GPTの日本語とトークンの関係

トークンとはテキストを表現するための最小単位の要素として捉えられます。
GPTのトークン数をチェックできるサイトでテキストを書き込んで検証してみましょう。
英語の場合だと、アルファベット単位だけでなく、単語単位でトークンが準備されており、以下の形ではテキスト数はトークン数よりも少ないです。
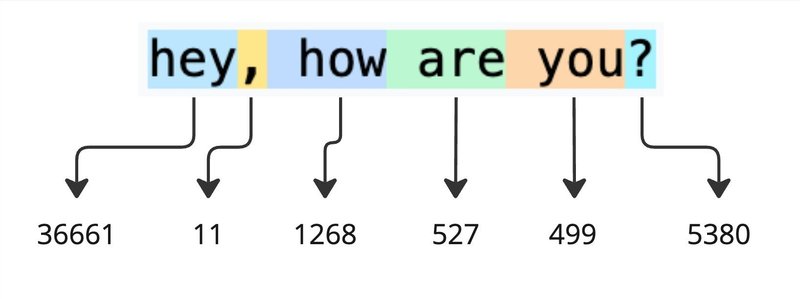
"hey"のトークンのインデックスは36661だが、アルファベット単位で見てみると
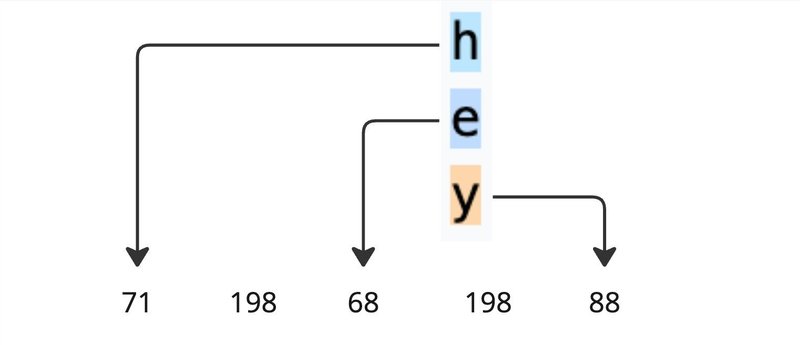
"h"は71、"e"は68、"y"は88と個々のトークンが存在します。(ちなみに、198は改行のトークン)
基礎の要素を組み合わせて、新しいテキスト表現("hey")にトークンが振り当てられているのがわかります。学習データの中に頻繁に出現するトークンペアを合わせて新しいトークンを作るプロセスをByte Pair Encodingとして知られています。
次に、
「島」と書いてみると…
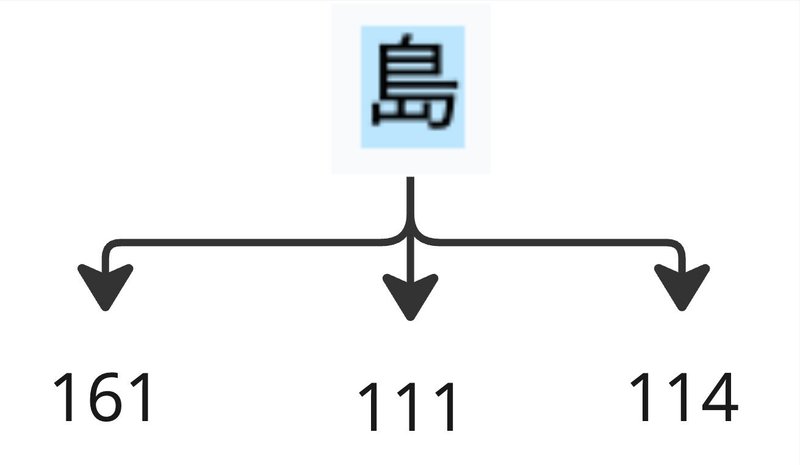
三つのトークンで表現されています。この三つのトークンは161、111、114として与えられています。1テキストに対して3トークンを消費する必要があり、この例に限らず日本語ではテキスト数よりもトークン数が多い傾向があります。これはトークンを組み合わせて漢字を表現しているためです
GPTでは入力・出力するトークン数に制限があるため、トークンをあまり消費しない英語ではより多くの情報を含めることができます。感覚的に、日本語よりも英語はトークンの空間で密度が高いと捉えることができます。
では、日本語でも単語単位でトークンを準備したらいいのでは?と思いますが、日本語だけでも語彙数は数十万とあり、トークンの数が膨れ上がってしまいます。トークンの数が増えてしまうと、モデルの規模が大きくなってしまい、学習過程で調整するパラメータの数が増えてしまい、学習時間のコストが膨大になる可能性があります。
よって、トークンを組み合わせて、様々なテキストを表現することが現実的なアプローチになります。
トークンの作り方と学習データでモデルのパフォーマンスに大きな影響を与えています。地味なところだけど、大切なところであるため、今後もっと触れていきたいです。
この記事が気に入ったらサポートをしてみませんか?