
文春オンラインの記事分析を支える爆速ダッシュボードを作るまで

従来のGoogleアナリティクスである、ユニバーサル アナリティクス(以下UA)のサポートがいよいよ2023年7月に終了することが、先日アナウンスされました(※)。昨年対比やトレンドをチェックすることを考えると、2022年内できるだけ早めに次世代のGoogleアナリティクス(以下GA4)へ移行したいWebメディア運営者も多いかと思います。新しいツールの勉強や、既存システムの改修が必要な問題ではありますが、この機会を、データ収集・可視化の設計を見直し、日々の意思決定の共通言語としてデータを使いやすくするチャンスと捉えてみてはいかがでしょうか。
※ Google、ユニバーサルアナリティクスのサポートを2023年7月1日に終了。早めのGA4移行を推奨
このnoteでは、前半でダッシュボードによるデータの可視化にコストをかけるべき理由を整理します。後半では、2021年秋に文春オンラインのダッシュボードを、GA4とBigQuery(※)を活用してリニューアルした経験を公開します。月間6億PVを超えることもある大量のトラフィックデータの管理方法、編集者が毎日知見を得ることができるダッシュボードの工夫、そしてデータエンジニアリングの重要性に興味のあるWebメディア関係者の方はぜひご覧ください。
※ Googleの提供するクラウド型のデータウェアハウス。ビッグデータを処理できる分析用のデータベースです。
データカルチャーへの第一歩は、優れた可視化
私は普段データアナリストとして、データ分析を軸にWebメディアに対してコンサルティングを提供しています。データアナリストと名乗ってはいますが、Webメディアに対しては正直なところ全く難しい分析を行っていません。むしろ、データの整備と可視化を通して、編集部のメンバーが自ずと仮説を思いつき、アクションを行って検証できるための環境を整えることに注力しています。
これにはいくつか理由がありますが、第一に、分析によって短期で劇的に改善する施策は多くありません。そして、そのような施策は既にノウハウがある程度固まっているため、十分なデータを貯めて分析によって全く新しい施策を得ようとする前に、成功しているWebメディアの担当者にヒアリングをして着手してしまった方が早いでしょう。
また、Webメディアの成長モデルの起点は良質な記事であり、かつWebメディアは記事の公開頻度が非常に多いです。商業メディアのWebサイトは毎日10本近い記事を公開しているところも多く、試行錯誤するチャンスが非常に多い事業であると考えています。そのため、時間をかけて高度な分析を行うこと以上に、編集者一人一人がデータを使いこなせたほうが効果が大きいと言えるでしょう。コンテンツ自体だけではなく、その届け方についても一つ一つの記事に明確な意図を持って行い、データによるフィードバックを受ければ、コンサルタントのアドバイスよりもよほど有意義にノウハウが溜まっていきます。
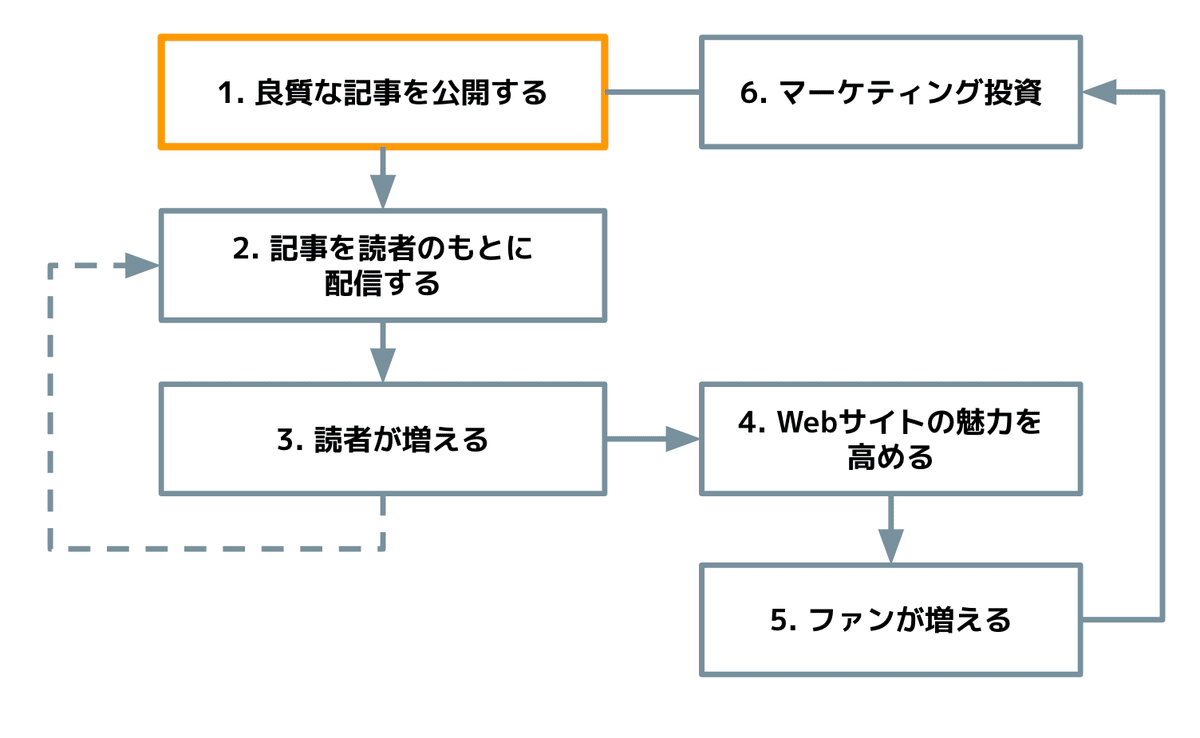
編集者がデータを使いこなすことが重要といっても、現実問題としてWebメディア編集部の全員が、GA4の管理画面やデータ構造を勉強するのは無茶な話でしょう。特にGA4は成熟したプロダクトではなく、新しい機能が加わったり、ドキュメントが修正されることも頻繁にあり、まだ日本語での解説も多くありません。そこで、データアナリストが、公開した記事の多角的な情報を理解しやすく使いやすいダッシュボードを作ることで、社内にデータカルチャーが育っていくでしょう。全員がGA4に詳しくなくとも、データ分析を行うことができます。
データをもとに意思決定をする組織には、エンジニアリングが必要
Webメディア関係者とお話ししていると、Excelで行うようなデータの加工に注力していても、データの収集・整備のプロセス管理にコストをかけているWebメディアは少ないと感じます。例えば、データ収集ツールのタグを設置しただけでほぼカスタマイズしていなかったり、UAのセッションやユーザー数の定義が曖昧だったり、掲げたコンセプトを評価できる手段を用意していなかったりしませんか?
不完全なデータを加工して妥当なインサイトを得るためには、バイアスや誤差を取り除く高度な統計知識が必要になりますし、もしデータの定義が誤っていたら分析自体の意味がなくなります。それよりも、できるだけ正確なデータをシンプルに集計するほうが有用なケースが多いです。このときにデータ収集と整備に責任を持つデータエンジニアの役割を担うエンジニアやアナリストが一人でもいれば、チームの生産性が格段にあがります。
エンジニアリングによって生産性が高まるのはIT企業に限った話ではありません。トラディショナルメディアでもエンジニア組織を社内に持つことにすぐ着手すべきです。Webサイトのフロントエンド、バックエンド、広告による収益化、購読システム、データ分析をそれぞれ別の開発会社やコンサルティング会社に委託し、社内には編集者しかいないWebメディアも見かけますが、社内にエンジニアやWebディレクター/プロダクトマネージャーという専門職がいるといないとでは、スピード感や実行できる施策、提供できるUXに雲泥の差があります。これからのメディアがWebを活用しないことは考えられず、優秀なIT系人材を正社員として、コンテンツ制作人材と同等以上の待遇で採用して損することは全くないと思います。
私の以前のnote「PV至上主義は悪なのか」の分析や、今回のデータ基盤がスムーズに実現できたのも、文春オンラインにもともとWebディレクターやエンジニアがいて、分析環境を構築する下地があったことが非常に大きいです。
文春オンラインでいち早くGA4移行を目指したわけ
文春オンラインでは、2021年夏までUAでデータ収集を行い、データポータルというGoogleのBIツールに直接繋いでダッシュボードを作ることで可視化していました。このダッシュボードは、編集部やデジタル部のニーズ、Webサイトの変更に応じて改修を何度か行いました。
しかし、昨年7-9月期に月間平均5億PVを超えた時は、記事分析ダッシュボードの表示に数十秒かかった挙句にエラーになり、記事に対する読者反応のフィードバックデータが得られないという問題が頻発しました。このように、データの構造が変わらなくてもデータ量が増えただけで壊れるというのは、データ基盤に関して一般的に起こり得る問題です。
データを表示するために待たされることが増えると、当然データを見るのが面倒くさくなり、データカルチャーを損ねてしまいます。そのため、データが爆速表示されるダッシュボードを目指してリニューアルすることにしました。
そもそもデータポータルが重くなった原因は、多角的な分析をするために、データポータル側でさまざまな計算・集計を行っていたためです。PVが増加すると、計算・集計を行う量も比例して増えてしまっていました。
これを解消するため、閲読データは全てBigQueryにエクスポートし、見たいデータはあらかじめ全て集計したテーブル(データマートと呼びます)を用意します。データポータルにはロジックを置かず、グラフの表示に徹するような仕組みにして高速化を実現します。
この仕組みの恩恵として、Googleアナリティクスの管理画面に縛られずに柔軟なデータ分析ができるようになります。データ分析に慣れた人であればSQLで欲しい形のデータを抽出してGoogle ColabやRStudioで容易に扱えるようになりますし、Googleワークスペースを利用していれば、SQLが書けなくともスプレッドシートのデータコネクタ機能を使うことで、簡単に集計済みデータを入手できます。
BigQueryで集計することを決めた段階で、BigQuery連携が容易でイベント設計の自由度が高いGA4に、UAから乗り換えることを決めました。
ちなみに、BigQueryを使わずとも、GTMでGA4のデータ収集設定をしっかり行い、管理画面を使いこなすことで十分に分析できます。これから整備していく場合はまずはそこから始めた方が良いでしょう。その次のステップとして、データ分析の威力を十分に発揮し、大事なデータを自社で管理するためには、エンジニアリングコストをかけてでもBigQueryのデータ分析基盤を整えるメリットは大きいと思います。
リニューアルした記事分析ダッシュボード
まずはリニューアルしたダッシュボードをお見せします。記事IDを入力すれば2秒程度で表示され、ストレスなく読者の反応をチェックできます。また、BigQueryの月間コストも今のところ1万円程度しかかかっていません。
ダッシュボードはできるだけグラフで表示するようにこだわっています。大事なKPIは数値で大きく表示しますが、読者の解像度を高める多角的な指標を視覚的に表示することで、他の記事との違いを一目で把握できます。
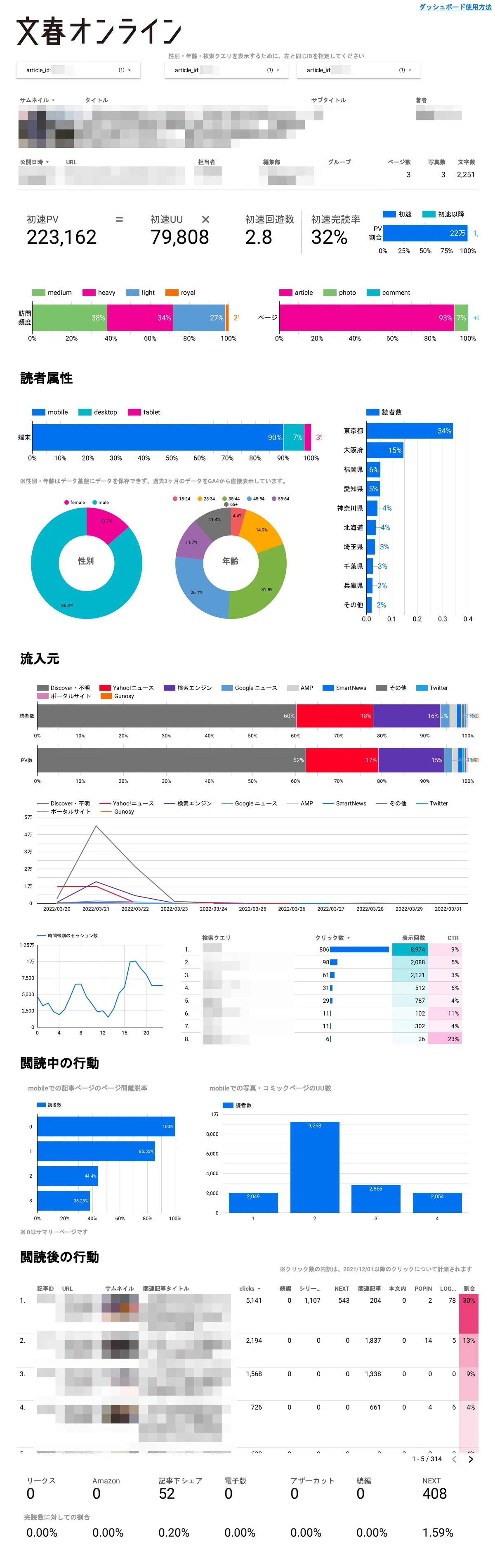
私は普段、記事を分析する際に3つの切り口を意識しています。
Who: どんな人が読んだのか
How: どんなタイミング・タッチポイントで読んだのか(フィジカル・アベイラビリティ)
Why: なぜ読み始めて、なぜ読むのをやめたのか(メンタル・アベイラビリティ)
どんな人が読んだのかを考えるために、読者の性別・年齢層・端末・地域・訪問頻度の指標を表示します。どんなタイミング・タッチポイントで読んだのかを考えるために、流入元・訪問時刻・訪問数の日時トレンドを表示します。なぜ読み始めて、なぜ読むのをやめたのかを考えるために、読了率や離脱ポイント、関連記事でクリックされた記事、記事末尾のCTAのクリック率を表示します。
これらの指標を、Webサイト全体の平均や他の記事と比較することで、その記事の読まれ方を多面的に理解していきます。このとき大事なのは、アナリストなら事前に予想すること、編集者なら届け方の意図を持って記事を公開することです。事前の予想・意図と実際の結果が異なるポイントにこそアクションにつながるヒントがある可能性が高いですし、この営みを通して編集者のセンスが高まっていきます。
これ以降は具体的な設計の話を書いていきます。もっといい方法がありそうにも思いますが、GA4 + BigQuery で分析したり、ダッシュボードを整備したりすることを考えている方の参考になれば幸いです。
収集しているGA4のイベント
Webメディア分析で使うデータは主に、閲読データ、記事データ、会員データの3種類です。閲読データはGTMで設定したGA4で収集し、記事データはCMSから抽出し、会員データは購読システムから抽出します。このときに、記事IDと会員IDを、GA4のイベントの付随情報としてデータレイヤーを利用して収集します。これにより、3種類のデータを結合してさまざまな分析が可能になります。
閲読データ
GA4の拡張計測機能をオンにすると、自動でさまざまなイベントが収集されます。また、どのイベントもイベントパラメータという仕組みを利用すると付随情報を収集できます。詳細はGA4やGTMのサポートサイトをご参照いただくとして、ここでは私がWebメディア分析の際に重要視するイベントについて紹介します。
page_view イベント
拡張計測機能をオンにした場合、測定機能の強化イベントとして自動で収集されますが、イベントパラメータとして記事IDや公開日時を収集するためにはGTMでちょっとカスタマイズする必要があります。
具体的には、GTMの初期化トリガーでGA4の設定タグを読み込む際にpage_viewイベントを送信し、データレイヤー変数としてウェブサイトから渡された記事IDや公開日時をイベントパラメータにセットします。
記事IDは、ページURL(page_location)を正規表現で解析すれば取得できるサイト構造のメディアも多いかもしれません。ただ、URLを正規表現でパースするロジックが都度必要になるのは面倒なので、データレイヤーで渡せるように開発してしまうことをお勧めします。ちなみに、わざわざURLではなく記事IDで集計したい理由ですが、シンプルにページURLで集計するとUTMパラメータが付いたり、改ページでクエリ文字列が付いたり、本文と画像ギャラリーのURLが異なったりするケースがあり、正確な集計にならないためです。
公開日時を収集する理由は、文春オンラインでは初速といって公開後1週間以内の指標を目安にしているためです。後から記事データを結合して計算してもいいのですが、頻繁に行う集計なので、閲読データだけで計算できるよう、公開日時も多くのイベントで収集しています。
click イベント
拡張計測機能をオンにした場合、離脱クリックであれば測定機能の強化イベントとして自動で収集されます。しかし、私のユースケースでは記事を読み終えた後の回遊を計測したいため、GTMでカスタマイズして設定します。例えば、次ページへの遷移、関連記事のクリック、画像ギャラリーへの遷移、会員登録ページへの遷移、記事のシェアといった行動を計測することで、記事を読んだ読者の心理を洞察しています。
トリガーと値の受け渡しにはHTML5のカスタムデータ属性を用いています。クリックを計測したいリンク要素に、data-tracking=”relatedLink” のようなカスタムデータ属性を付与しておき、それを用いてGTMでGA4設定を行うことで、内部回遊クリック時にclickイベントを送信できるようにします。
また、上記のカスタムデータ属性でクリックされた要素の種類を取得するだけでなく、クリックが発生したページの記事IDと公開日時、リンク先URLもイベントパラメータで取得しておくと、分析がやりやすくなります。
read_to_end イベント
これは独自に作ったカスタムイベントです。スクロール深度であれば自動収集されますが、Webメディアの記事の場合、長さがまちまちであるだけでなく、関連記事ウィジェットがたくさんついていることが多いため、正確に読了を計測するためにはカスタムイベントを送信する必要があります。
本文末尾にピクセルを置いて、データレイヤー変数にイベントをプッシュしてGTMで検知する実装をしています。もしくは、本文末尾にだけ必ず存在する要素に対してGTMの要素の表示トリガーを発火させる仕組みにしてもいいでしょう。このイベントでも、イベントパラメータで読了した記事IDを付与しておきます。
sign_up / login イベント
推奨イベントとして公式ドキュメントに記載されているイベントです。会員システムを用意しているサイトであれば、どんな記事・流入元が会員獲得につながったのか分析するためにぜひ取得したいイベントです。自動収集はしてくれないので、会員登録が行われた時点でデータレイヤーを利用してGTMのトリガーを設定する必要があるでしょう。
このイベントでは、新たに登録した会員のIDをユーザープロパティとして取得できるとベターです。イベントパラメータとは異なりユーザープロパティとして収集することで、(ブラウザのCookieに紐づく同一ユーザーと認識できる限り)以降のイベントでは自動的に会員IDが紐づきます。会員データと閲読データが紐づくことで、分析できる幅が大きく広がります。ただし、会員システムから会員IDをサイトに返してデータレイヤーに渡す開発が必要なので、会員システムによっては実現できないかもしれません。なお、メールアドレスのような個人情報をGAで収集することはNGですのでご注意ください。
その他
GA4では、session_startイベントやuser_engagementイベントといったイベントもありますが、このケースでは分析には使用していません。後々BigQueryでpage_viewイベントやclickイベントの生データが見られれば十分だったり、滞在時間やエンゲージメントという概念よりも読了率や直帰率のような概念の方が編集者のアクションにつながりやすいかなと考えているためです。ただ、記事ではなくサイト全体をプロダクトとして改善したい場合や、KPI設計を変えた場合はもちろん重視するイベントも変わります。
なお、GA4とは関係ないですが、どこまで読んだかを把握するために文春オンラインではヒートマップツールも併用しています。とはいえ、いちいち全ての記事をヒートマップツールで調べるのは非常に面倒なので、read_to_endイベントをもとにした読了率などをみて明らかに他より低い記事があれば、どこで離脱してしまったのか調べるという使い方をしています。
また、impressionイベントを取得してもいいのですが、安易に設定しすぎるとイベント数がかなり多くなってしまいます。GA4有料版の料金プランは従量制で値段が変わる部分があるので、使用頻度が少ないイベントを大量取得するのは避けたいところです。現状では、CTRを測りたい大事なイベントは大抵記事末尾にあるため、read_to_endイベントで代用しています。
他には、記事と合わせて動画でもニュースを伝えるWebメディアの場合は、video_start / video_progress / video_complete イベントはしっかり取得すべきでしょう。閲読データと動画視聴データを統合して分析できるようになります。YouTube動画であれば、JavaScript API サポートを有効にすることで、測定機能の強化イベントとして自動収集されます。その他の動画プレイヤーを使用している場合も、ウェブサイトの開発工数を確保できれば、データレイヤーを通してGTMでイベント発火設定を行えると良いでしょう。
記事データ
記事データというのは、タイトルやサブタイトル、公開日時、カテゴリ、著者、連載名、担当者、文字数、画像数、ページ数、サムネイル画像・・・等の、閲読行動ではなく記事自体のデータです。GA管理画面ではなくデータポータル等のBIツールをメインに分析するなら、記事データは必ずしもGAで収集しないといけないわけではありません。
もちろんイベントパラメータとしてpage_viewイベントに渡してもいいのですが、記事データを全部渡す実装をして管理するのも大変ですし、記事データは分析以外の場面でも利用することが多いので、スプレッドシートやAPIで連携できるようにしておいたほうが便利です。
文春オンラインでは、当初はGoogle App Scriptを書いて、機械的に読み取りやすいフォーマットでスプレッドシートに記事データを貯めて、記事IDをキーにしてデータポータルで行動データと結合して分析していました。現在はCMS側にAPIを作ってもらって、日次で更新された記事データを取得するスクリプトをワークフローエンジンで実行してBigQueryに保存しています。
閲読データと記事データがBigQueryに存在し、記事IDで結合できる状態になっていることで、分析の自由度が高まりますし、過去記事から関連度の高い記事を編集者に推薦するようなシステムも構築しやすくなります。
会員データ
会員システムを持っているサイトでは、会員に関するデータも BigQuery に入れておいて、GA4の sign_up / login イベントを実装しておけば会員の閲読ログを分析に使えるようになります。会員登録時の規約次第ですが、メールマガジンを送る対象や内容をデータをもとに設定したり、ユーザーインタビューの対象を抽出したりといった使い方も考えられます。
ただし、会員データは個人を特定しうる情報を持っているため、適切な暗号化と権限管理を行って個人情報の扱いに気をつけるようにしましょう。
BigQueryのデータセット
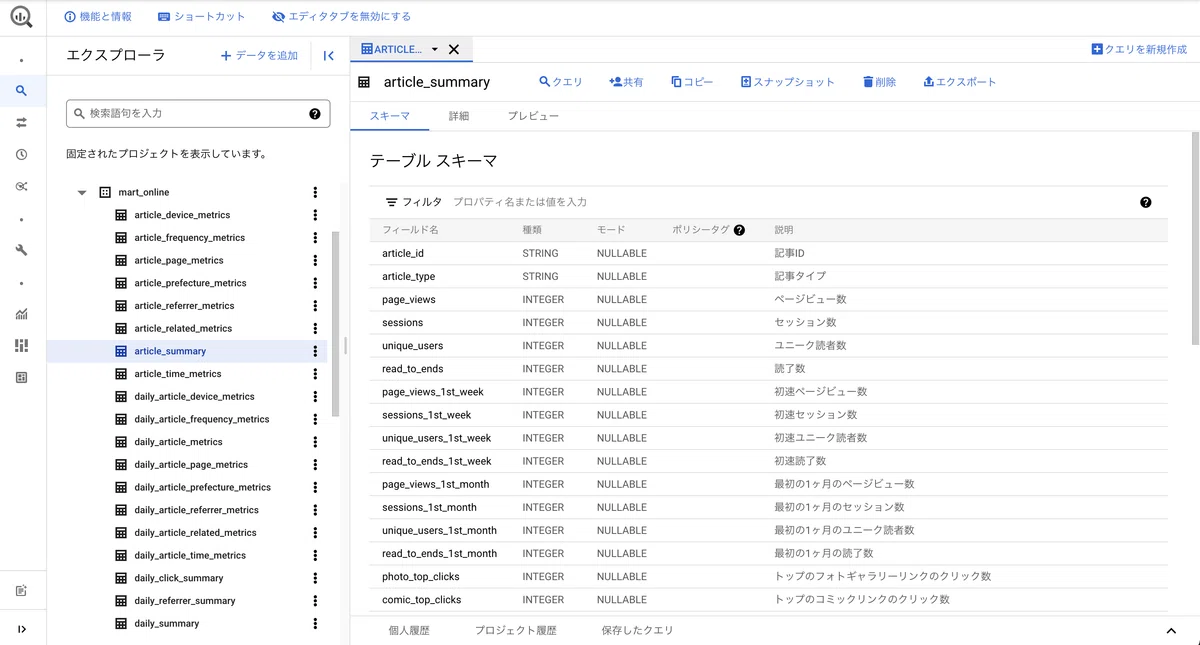
GA4の設定画面では、ボタンをぽちぽちしていくだけで、BigQueryにデータをエクスポートできます。エクスポートされたデータは、日付でシャーディングされたイベント一覧データという、そのままでは分析に使いづらい形になっています。これをもとに分析しやすい状態に前処理したwarehouse層と、warehouse層をもとに可視化するデータを事前集計したmart層を作っていきます。
warehouseデータセット
warehouse層は分析しやすいようデータを前処理したテーブルの集まりです。使用するイベントごとにテーブルを作り、それぞれイベント発生日でパーティショニングし、ネストを解除してイベントパラメータを取り出し、不必要なカラムは除外しています。page_viewsテーブルでは、次のページIDのカラムや、エントランス・離脱ページか否かのカラム等も、分析で使用頻度が多いのでSQLのWINDOW関数を用いてあらかじめ付与しています。なお、warehouse_に続く接尾辞はメディアブランドを示す文字列です。
warehouse_online.page_views
warehouse_online.clicks
さらに、分析しやすいように page_viewsテーブルをもとにして、セッションに関する情報をいれたテーブルや、訪問頻度などのユーザー情報テーブルも作っています。セッションIDは各イベントで user_pseudo_idとga_session_idを用いてカラムを作成して結合できるようにしています。
warehouse_online.sessions
warehouse_online.users
また、記事IDで一意になった、記事データが入ったテーブルも用意しています。
warehouse_online.articles
上記の各テーブルで、DATE型やDATETIME型は日本標準時にしておく等の細かい前処理をして分析時に楽ができるようにしておきます。また、パーティションフィルタを要求するように作っておくことで、不用意に全件集計して高額な料金を請求されることがないようにしてあります。
martデータセット
mart層はデータポータルで表示するグラフの元となるテーブルの集まりで、用途に特化して集計しています。記事の閲読データを集計するときに困るのが、記事の累積PVをwarehouseから集計しようとすると、集計対象データが非常に多くなりコストがかかることです。そのための工夫として、記事公開日から現在までの全ての日付テーブルに対して集計しようとせずに、日次で記事IDごとに集計済みのテーブルを作っておき(daily_article_***)、それを集計するようにしています(article_***)。これなら article_***テーブルを都度再作成しても大したコストがかかりません。
バッチ処理を行うワークフローエンジン
上記のBigQueryデータセット群を日々更新していくためには、バッチ処理を管理するワークフローエンジンが必要です。とはいえ、そんなに複雑なジョブがあるわけでもなく、依存関係も比較的シンプルなので、ライトに実現したいと考えました。が、ぴったりニーズに合うツールが見つからず(大抵オーバースペックすぎる)、車輪の再発明だろうなと思いつつPythonでシンプルなワークフローエンジンを内製しました。
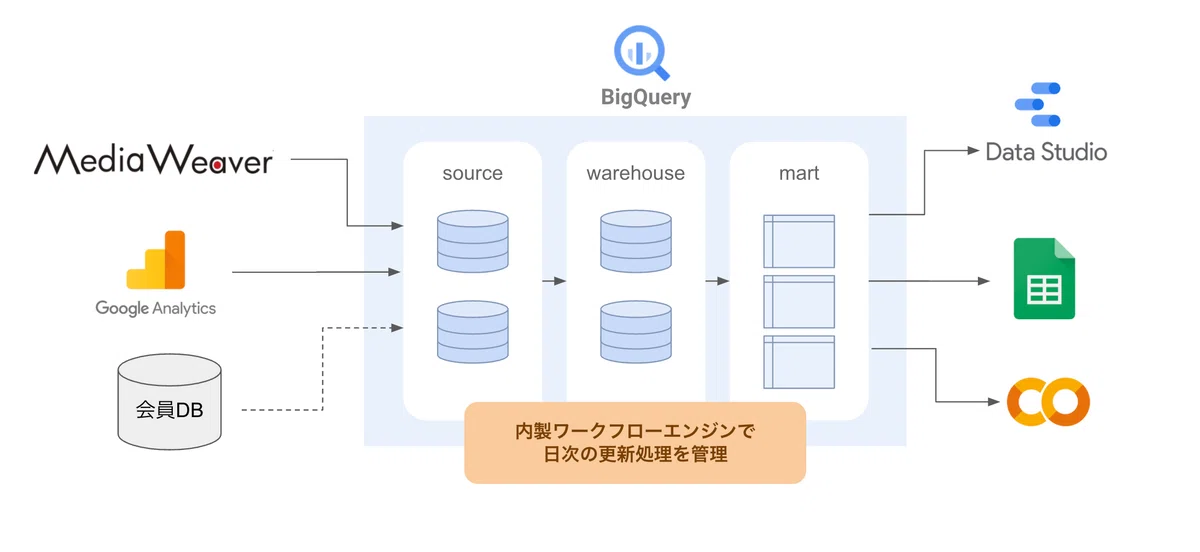
機能要件は「指定した時間に毎日ジョブを実行すること」「SQL間の依存関係をもとに実行順序を決めること」「ジョブの成功・失敗を記録し、通知してくれること」の3つです。
当初はGitHub Actionsで定期実行していました。現在は、他の社内システムからデータを取得するときにIPアドレスが必要だったため、GCPのCloud Runに移行して外部IPアドレスを設定し、Cloud Schedulerで定期実行しています。
また、「GitHubで管理されたデータマート構築基盤の紹介」(ZOZO TECH BLOG)を参考に、SQLを解析して依存関係を解決する簡単なロジックを書きました。ジョブの成功・失敗は BigQuery に utilityデータセットを作ってそこに記録し、Slackに通知するようにしました。
データ整合性のテストをどう書くか等、改善余地はたくさんありますが、とりあえず日次で必要データをBigQueryにロードして、データを前処理する運用はこの数ヶ月問題なく回っています。
また、最近GA4からエクスポートされるストリーミングデータを使って、リアルタイムで関連記事の効果計測をすることを始めました。Google Discoverなど流入元が多様化し、配信先と同様に自社ドメインの活動をリアルタイムでチェックする重要性が高まってきたためです。GA4のストリーミングデータが入るevents_intraday データセットを集計する論理ビューを作ってみたのですが、頻繁にチェックする人が増えるとコストが高くなりそうなので、1時間ごとに専用の物理テーブルを更新する仕組みにしてもいいかもしれません。
まとめ
後半やや専門的な話が多くなってしまいましたが、一番伝えたかったことはGA4やGTM、Webの技術を学んで使いこなす担当者をぜひ設ける、あるいは採用してデータの可視化に力を入れることで、継続的にWeb編集部に知見がたまる環境が作れるということです。
この内容を公開することにGOサインを出してくださったクライアントの文藝春秋社は、デジタル関連の開発・ビジネスに特化した新会社「Bunshun Tech ZERO合同会社」を立ち上げました。IT人材の採用に力を入れていますので、興味がある方はぜひ話を聞きに行ってみてください。
おまけ:page_viewsテーブルを作るSQL
繰り返し出現するロジックはutilityデータセットのUDFにしていますが、GA4からエクスポートされたデータから、page_viewイベントをwarehouseデータセットに整理するDDL・DMLの全体像はこんな雰囲気です。
CREATE TABLE IF NOT EXISTS `bunshun.warehouse_online.page_views`
(
event_date DATE OPTIONS(description = "イベント発生日"),
event_timestamp TIMESTAMP OPTIONS(description = "イベント発生タイムスタンプ"),
user_id STRING OPTIONS(description = "ユーザーID、現在は空だが、将来的に文春の会員IDが入る想定"),
user_pseudo_id STRING OPTIONS(description = "GAが付与するcookieベースのユーザーID、UUをカウントするときに使用"),
article_id STRING OPTIONS(description = "記事ID"),
page_view_id STRING OPTIONS(description = "ページビューID、ページが読み込まれたときに付与される"),
published_at DATETIME OPTIONS(description = "公開日時(日本時間)"),
page_type STRING OPTIONS(description = "ページタイプ"),
page_number INT64 OPTIONS(description = "ページ番号"),
page_url STRING OPTIONS(description = "ページURL"),
page_url_canonical STRING OPTIONS(description = "ページカノニカルURL"),
page_title STRING OPTIONS(description = "ページタイトル"),
page_referrer STRING OPTIONS(description = "ページリファラー"),
source STRING OPTIONS(description = "UTMパラメータsource"),
medium STRING OPTIONS(description = "UTMパラメータmedium"),
campaign STRING OPTIONS(description = "UTMパラメータcampaign"),
content STRING OPTIONS(description = "UTMパラメータcontent"),
term STRING OPTIONS(description = "UTMパラメータterm"),
session_id STRING OPTIONS(description = "セッションID"),
session_number INT64 OPTIONS(description = "ユーザーの累計セッション数"),
device_category STRING OPTIONS(description = "デバイス種類"),
device_mobile_brand_name STRING OPTIONS(description = "デバイスのブランド"),
device_mobile_model_name STRING OPTIONS(description = "デバイスのモデル"),
device_operating_system STRING OPTIONS(description = "デバイスのOS"),
device_operating_system_version STRING OPTIONS(description = "デバイスのOSバージョン"),
device_browser STRING OPTIONS(description = "ブラウザ"),
device_browser_version STRING OPTIONS(description = "ブラウザのバージョン"),
prefecture STRING OPTIONS(description = "都道府県"),
is_entrance BOOL OPTIONS(description = "外部ドメインからの流入ページ"),
is_exit BOOL OPTIONS(description = "外部ドメインへの流出ページ"),
is_bounce BOOL OPTIONS(description = "外部ドメインからの流入かつ、外部ドメインへの流出、つまり直帰ページ"),
following_page_url STRING OPTIONS(description = "次のページのURL"),
following_page_url_canonical STRING OPTIONS(description = "次のページのカノニカルURL"),
following_article_id STRING OPTIONS(description = "次のページの記事ID"),
following_page_number INT64 OPTIONS(description = "次のページのページ番号"),
following_page_type STRING OPTIONS(description = "次のページのページタイプ"),
previous_page_url STRING OPTIONS(description = "前のページのURL"),
previous_page_url_canonical STRING OPTIONS(description = "前のページのカノニカルURL"),
previous_article_id STRING OPTIONS(description = "前のページの記事ID"),
previous_page_number INT64 OPTIONS(description = "前のページのページ番号"),
previous_page_type STRING OPTIONS(description = "前のページのページタイプ"),
read_to_end BOOL OPTIONS(description = "読了したか否か、最終ページでのみTrueになり得る"),
created_timestamp TIMESTAMP OPTIONS(description = "レコード作成タイムスタンプ")
)
PARTITION BY event_date
OPTIONS(
require_partition_filter=true,
description = "ページビューイベント"
);
INSERT INTO `bunshun.warehouse_online.page_views`
WITH
page_view AS (
SELECT DISTINCT
PARSE_DATE('%Y%m%d', event_date) AS event_date,
TIMESTAMP_MICROS(event_timestamp) AS event_timestamp,
user_id,
user_pseudo_id,
IFNULL(utility.EXTRACT_EVENT_STRING_VALUE('article_id', event_params), CAST(utility.EXTRACT_EVENT_INT_VALUE('article_id', event_params) AS STRING)) AS article_id,
utility.EXTRACT_EVENT_STRING_VALUE('page_view_id', event_params) AS page_view_id,
SAFE.PARSE_DATETIME('%Y/%m/%d %H:%M:%S', utility.EXTRACT_EVENT_STRING_VALUE('published_at', event_params)) AS published_at,
utility.EXTRACT_EVENT_STRING_VALUE('page_type', event_params) AS page_type,
utility.CALC_PAGE_NUMBER(
utility.EXTRACT_EVENT_STRING_VALUE('page_location', event_params),
utility.EXTRACT_EVENT_STRING_VALUE('page_type', event_params),
device.category
) AS page_number,
utility.EXTRACT_EVENT_STRING_VALUE('page_location', event_params) AS page_url,
utility.NORMALIZE_URL(utility.EXTRACT_EVENT_STRING_VALUE('page_location', event_params)) AS page_url_canonical,
utility.EXTRACT_EVENT_STRING_VALUE('page_title', event_params) AS page_title,
utility.EXTRACT_EVENT_STRING_VALUE('page_referrer', event_params) AS page_referrer,
utility.EXTRACT_EVENT_STRING_VALUE('source', event_params) AS source,
utility.EXTRACT_EVENT_STRING_VALUE('medium', event_params) AS medium,
utility.EXTRACT_EVENT_STRING_VALUE('campaign', event_params) AS campaign,
utility.EXTRACT_EVENT_STRING_VALUE('content', event_params) AS content,
utility.EXTRACT_EVENT_STRING_VALUE('term', event_params) AS term,
CONCAT(user_pseudo_id, utility.EXTRACT_EVENT_INT_VALUE('ga_session_id', event_params)) AS session_id,
utility.EXTRACT_EVENT_INT_VALUE('ga_session_number', event_params) AS session_number,
device.category AS device_category,
device.mobile_brand_name AS device_mobile_brand_name,
device.mobile_model_name AS device_mobile_model_name,
device.operating_system AS device_operating_system,
device.operating_system_version AS device_operating_system_version,
device.web_info.browser AS device_browser,
device.web_info.browser_version AS device_browser_version,
utility.CONVERT_REGION(geo.region) AS prefecture
FROM
`bunshun.analytics_XXXXXXXX.events_*`
WHERE
_TABLE_SUFFIX = FORMAT_DATE('%Y%m%d', DATE_SUB(CURRENT_DATE('Asia/Tokyo'), INTERVAL 2 DAY))
AND event_name = 'page_view'
)
SELECT
*,
-- entrance, exit, bounce
LAG(user_pseudo_id) OVER (PARTITION BY session_id ORDER BY event_timestamp) IS NULL AS is_entrance,
LEAD(user_pseudo_id) OVER (PARTITION BY session_id ORDER BY event_timestamp) IS NULL AS is_exit,
LAG(user_pseudo_id) OVER (PARTITION BY session_id ORDER BY event_timestamp) IS NULL AND LEAD(user_pseudo_id) OVER (PARTITION BY session_id ORDER BY event_timestamp) IS NULL AS is_bounce,
-- following page_view
LEAD(page_url) OVER (PARTITION BY session_id ORDER BY event_timestamp) AS following_page_url,
LEAD(page_url_canonical) OVER (PARTITION BY session_id ORDER BY event_timestamp) AS following_page_url_canonical,
LEAD(article_id) OVER (PARTITION BY session_id ORDER BY event_timestamp) AS following_article_id,
LEAD(page_number) OVER (PARTITION BY session_id ORDER BY event_timestamp) AS following_page_number,
LEAD(page_type) OVER (PARTITION BY session_id ORDER BY event_timestamp) AS following_page_type,
-- previous page_view
LAG(page_url) OVER (PARTITION BY session_id ORDER BY event_timestamp) AS previous_page_url,
LAG(page_url_canonical) OVER (PARTITION BY session_id ORDER BY event_timestamp) AS previous_page_url_canonical,
LAG(article_id) OVER (PARTITION BY session_id ORDER BY event_timestamp) AS previous_article_id,
LAG(page_number) OVER (PARTITION BY session_id ORDER BY event_timestamp) AS previous_page_number,
LAG(page_type) OVER (PARTITION BY session_id ORDER BY event_timestamp) AS previous_page_type,
-- read_to_end
EXISTS(
SELECT
*
FROM
(
SELECT
utility.EXTRACT_EVENT_STRING_VALUE('page_view_id', event_params) AS page_view_id,
FROM
`bunshun.analytics_XXXXXXXX.events_*`
WHERE
_TABLE_SUFFIX = FORMAT_DATE('%Y%m%d', DATE_SUB(CURRENT_DATE('Asia/Tokyo'), INTERVAL 2 DAY))
AND event_name = 'read_to_end'
) AS read_to_end
WHERE
read_to_end.page_view_id = page_view.page_view_id
) AS read_to_end,
CURRENT_TIMESTAMP() AS created_timestamp
FROM
page_view;
この記事が気に入ったらサポートをしてみませんか?