
クラウド時代を生き残るには!?今アツいクラウド基盤とデータモデル

皆さんこんにちは!
昨今、アジャイルでクラウドなデータ基盤を整える中で、データモデルの重要性が注目されてきています。
今回はそんな、アジャイルでクラウドなデータ基盤にとって適切とされるデータモデル”Data Vault”とは何か?を説明します!
クラウドでデータを活用するための基盤を導入したいが、どうすればいいかわからない・・・といった方のお役に立てれば幸いです。
クラウド基盤の特徴と昨今のデータ活用
クラウド基盤とは、AWS(Amazon Web Service)やMicrosoft Azureといった製品に代表される、コンピューティングリソース(ストレージ、サーバー、ネットワーキング、データベースなど)を、インターネットを通じて提供するサービスのことを指します。
このようなサービスの普及により、様々な会社が従来よりも遥かに安価に、さらに自分たちでデータベースを設計しなくてもこれまでより遥かに豊富なデータを扱えるようになりました。
クラウド基盤は特に全社を横断したデータ利活用を行うといったケースで利用されています。例えば以下のような画像を御覧ください。
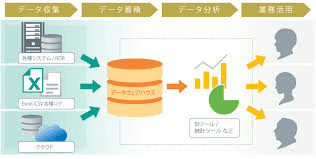
左側が会社内の様々な組織で利用されるシステムやデータと捉えてください。そしてこれらのデータをデータウェアハウスと書かれたオレンジのドラム缶に蓄積しています。このように社内の様々なデータを1箇所に集め、社内のあらゆるデータの分析を行えるようにする動きが昨今活発なっています。このオレンジのドラム缶に当たる、データの置き場所にクラウド基盤を利用するケースが増えてきています。
クラウド基盤の問題点
クラウドは冒頭でも述べた通り、様々なデータを格納できるだけの十分なリソースを持ったデータベースを、自分たちで一から設計せず利用することができます。
一方で、あまりに様々なデータを格納できるがゆえに、蓄積するデータがますます増えていき、整理ができずに活用できなくなるといった問題点もあります。
例えば、以下のようによく似たテーブルが複数のシステムに存在する場合です。

これらのテーブルをクラウド基盤上(データの置き場所)に連携する際、
1つのテーブルにまとめるべきか?
1つのテーブルにまとめるとしてもそれぞれで管理している項目をどこまで連携するか?
またそれぞれのシステムが持つ、同じような項目をどこまで統合・標準化するのか?
というように様々なデータを管理できるが故、上記のような問題に突き当たる方も昨今多く見受けられます。
クラウド基盤に最適なデータモデル:Data vault
このような状況に対応するため、注目されているのが、”Data Vault”という考え方です。
Data Vaultとは2000年代ごろにDan Linstedt氏が提唱したデータモデリングの技法の1つです。
Data Vaultのモデリングは3つの主要なコンポーネントに基づいています:
Hub:ビジネスキーとなる項目を保持する。
Link:Hub間のリレーションシップを表す。
Satellite:HubまたはLinkの詳細項目を保持する。

このようにHub、Link、Sateliteと3つのテーブルに分けるとどのようなメリットがあるのでしょうか。
それは、元のソースシステム情報を維持しつつ、利活用ニーズに合わせて柔軟に対応できる点にあります。

例えば先ほどの顧客やカスタマーテーブルの場合上記のように管理すると想定されます。
2つのテーブルをIDでの紐づけ管理を行い、その他ソースシステムの属性はそれぞれのSatelliteで管理するような形です(もちろん2つのテーブルで管理される値の粒度が同じかどうかは確認する必要がありますが)。
このような形で保持することで例えば下記のように持たせることもできます。

このように取引先 Satelliteで、ビジネス上よく利用する項目や、標準化したい項目を管理する。(データを分析する際はこのSateliteを見に行く)
一方、その他ソースシステム固有と思われる項目も今後のデータ利活用ニーズに合わせて持たせておく。
こうすることで、完全にテーブルを統合・標準化せずともデータ利活用に最低限の形でクラウド基盤上にデータを持つことが可能になります。
最後に
今回は少しややこしい話を駆け足で話してしまいました。少し反省です。
次回以降はこのData Vaultをより理解していただくため、データウェアハウスのアーキテクチャの考え方や、データモデリングとはそもそも何か?について解説したいと思います!
今回の記事が少しでもお役に立てば幸いです。それでは!