
1000倍の速度差が出てしまうコードの違い - Python PandasとJuliaの例

Python Pandasを使われている方々にとってみれば既に知っている方法だとは思いますが,効率のいい反復処理のやり方が紹介されていたのをたまたまみつけたので,同じことをJuliaでも試してみてPython Pandasの一番速い方法と比べてみました。
元記事はこちらです。
ここで紹介されていたのは2つの列(src_bytes, dst_bytes)を加算する速度がやり方によって大きく変わることです。
1. Iterrows
2. For loop with .loc or .iloc
3. Apply
4. Itertuples
5. List comprehensions
6. Pandas vectorization
7. NumPy vectorization
既にご存知の方も多いと思いますが、私の環境で(Mac mini M1 8GB, Python 3.9.7, Pandas 1.4.1)記事同様に7つの方法をやってみました。
import pandas as pd
import numpy as np
df = pd.read_csv('https://raw.githubusercontent.com/mlabonne/how-to-data-science/main/data/nslkdd_test.txt')





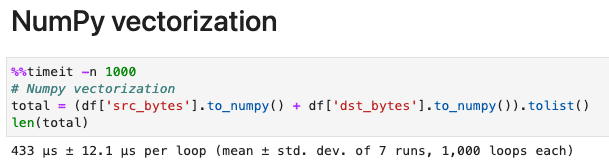
記事でも書いてありますが、私の環境でも442msが433μsと1000倍も短縮されました。結論から言えば、List Comprehensionを使うようにし、出来るならVecotrization(ベクトル化)しろって事ですね。
Julia DataFrames
ふと同じことをJuliaでやったらどうなるかと思い試してみました。同じ環境(Mac mini M1 8GB, Julia 1.6.5, DataFrames 1.3.2)で同じデータでの比較です。
using DataFrames
using CSV
using HTTP
using BenchmarkTools
url = "https://raw.githubusercontent.com/mlabonne/how-to-data-science/main/data/nslkdd_test.txt"
df = CSV.File(HTTP.get(url).body) |> DataFrame



中央値をとりますが、それでも22msから8.9μsまで短縮されました。ここでも1000倍も短縮されました。
Julia DataFramesでもPython Pandasでも、やり方次第で1000倍も違うとは、本当に知っておかないともったいないですね
この記事が気に入ったらサポートをしてみませんか?