う Call Analyticsは英語のみの対応でしたが、post-call Analyticsでは日本語にも対応しています。
この記事が気に入ったらサポートをしてみませんか?