
【Core ML】 モデルのIntegrationをシンプルにするMLTensor - "Deploy machine learning and AI models on-device with Core ML" を見たメモ①

WWDC24の "Deploy machine learning and AI models on-device with Core ML" (Core MLで機械学習とAIモデルをオンデバイスで展開する)セッションを見たメモ。
⚠️ 本記事の画像、引用部分は基本的に同セッションからの引用です
セッション概要
Learn new ways to optimize speed and memory performance when you convert and run machine learning and AI models through Core ML. We’ll cover new options for model representations, performance insights, execution, and model stitching which can be used together to create compelling and private on-device experiences.
(Core MLを通じて機械学習とAIモデルを変換して実行する際に、速度とメモリ性能を最適化する新しい方法を学びます。モデル表現、パフォーマンス・インサイト、実行、モデルのスティッチングの新しいオプションについて説明し、これらを組み合わせて使用することで、魅力的でプライベートなオンデバイス体験を実現します。)
セッションのアジェンダ
本セッションのアジェンダは以下の5つ:
Integration
モデルデプロイメントのワークフローにおけるCore MLの役割を確認する
MLTensor
モデル統合を簡素化する新しいタイプから、エキサイティングな機能を紹介
Models with state
状態を使ってモデルの推論効率を向上させる方法を探る
Multifunction models
効率的な配備のための多機能モデルを紹介
Performance tools
モデルのプロファイリングとデバッグに役立つCore MLパフォーマンス・ツールのアップデートをレビューします。

ちなみに最後の"Wrap-up"では以下の3つだけピックアップされてるので、このセッションで重要なのはこのへんなのだと思う:

本記事では "Integration" と "MLTensor" についてまとめる。
Models with stateについてはこちら:
Multifunction modelsについてはこちら:
"Performance tools" については以下3記事に書いた:
"Integration"
Integrationは「おさらい」といった感じなのであまり拾うところはなかったが、面白い話もあった:
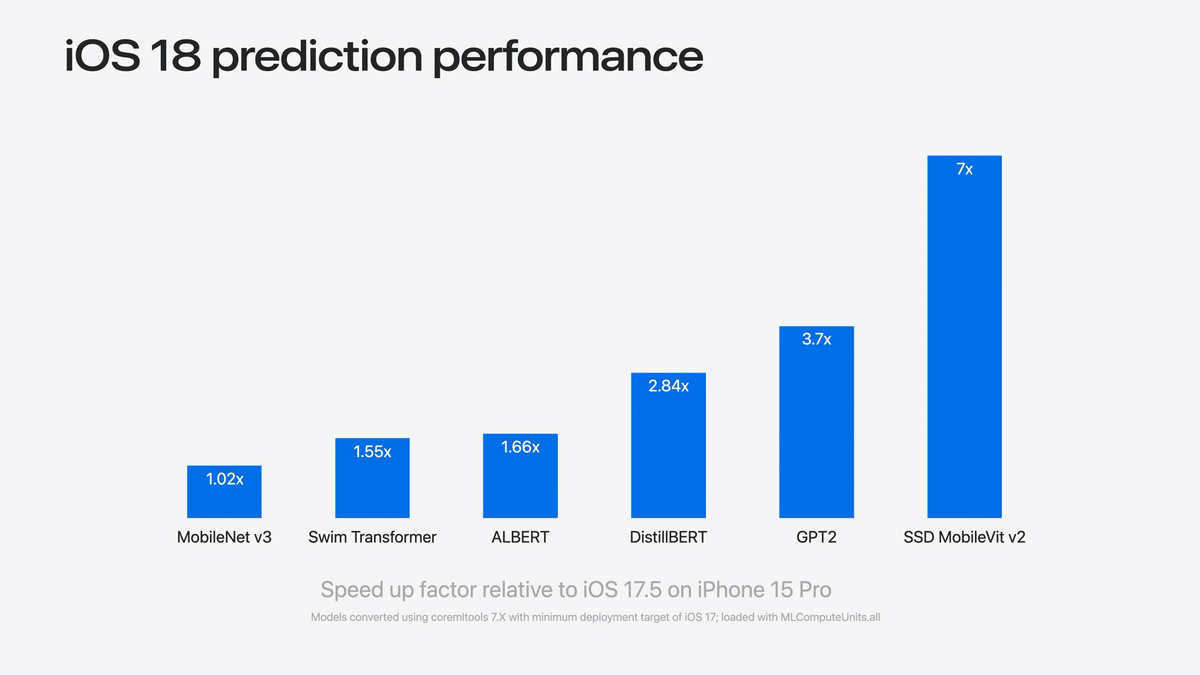
iOS 17とiOS 18の相対的な予測時間を比較すると、多くのモデルでiOS 18の方が速い
この高速化はOSに付属しており、モデルの再コンパイルやコードの変更は必要ない
つまり再変換とか何もしなくてもiOS 18ではiOS 17よりも推論が速く動く!
MLTensor
課題
MLTensorの前提となる課題感の話から。
ここから先は

#WWDC24 の勉強メモ
WWDC 2024やiOS 18, visionOS 2についてセッションやサンプルを見つつ勉強したことを記事にしていくマガジンです。 …
最後まで読んでいただきありがとうございます!もし参考になる部分があれば、スキを押していただけると励みになります。 Twitterもフォローしていただけたら嬉しいです。 https://twitter.com/shu223/