
【第3話】 統計分析をRからJuliaに~更にプロット

前回の続きですが、Juliaでこれはとても便利だなと思った点を紹介します。
全部を使うわけではないですが、今回利用しようとしたパッケージはこちらです。

ではデータを作ってみましょう。18歳から80歳までの患者100人分、AとBと2つの異なる処置を行い、良くなった、悪くなった、変わんないの3つの結果があるとします。

Rではsummary()で簡単な結果が出せますが、StatsBaseを利用すると同じことができます。

それぞれのデータを用いてDataFrameを作成します。

中身はこうなっています

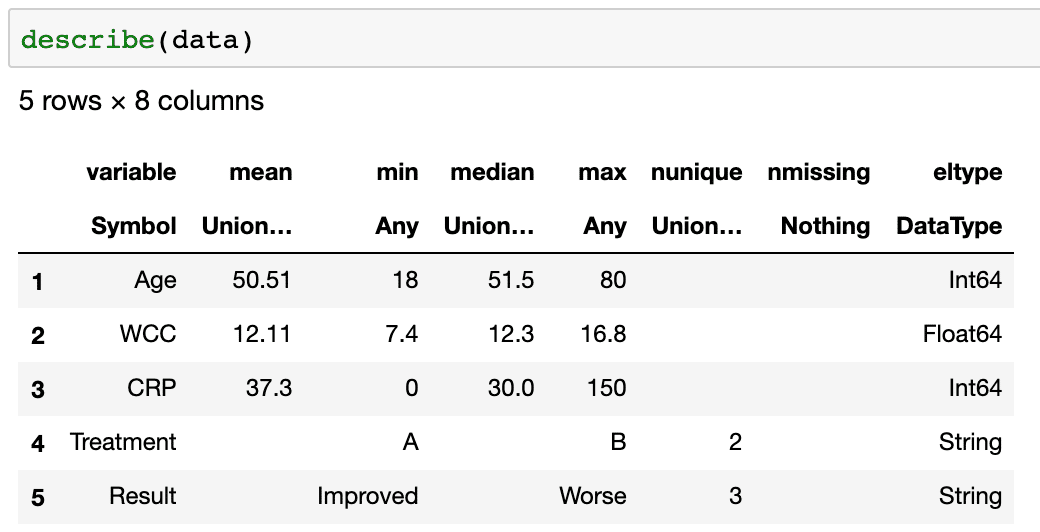
ここではTreatmentとResultに注目です。患者のうちAとBという異なる処置方法を行った2つのグループがあります。
size(data)でみたように100人の結果がありますが、Aのグループに何人、Bのグループに何人いるかみたい場合、こう記述します
by(data, :Treatment, size)ですが、そうすると行列両方を表示してしまうのでこうします
by(data, :Treatment, df -> DataFrame(N = size(df, 1)))
グループAには46人、グループBには54人いることが分かります。
ではグループAの平均年齢はいくつでしょう。

dataをTreatmentごとにグループ分けして、平均結果を表示するとしてるわけですが、これたった1行です。
では年齢ごとの分布を図に表そうとした場合はどうすればいいでしょうか。ここでマクロ言語が使えます。@df
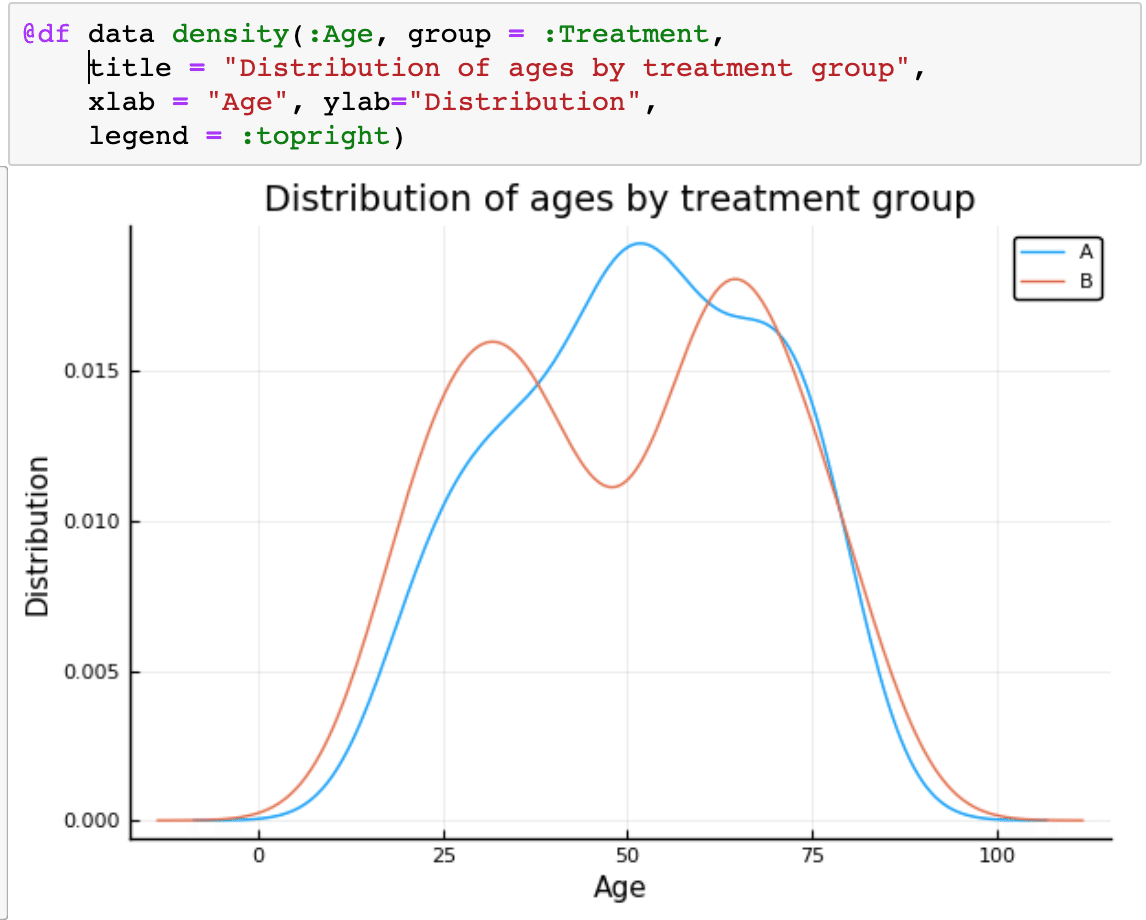
dataというデータフレームから年齢をx軸にして、グループAとBの分布を見たいわけですが、それがタイトルやxyのラベルなどの表示をなくせばこれも1行でできます。Rを使ってるような感覚です。
白血球の数別のボックスプロットを処置の結果ごとに描画してみましょう。

RでしていたことをPythonでしようとするととても面倒に感じていたことがありましたが、このJuliaのシンプルさは魅力的です。
Rではpairs()を使う頻度が高かったですが、Juliaの場合は下記のようになります。


正直こんなにシンプルだとは思っていませんでした。@dfもそうですがマクロ言語便利すぎです。
次回は教材の第3章Linear Regressionに関してJuliaを使っていきます。
この記事が気に入ったらサポートをしてみませんか?