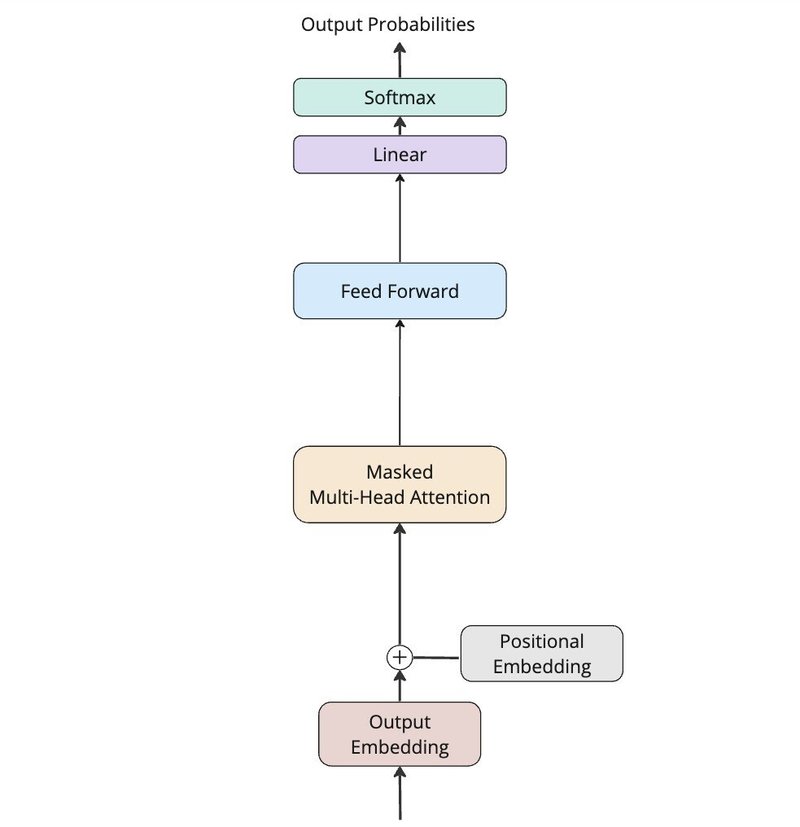
Transformerのデコーダーモデル解説

はじめに
Transformerは、2017年にGoogleの研究チーム、Ashish Vaswani氏らによって「Attention Is All You Need」という論文で初めて紹介されました。この研究では、機械翻訳に焦点を当て、従来のモデルを上回る成果を発表しています。このモデルは、翻訳対象のテキストを分析するエンコーダーと、翻訳文を生成するデコーダー、この二つの部分で構成されています。エンコーダーから受け取った情報を基に、デコーダーは一連の単語を生成していきます。この生成過程では、前に出た単語を参照しながら次々と新しい単語を加えていくことで、文が形成されていきます。
GPT(Generative Pretrained Transformer)は、Transformerのデコーダー部分のみを利用した構造を採用しています。デコーダー単体でも多様なタスクを実行可能であることが広く認識されています。
本記事では、デコーダーの仕組みを説明していきます。また、各要素がモデルにどのような効果を与えるかを、数値データを交えながら検証していきます。今回は英語のデータのみ活用しトークンはアルファベット、数字、記号の単位をしています。トークナイズのプロセスを簡易化することで、デコーダーのアーキテクチャの議論に早い段階で入ることができます。トークナイズの違いがモデルの性能に大きな影響を与えますが、今回はトークナイズのアプローチを一つに絞り、モデルの構造の変更に焦点を当てます。
デコーダーモデルの入力と出力
「私の好きな食べ物はスイカです。」をデコーダーが生成する様子をみてみましょう。
以下ではデコーダーへ入力したテキストを入力、そしてデコーダーから次のテキストが出力される例です。
-----------------------------
入力:私
出力:の
-----------------------------
入力:私の
出力:好き
-----------------------------
入力:私の好き
出力:な
-----------------------------
入力:私の好きな
出力:食べ物
-----------------------------
入力:私の好きな食べ物
出力:は
-----------------------------
入力:私の好きな食べ物は
出力:スイカ
-----------------------------
入力:私の好きな食べ物はスイカ
出力:です
-----------------------------
入力:私の好きな食べ物はスイカです
出力:。
トークンとは、上記の場合だと
「私」「の」「好き」「な」「食べ物」「は」「スイカ」「です」「。」
であり、テキストデータをモデルが扱いやすい形式に分割したものを指します。
本記事で行う実験では英語のデータ(シェイクスピアのテキストデータ)で一意となるアルファベット、数字、記号をトークンとします。
アルファベット単位の場合は以下のような形でトークンを生成していきます。
-----------------------------
入力:'I'
出力:' '
-----------------------------
入力:'I '
出力:'a'
-----------------------------
入力:'I a'
出力:'m'
-----------------------------
入力:'I am'
出力:' '
-----------------------------
入力:'I am '
出力:'f'
-----------------------------
入力:'I am f'
出力:'i'
-----------------------------
入力:'I am fi'
出力:'n'
-----------------------------
入力:'I am fin'
出力:'e'
デコーダーのアーキテクチャ全体像
論文「Attention Is All You Need」のデコーダーの部分を書いてみましょう。
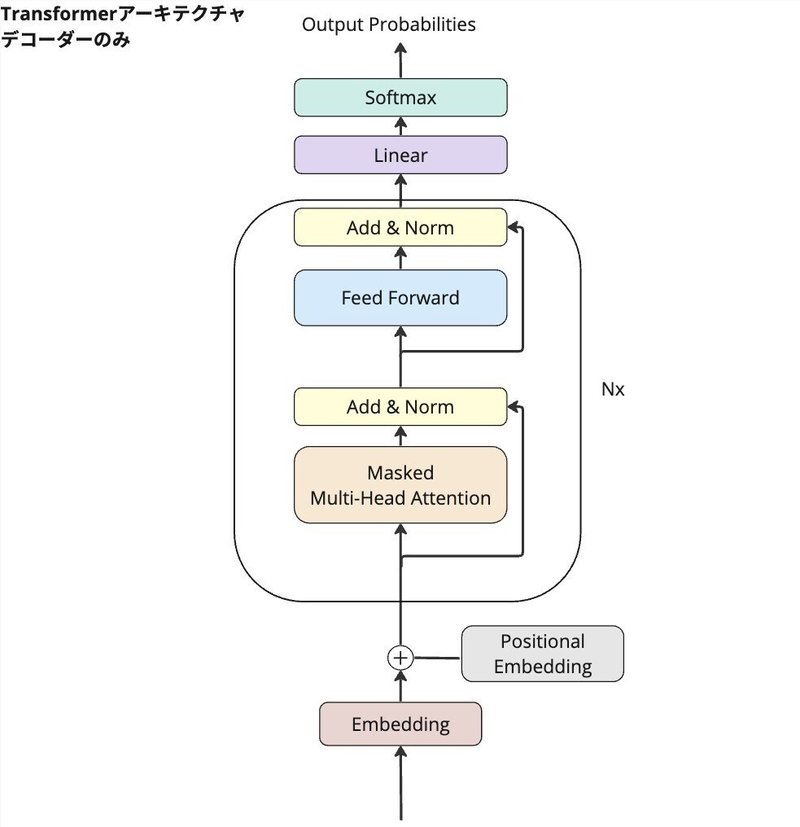
以下それぞれの要素から成り立っており、次のセクションで個々の要素の役割を見ていきましょう。
Embedding (単語埋め込み)
Positional Embedding(位置埋め込み)
Masked Multi-Head Attention(マスク付きマルチヘッドアテンション)
Feed Forward(フィードフォワード)
Skip Connection(スキップ接続)
Layer Norm(レイヤー正規化)
Embedding(単語埋め込み)
トークンをベクトル表現で保持しており、以下の行列で表現します。
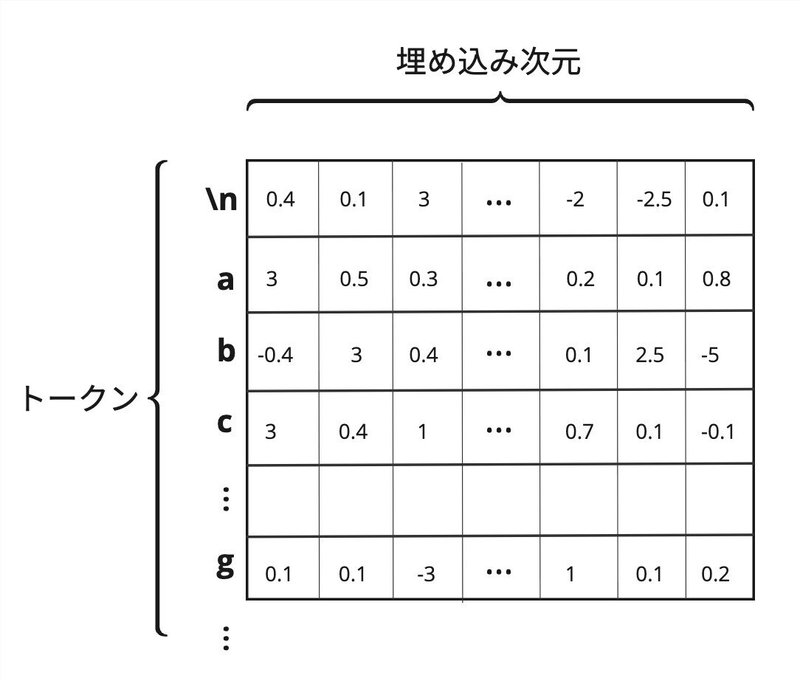
各行はトークンをベクトルで表現したものであり、行数はトークン数と一致しています。
列はベクトルの次元を示しており、列数はベクトルの次元数と一致しています。埋め込み次元数の設定はトークン数や計算量、またモデルの複雑性などを考慮して決める必要があります。
行列内のパラメータは学習のプロセスで調整されます。
入力から出力までのデータ構造
単語埋め込みの層にはトークンが入力され、トークンのベクトル表現が出力されます。
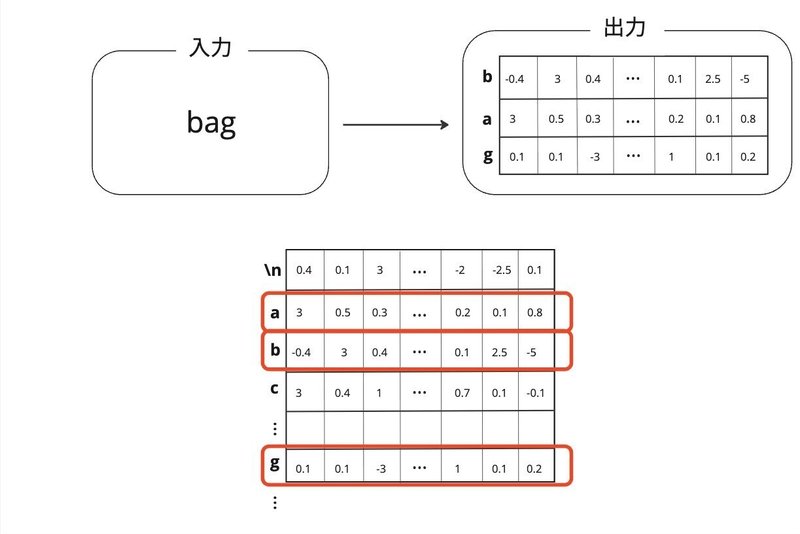
上の例だと、
入力が「bag」、出力は「b」「a」「g」それぞれのトークンのベクトルが出力されます。
EmbedLinearSoftモデル
単語埋め込みを用いてシンプルなモデルを構築します。このモデルを出発点として、他の要素を加えることで、どの程度改善されるか検証をしていきます。以下のLinearは全結合層を示しています。
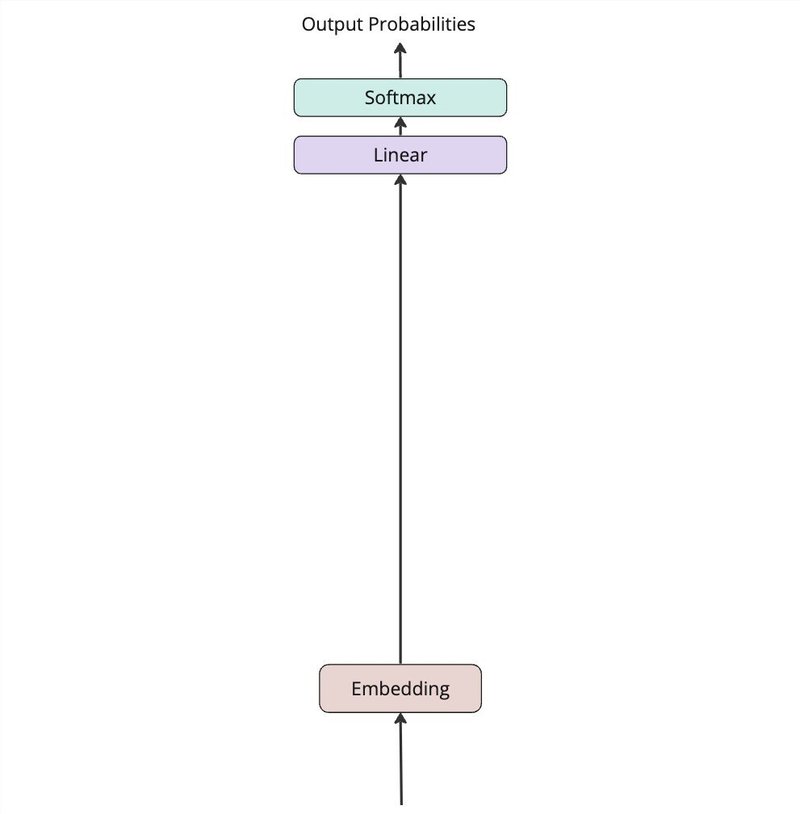
入力から出力までのデータ構造
Embedding(単語埋め込み)にトークンが入力、ベクトルが出力されます。
Linear(全結合層)にベクトルが入力、同じくベクトルが出力されますが、出力ベクトルの要素数は全トークン数(or クラス数)と一致します。各トークンの出現確率を予測するためのスコアを生成します。
最後に、スコアはSoftmaxで確率分布に変換され、次に生成するトークンを選択する役割を担います。
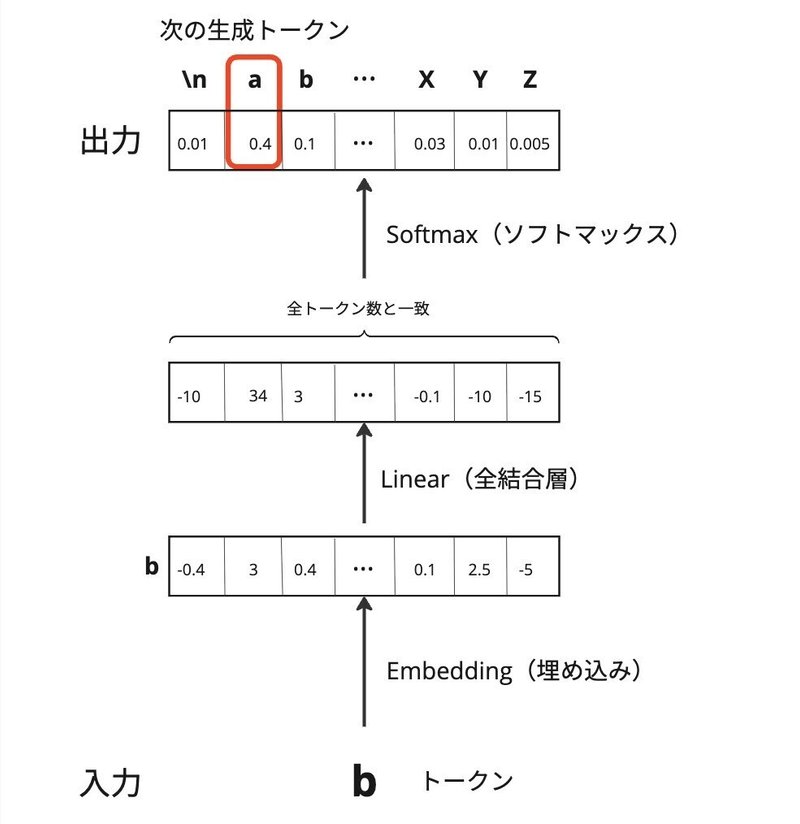
EmbedLinearSoftモデルの特徴として一つのトークンだけを基に、次のトークンを生成しています。
学習のプロセス
EmbedLinearSoftモデルでは、Embedding(埋め込み層)とLinear(全結合層)に含まれるパラメータを適切に調整する必要があります。パラメータの調整は教師ありデータの正解データに近い出力を出せるようにしたいため、予測と正解データを測る損失関数が小さくなるようにパラメータの調整を行います。
ここで使う損失関数はCross Entropy(交差エントロピー)であり、二つの確率分布間の差異を測定するためによく使用される指標です。
$${ \text{交差エントロピー}= -\sum_j^N p_j \log(q_j) }$$
$${p_j}$$は正解、$${q_j}$$は予測の確率分布を示します。$${N}$$は全トークン数(クラス数)を示します。
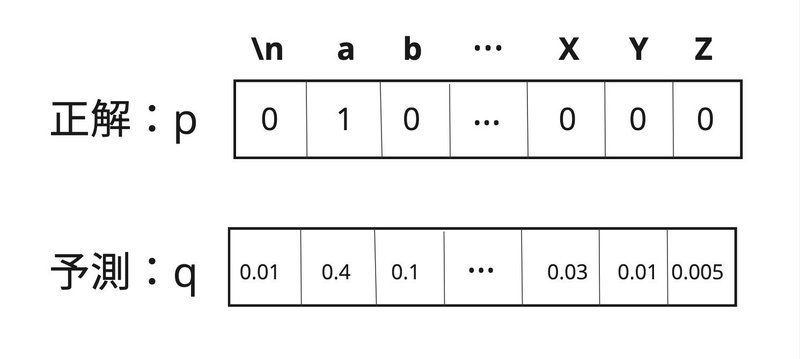
上記の例だと、
「a」の正解確率が1であり、その予測確率が0.4であるため、交差エントロピーは
$${ \text{交差エントロピー}= - \log(0.4)}$$
のかたちになり、予測確率が正解確率(この場合は1)に近いほど、交差エントロピーの値は小さくなります。
全てのデータに対して交差エントロピーを計算した合計を最小化しようとすると計算量が膨大になってしまいます。そのため全データセットからランダムに選択された小さなサブセット(バッチ)をとり、それぞれのバッチに対して交差エントロピーの最小化を行います。
$${ \text{バッチの交差エントロピー}= -\frac{1}{M}\sum_{m=1}^M\sum_{j=1}^Np_{j, m} \log(q_{j,m}) }$$
$${M}$$はバッチに含むサンプル数を示します。$${N}$$は全トークン数(クラス数)を示します。
本記事で紹介する実験では上記の学習プロセスを一貫して用いていきます。
EmbedLinearSoftモデルの検証
以下の次元数を設定します。
全トークン数:65(データに含まれるアルファベット・数字・記号の数)
単語埋め込みの次元:384
モデルが持つパラメータ数を見てみましょう。
埋め込み層のパラメータ数:$${65 \times 384 = 24960}$$
全結合層のパラメータ数(バイアス付き):$${65 \times 384 + 65= 25025}$$
合計が49985個のパラメータを持ちます。
以下はEmbedLinearSoftモデルの検証結果になります。パラメータの更新過程で500回毎に損失関数の値を載せています。
step 0: train loss 4.2763, val loss 4.2762
step 500: train loss 2.4758, val loss 2.5064
step 1000: train loss 2.4604, val loss 2.4885
step 1500: train loss 2.4580, val loss 2.4870
step 2000: train loss 2.4542, val loss 2.4834
step 2500: train loss 2.4548, val loss 2.4873検証用のデータに対する損失関数が2.4873となります。(以降は数値が改善しませんでした。)
上記の精度でどの程度良いか検証するため、学習されたモデルを用いてテキストを生成します。以下が「\n」から始めて逐次的に生成した結果です。
STHond r;
Tonsse
I's.
Yost
Hon; ngersu g.
st Inth, s who th we f arer, y, dingade ONIt s asoomy.
Mem t arise tur s we thashindis oveouthis'sthanetour, us ady pofonst vo n, liazofathoripooumarathimoisesior alomy, athat woroumeay ld, g he.
O,-msowiam nc ole owes Fis s ar geace byod on ananchere'ldigeces et'diond o, itonolt tol whe ghaderd t, d r methethade slith athas br: avereldo fomeadeite s inoyowetot, SSanorsthind t mes
I we tom d geles hict
Thinedird asin be gicalicoublvavery, ll the I pestokiclll qures le tongiver:
MERoueryelepon whizeaur woer lougeyousoreld omispl I y kep:
O: ct anour:
Se g-est hor fedore.
ANG che onet:英語とは程遠い感じですが、スペースを入れるタイミングはなんとなくできているように感じられます。
Masked Multi-Head Attention(マスク付きマルチヘッドアテンション)
アテンションメカニズムを用いたモデルでは、前の複数のトークンからどのトークンに重きを置くべきか認識して次のトークンを生成します。
以下の未完の文を考えてみます。
「さっきご飯を食べたので今はお腹が空いて」
文脈から「お腹が空いていない」と理解することができますが、「いない」と判断するためには、全体の文脈の情報が必要になります。
マスク付きアテンションとは
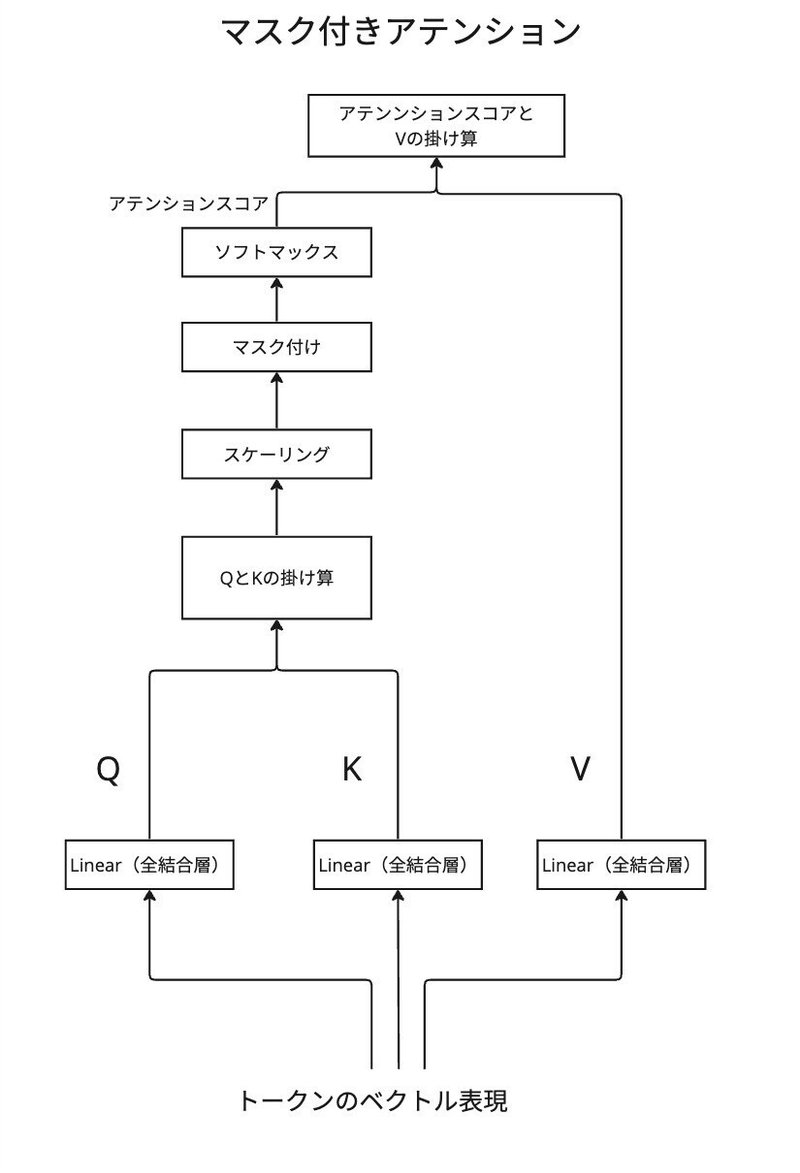
アテンションメカニズムではトークン間の関係性を示す行列(アテンションスコア)を作成します。
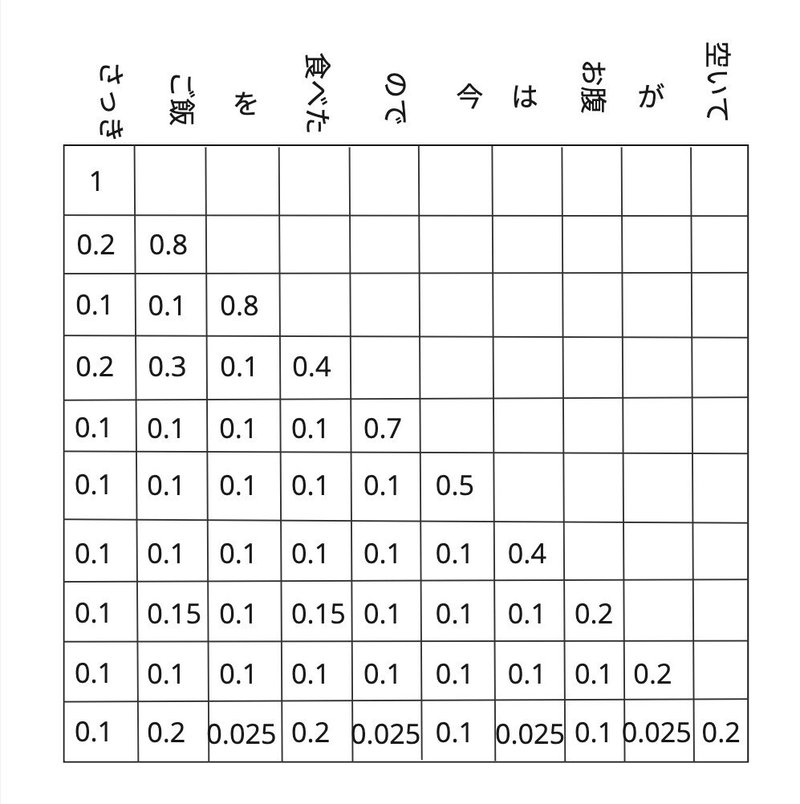
上記のアテンションスコアは未来のトークンに対するウェイトを0として、未来の情報にアクセスできないようにします。これをマスク付きアテンションと言います。行列の6行目は以下を示しています。
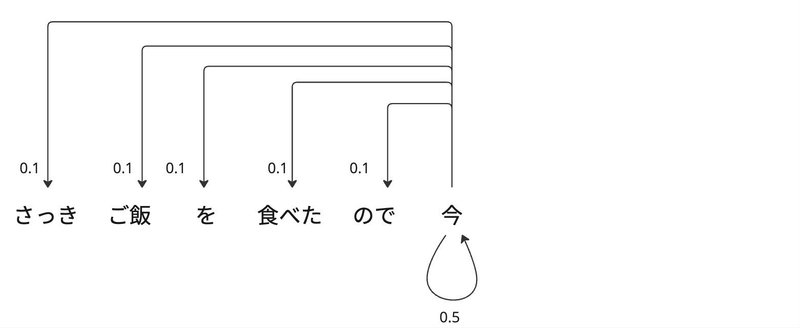
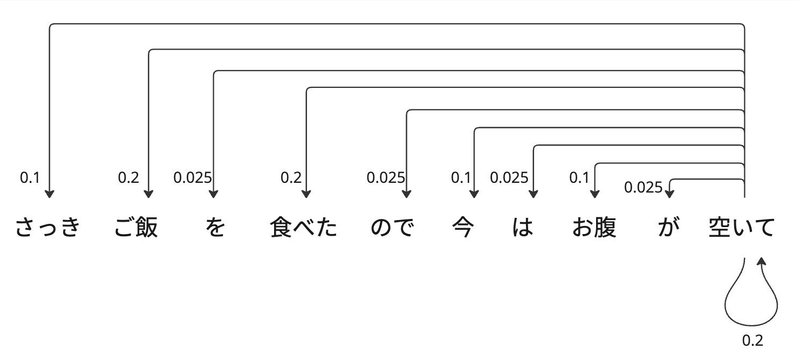
行列の最後の行は以下を示しています。
アテンションスコアの計算
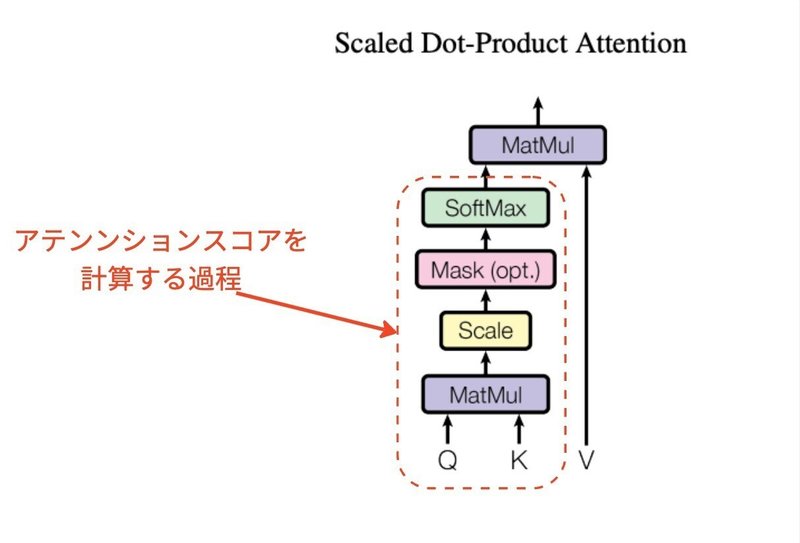
アテンションスコアを計算する際、2つの行列Q(クエリ)とK(キー)が用いられます。
Q (クエリ)はトークンが何を探しているのか、K (キー)は各トークンがどのような情報を持っているかを示します。
Qが求める情報をKが持つ場合、アテンションスコアが高くなります。
二つの行列の積を取ることにより、トークン間の関係性を示す行列を得ることができます。
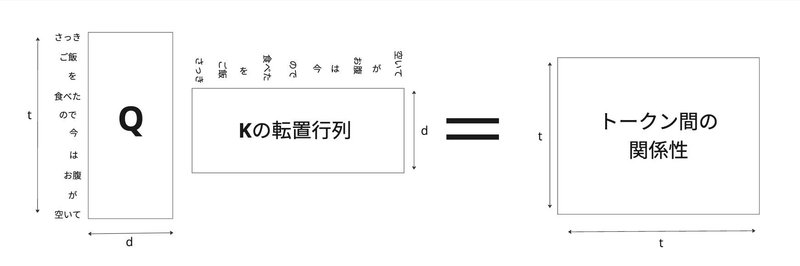
関係性を示す行列の各要素に$${\sqrt{d}}$$で割る処理もおこないます。これは、次元が大きくなると積の結果が非常に大きくなりがちで、後に行うSoftmax関数の勾配が極端に小さくなることを避けるためです。
マスク付きアテンションの場合は、未来のトークンへのアクセスをブロックするために、対角上よりも上三角の部分をマスクします。
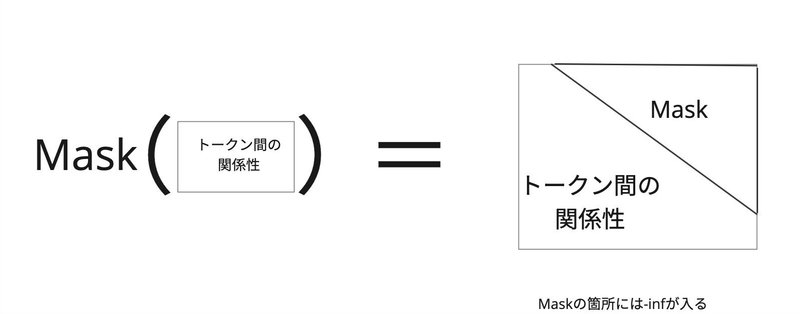
アテンションスコアを得るためにSoftmaxを使い正規化を行います。Maskの各要素は-infであるため、Softmaxを通すと0の値になります。
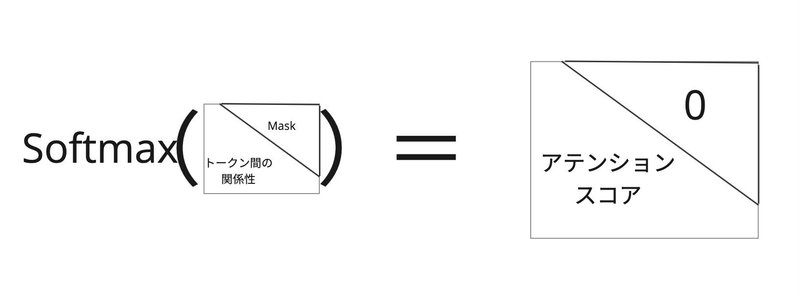
アテンションスコアから過去のトークンにどの程度注意を払うべきか
決めることになります。前のトークンの重み付けとなり、合計の和をとる処理を行います。ここでは行列V(バリュー)に対して行い、行列Vはトークンの具体的な情報を含み、アテンションスコアに基づいて適切に重み付けされた後、集約された新しい表現を形成します。
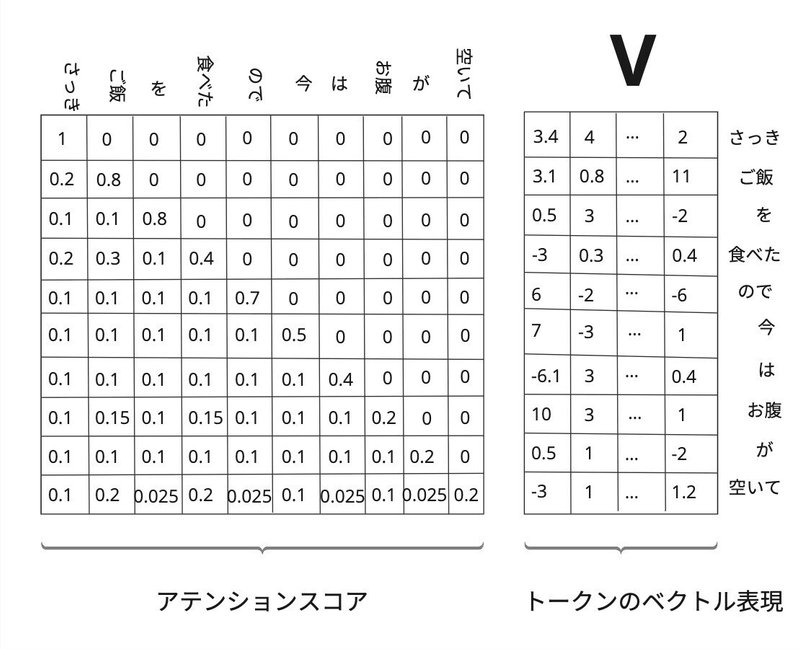
「空いて」の箇所だけ切り取ってみてみると
$${「空いて」の新しいベクトル表現 = 0.2\times空いて + 0.025\timesが + 0.1\timesお腹 + \cdots + 0.2 \timesご飯 + 0.1\times さっき }$$
のようにアテンションスコアを掛けて、トークンのベクトル表現を足し合わせています。
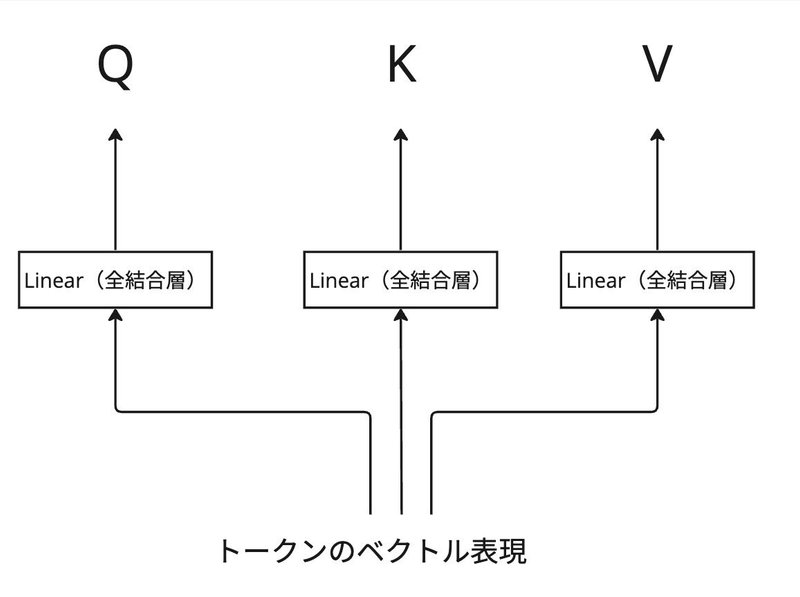
Q, K, Vはどのように作成されるか
Q(クエリ)、K(キー)、V(バリュー)のイメージは
Q:トークンが何を探しているのか
K:各トークンがどのような情報を持っているか
V:トークンの具体的な情報
として説明しました。
Q、K、Vを得るために、前処理の変換を行うステップがあります。この変換の処理は、トークンのベクトル表現が全結合層を通ることで行われます。それぞれの全結合層が異なるパラメータ(重みとバイアス)を持ち、同じトークンのベクトル表現から異なる役割を持つQ、K、Vが生成されます。学習プロセスで全結合層のパラメータを調整して、適切なQ、K、Vに変換される流れになります。
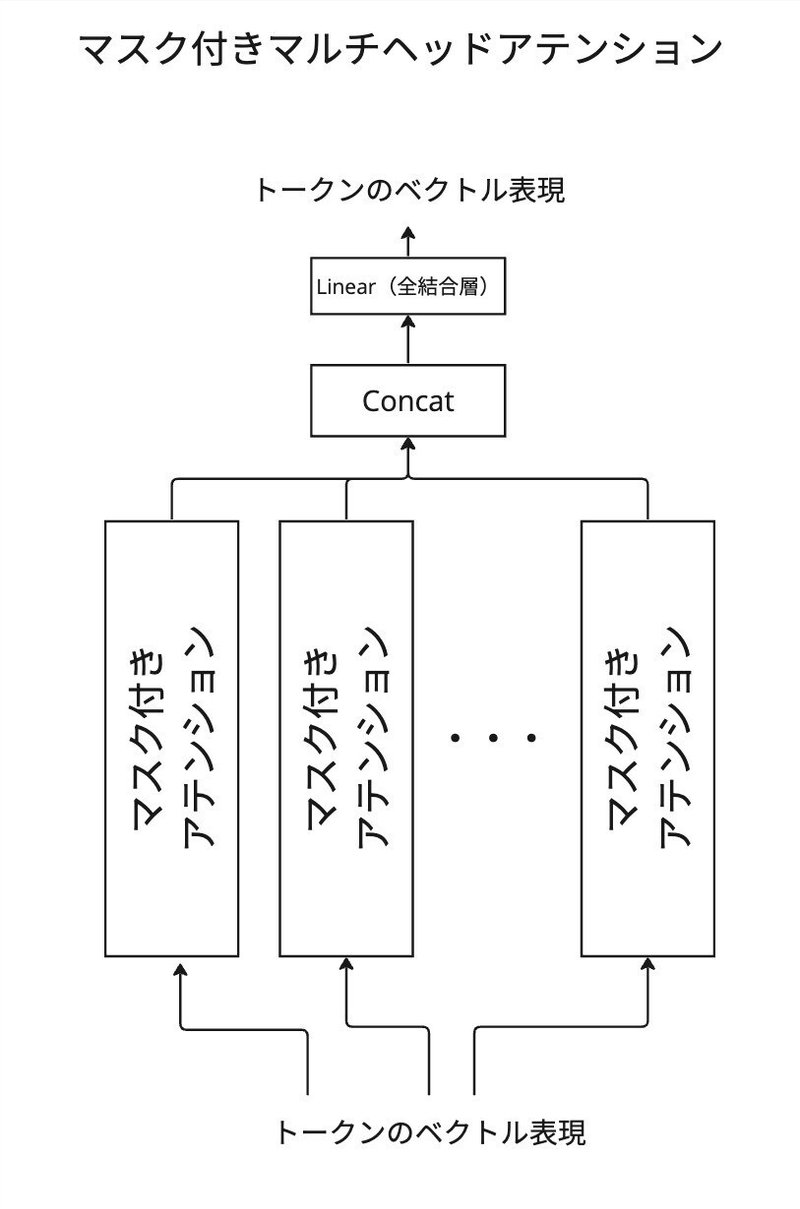
マルチヘッドアテンションとは
これまでの説明をまとめると、アテンションの計算の流れが以下の形になります。
マルチヘッドの場合は、上記のアテンションの計算が複数平行して行われ、それらの結果を結合します。異なる特徴を基に重要度が計算される仕組みと捉えることができます。例えば、あるヘッドは文法的な関係に注目し、別のヘッドは意味的な関係に注目することができます。実際ではヘッドが注目する特徴は事後的に観察され、抽象的なものであることが多いです。
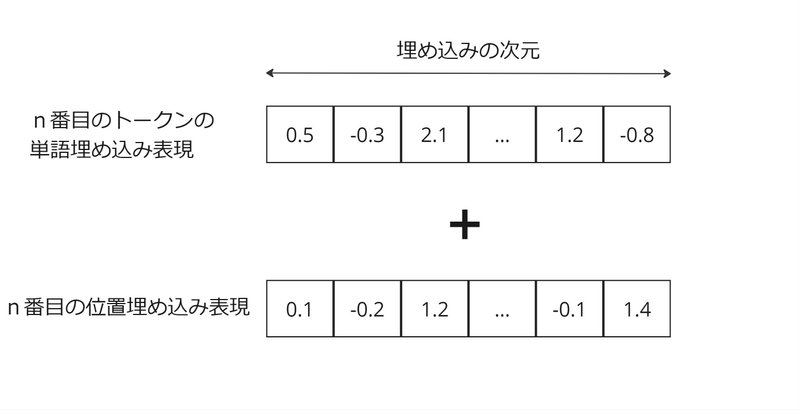
Positional Embedding(位置埋め込み)
Positional Embedding(位置埋め込み)はトークンの位置情報を保持します。
これまでの設計に位置を記録する仕組みがなく、Embedding(単語埋め込み)とアテンションメカニズム自体には順序を考慮する仕組みを持っていません。
アテンションの技術はトークンのベクトル表現から情報を抽出して処理する能力であり、この力を発揮するためには、トークンのベクトル表現自体に有効な情報を事前に含める必要があります。
位置の情報を入れ込むために、Positional Embedding(位置埋め込み)とPositional Encoding(位置エンコーディング)と呼ばれるものがあり、異なる点は学習する必要があるかどうかになります。位置埋め込みはパラメータを学習する必要があり、位置エンコーディングは事前に定義された関数を使用して生成されます。
具体的な計算を見てみましょう。
以下のように、単語埋め込みのベクトルと同じ次元を持つベクトルを足し合わせることにより、生成されるベクトルが位置情報を含むようになります。
上記のやり方とは別に、もう一つの要素を加えて、単純に順序の数を含めてしまうと、順番が大きいときにその要素だけ大きい値になってしまい、過度にその位置情報に重みを与えてしまいます。
もう一つのシンプルなやり方として、one-hotがありますが、次元が無駄に増えてしまい密度が薄いスパースな表現になってしまいます。
上記の位置埋め込みまたは位置エンコーディングでは、要素の数と値が大きくなるデメリットが生じません。
ContextAwareSeqNetモデル
EmbedLinearSoftモデルにマスク付きアテンションと位置埋め込みを導入して検証してみます。
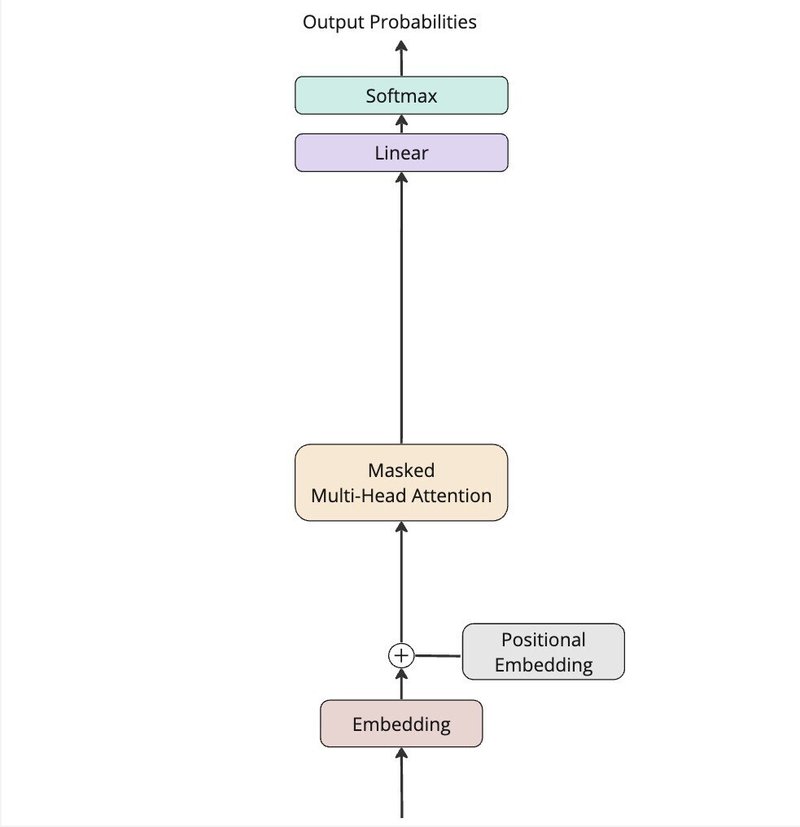
検証1:ヘッドが1つの場合
以下の次元数を設定します。
全トークン数:65(データに含まれるアルファベット・数字・記号の数)
単語埋め込みの次元:384
アテンションの最大トークン数:256
ヘッドの数:1
Q、K、Vの次元:384
EmbedLinearSoftモデルにアテンションと位置埋め込みを加えたため、以下のパラメータ数が増えます。
位置埋め込み層:$${256 \times 384 = 98304}$$
マスク付きアテンション:
$${384 \times 384 + 384 \times 384 + 384 \times 384= 294912}$$
合計が443201個のパラメータを持ちます。
前のモデルに比べると、損失関数の値がより低くなっています。
step 0: train loss 4.1853, val loss 4.1848
step 500: train loss 2.5359, val loss 2.5459
step 1000: train loss 2.4035, val loss 2.4280
step 1500: train loss 2.3404, val loss 2.3776
step 2000: train loss 2.3124, val loss 2.3538
step 2500: train loss 2.2955, val loss 2.3394
step 3000: train loss 2.2820, val loss 2.3325
step 3500: train loss 2.2672, val loss 2.3201
step 4000: train loss 2.2585, val loss 2.3163
step 4500: train loss 2.2563, val loss 2.3155
step 5000: train loss 2.2550, val loss 2.3109
step 5500: train loss 2.2509, val loss 2.3103
step 6000: train loss 2.2477, val loss 2.3137
step 6500: train loss 2.2441, val loss 2.3053Sow mI omuonedamnorf I cen offrorud t forieidn ipreve cayeethe stewe th wshit frok wn,
Fifr yex't wovearsthiys: ches novenagley Tou ters is lond nto coare wobrece boulsonog hteno at.
QUEEVIN RENTENCE:
Thee oo nonther lald, ieve mid them wo fot! Ger bin thantis picke-o-rce
we frnidess. Ah mo scechin gies.
OProut y lblat wnom pel thonce'ss
Froun
Noush har wechatim.
Lok, the the id the thr tesacelo ed wa wet?
ardo hud atin hbee;
Fris domeniqueredrucod are til, brushe
Fer basr?
もしPositional Embedding (位置埋め込み)を入れなかったらどうなるのですよう。
やってみましょう。以下の結果は位置埋め込みを含めずに学習した結果です。
検証2:位置埋め込みを除いてみる
位置情報がどの程度影響を持つか検証をするため、位置埋め込みを除いてみます。パラメータの数は位置埋め込みを除くのみなので、合計が344897個を持ちます。
step 0: train loss 4.1738, val loss 4.1737
step 500: train loss 2.5535, val loss 2.5648
step 1000: train loss 2.5146, val loss 2.5310
step 1500: train loss 2.5009, val loss 2.5257
step 2000: train loss 2.4863, val loss 2.5154
step 2500: train loss 2.4781, val loss 2.5141
step 3000: train loss 2.4715, val loss 2.5089
step 3500: train loss 2.4675, val loss 2.5043
step 4000: train loss 2.4636, val loss 2.5062
step 4500: train loss 2.4633, val loss 2.5045
step 5000: train loss 2.4580, val loss 2.5022
step 5500: train loss 2.4496, val loss 2.4957
step 6000: train loss 2.4494, val loss 2.4946
step 6500: train loss 2.4478, val loss 2.4952
step 7000: train loss 2.4448, val loss 2.4935
step 7500: train loss 2.4403, val loss 2.4930
step 8000: train loss 2.4402, val loss 2.4835上記の結果だと最初のEmbedLinearSoftモデルと損失関数の値はそこまで変わりません。今回の場合では、位置埋め込みがなけれな、アテンションメカニズムを含めても効果がそこまでないことがわかります。
検証3:ヘッド数を6にする
次は位置埋め込みを含めて、アテンションのヘッド数を増やして試してみます。Q, K, Vの次元は384をヘッド数で割った数にします。
ヘッドの数:6
Q、K、Vの次元:64
上記の設定だと、ヘッド数を1にした場合に比べて、アテンションの箇所のパラメータ数は変わりません。複数のヘッドからの出力を合体して、全結合層に通す過程があるので、この全結合層のパラメータ数を考慮すると。アテンションの箇所のパラメータ数は295296個になります。
合計で591041個のパラメータを持ちます。
step 0: train loss 4.1628, val loss 4.1623
step 500: train loss 2.4497, val loss 2.4677
step 1000: train loss 2.2292, val loss 2.2691
step 1500: train loss 2.0846, val loss 2.1590
step 2000: train loss 1.9903, val loss 2.0887
step 2500: train loss 1.9367, val loss 2.0533
step 3000: train loss 1.9073, val loss 2.0360
step 3500: train loss 1.8867, val loss 2.0171
step 4000: train loss 1.8731, val loss 2.0094
step 4500: train loss 1.8586, val loss 1.9937
step 5000: train loss 1.8477, val loss 1.9821
step 5500: train loss 1.8409, val loss 1.9788
step 6000: train loss 1.8368, val loss 1.9785
step 6500: train loss 1.8311, val loss 1.9736
step 7000: train loss 1.8267, val loss 1.9672
step 7500: train loss 1.8189, val loss 1.9639
step 8000: train loss 1.8157, val loss 1.9591
step 8500: train loss 1.8141, val loss 1.9577
step 9000: train loss 1.8066, val loss 1.9514
step 9500: train loss 1.8044, val loss 1.9496
step 9999: train loss 1.8040, val loss 1.9456損失の値が著しく良くなっています。
生成結果も人が会話をしている様子を再現でき始めています。
LIXENED:
Firfan?
The vadil enting
Ghounceind ave have as ale
ye and speshay fall with coul!
GLOUCEE:
Morsenfatet whal of fa, but-son mother.
WARWICK:
I chave's booldroppe cquarthing.
ROMEO:
I I woul:
GAN ELIZABELLABY:
Come theer:
I'll you.
KING HENRENCE:
Yeak.
SSTIO:
Corit hor thal, I'll fearm ford, his in tred.
Hincound.ContextAwareSeqNet2モデル
続けて前回のContextAwareSeqNetモデルにFeed Forwardを含めたモデルを考えていきます。
Feed Forwardは以下の形になっています
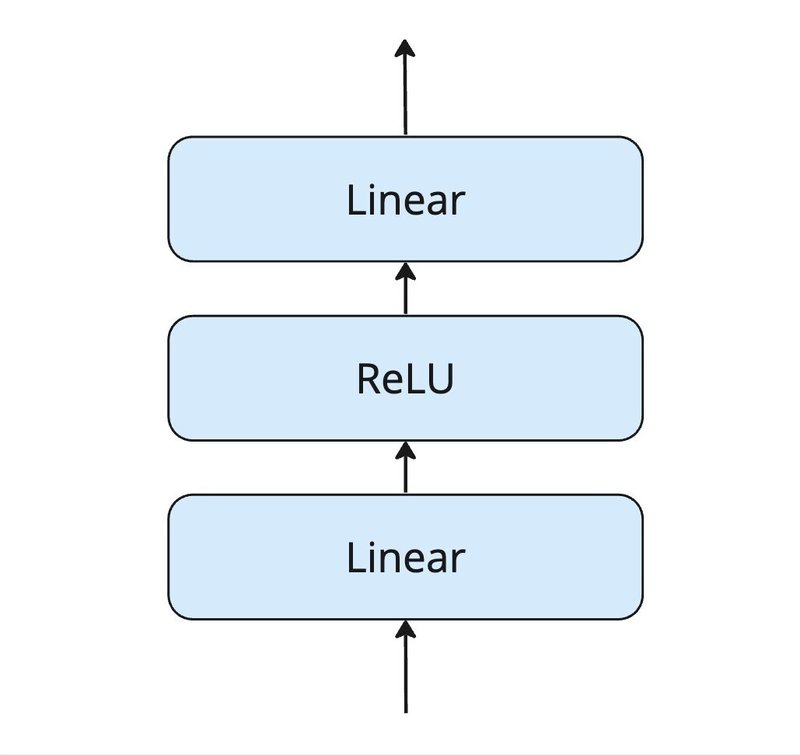
全結合層の間に活性化関数のReLU層を挟むかたちになります。ReLUはマイナスの値を0に変換する処理を行います。そのため、不要な情報を取り除くことができ、ネットワークがより重要な特徴に焦点を合わせることができるようになります。
論文「Attention is all you need」では、一番目のLinear層はベクトルを4倍のサイズに変換して、二番目のLinear層で元のサイズに変換します。ReLU層はベクトルが4倍のサイズの時に処理を行います。
論文ではなぜ一番目のLinear層でサイズを大きくしてReLU層を通す処理をおこなったのでしょうか。ベクトルのサイズが増えると情報がより細かく分解され、取り除くべき情報が分かりやすい状態になるため、ReLU層での除去がより的確に行えます。そして二番目のLinear層で元のサイズに縮小する処理を行います。
検証1:ReLUを含める場合
Feed Forward層では埋め込みの次元を4倍に拡張するので、非常に多くのパラメータを持ちます。
Feed Forwardのパラメータ数(全結合層はバイアス付き):
$${384 \times 1536 + 1536 + 384 \times 1536 + 384= 1181568}$$
ContextAwareSeqNetモデルの検証3のパラメータ数と足し合わせると、合計1772609個になります。
step 0: train loss 4.1635, val loss 4.1639
step 500: train loss 2.4082, val loss 2.4250
step 1000: train loss 1.9720, val loss 2.0664
step 1500: train loss 1.7444, val loss 1.8949
step 2000: train loss 1.6333, val loss 1.8019
step 2500: train loss 1.5640, val loss 1.7466
step 3000: train loss 1.5223, val loss 1.7138
step 3500: train loss 1.4964, val loss 1.6829
step 4000: train loss 1.4702, val loss 1.6656
step 4500: train loss 1.4534, val loss 1.6495
step 5000: train loss 1.4399, val loss 1.6321
step 5500: train loss 1.4297, val loss 1.6424
step 6000: train loss 1.4209, val loss 1.6276
step 6500: train loss 1.4097, val loss 1.6147
step 7000: train loss 1.4023, val loss 1.6145
step 7500: train loss 1.3980, val loss 1.6125
step 8000: train loss 1.3906, val loss 1.6144
step 8500: train loss 1.3880, val loss 1.6061
step 9000: train loss 1.3805, val loss 1.6090
step 9500: train loss 1.3748, val loss 1.5963
step 9999: train loss 1.3686, val loss 1.5992前の検証に比べるとまた著しく改善がみられます。
IIII:n
I'll he fear marsh?
PON:
I carrel needy and in arm us sun
Upon refore answers hands, hands path ve say,
That the father otable preded your bland-tid's thee from his,
Withwick: thefror humbassises: but in up't beseep;
Forgive I recame thy cry han pripe; and
As I mighosternio's forth
Of resume
Unham anges nexed stolet. cafal vaust,
And her is in my me! But now her hander the peing bitian.
have love; like Merd sleep, not mine with kingine.
SICINIUS:
Resoo? Barn to burning lyie.
ROMENENIUS:
I will, place! I'll the trunk you?
Say, that Pitlinatrers, suid yet, will beat my lifname,
The know Roman's; and what rate beings the conjint
Wish alter'd lips, 'tis wevp, I
Have he shoked chung a perforsooted, straity broth chee erved your takesby.
Macius lords of its than strried blurd blood,より英語っぽく見えてきました。
次に、もしReLU層を含めなかったらどうなるか試してみましょう。
検証2:ReLUを含めない場合
step 0: train loss 4.1617, val loss 4.1619
step 500: train loss 2.4388, val loss 2.4530
step 1000: train loss 2.2131, val loss 2.2616
step 1500: train loss 2.0866, val loss 2.1608
step 2000: train loss 1.9995, val loss 2.0941
step 2500: train loss 1.9447, val loss 2.0490
step 3000: train loss 1.9153, val loss 2.0298
step 3500: train loss 1.8968, val loss 2.0103
step 4000: train loss 1.8826, val loss 2.0000
step 4500: train loss 1.8714, val loss 1.9942
step 5000: train loss 1.8627, val loss 1.9862
step 5500: train loss 1.8572, val loss 1.9949
step 6000: train loss 1.8533, val loss 1.9801
step 6500: train loss 1.8462, val loss 1.9743
step 7000: train loss 1.8388, val loss 1.9735
step 7500: train loss 1.8380, val loss 1.9715
step 8000: train loss 1.8342, val loss 1.9726
step 8500: train loss 1.8330, val loss 1.9673
step 9000: train loss 1.8307, val loss 1.9653
step 9500: train loss 1.8247, val loss 1.9609
step 9999: train loss 1.8211, val loss 1.9623結果が著しく悪くなっているのがわかります。しかも、ContextAwareSeqNextモデルの検証3よりも悪いです。Feed ForwardブロックではReLUが非常に有効であることがわかりました。
Skip Connection(スキップ接続)
次にスキップ接続を見てみましょう。
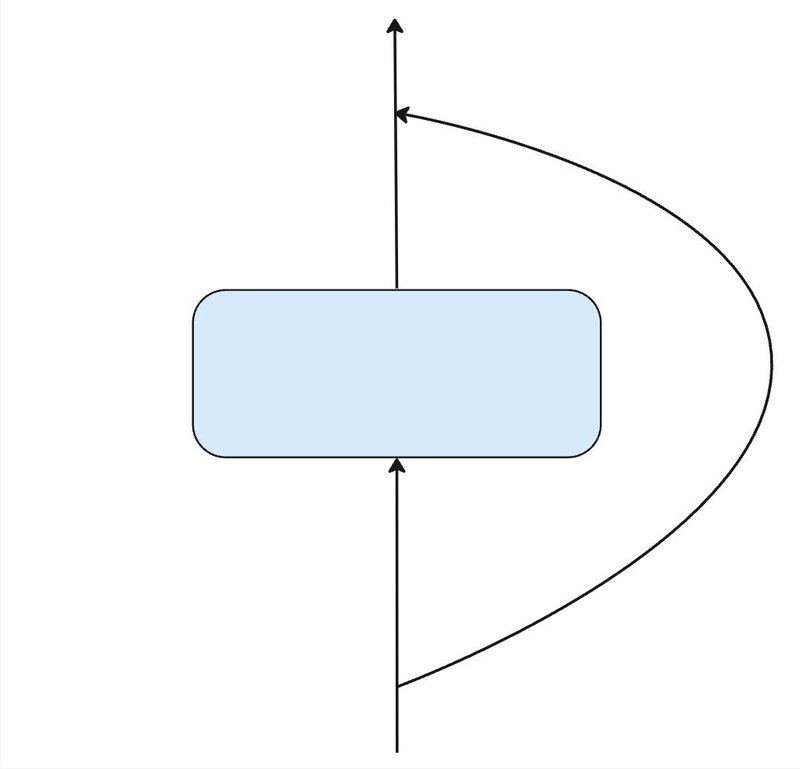
上のブロックに入力される前に、コピーを分岐させて、ブロックからの出力に足し合わせる処理を行います。
Pythonのコードでの挙動を説明します。
x = 10 # 入力値
z = x # 入力値のコピー
y = block(x) # xがブロックに入力され、yが出力されます
y = y + z # 最後にコピーとの足し合わせ上記のコードでは入力値=10としてますが、ニューラルネットでは複数の次元を持つ構造(多次元配列)になるので、入力のデータ構造とブロックから出力されるデータ構造が一致する必要があります。
スキップ接続の大きな利点は、ニューラルネットの学習時にあります。
スキップ接続を持たないニューラルネットでは、パラメータの調整を行うために勾配が計算されますが、出力層から離れた層の勾配を計算するため、その前の全ての層の勾配を乗算します。複数の勾配を乗算すると、勾配の消失が起こる可能性が十分にあります。小さい数を乗算すると消失が起きてしまい、勾配が小さいとパラメータの変化が微小になるので、学習のスピードがとても遅くなってしまいます。
一方で、スキップ接続を持つニューラルネットでは、ブロック部分とスキップ部分の二つのルートがあるため、ブロック部分で勾配が小さくなっても、スキップ部分を足し合わせて、勾配の消失を防ぎます。
TransNonNormDecoderモデル
ここではCotextAwareSeqNet2モデルのアテンションとFeed Forwardの箇所をブロックとして考え、このブロックが連結している構造を考えます。さらに、アテンションとFeed Forwardを避けるようにスキップ接続を加えています。正規化を行う層を含めていないので、TransNonNormDecoderと本記事では呼びます。
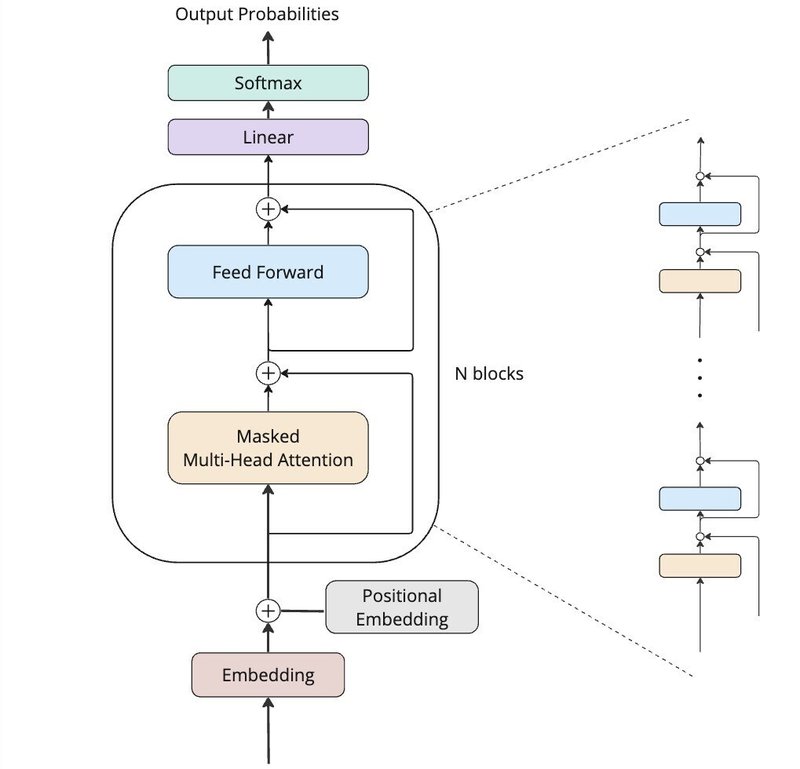
検証1:スキップ接続を含める場合
今回はブロックの数を3に設定します。Feed Forwardとアテンションのそれぞれのパラメータ数が1181568と295296であるため、3つブロックが並ぶ場合は
$${3 \times(1181568 + 295296) = 4430592}$$
個になります。
そして、合計は4578816個のパラメータを持つモデルにあります。
step 0: train loss 4.5767, val loss 4.5834
step 500: train loss 1.9754, val loss 2.0689
step 1000: train loss 1.6192, val loss 1.7795
step 1500: train loss 1.4786, val loss 1.6526
step 2000: train loss 1.4025, val loss 1.6100
step 2500: train loss 1.3501, val loss 1.5609
step 3000: train loss 1.3131, val loss 1.5389
step 3500: train loss 1.2800, val loss 1.5277
step 4000: train loss 1.2536, val loss 1.5077
step 4500: train loss 1.2380, val loss 1.5025
step 5000: train loss 1.2118, val loss 1.4959
step 5500: train loss 1.1961, val loss 1.4932
step 6000: train loss 1.1794, val loss 1.4866
step 6500: train loss 1.1606, val loss 1.4826
step 7000: train loss 1.1460, val loss 1.4748
step 7500: train loss 1.1342, val loss 1.4726
step 8000: train loss 1.1228, val loss 1.4729
step 8500: train loss 1.1056, val loss 1.4732
step 9000: train loss 1.0950, val loss 1.4746
step 9500: train loss 1.0801, val loss 1.4850
step 9999: train loss 1.0681, val loss 1.4814LEONTES:
Dove the so,
You have much good much retired.
Under that we would?
LEONTES:
Childiff, thoughts he not stand upon hand;
Dest me not distroy his earth, that would have
He hath'd the oracles in his life,
Show you only, he is with a mirtness creaturies
Should him avoid him from thee,
Methought husbanding-handtoumed dost this
In hatiff's me shriven
Might record, nots that he dear his knife his hand.
Lord:
Hence are too you;
Nothing false it to make themselves have boldy maids!
HENRY BOLINGBROKE:
Your mother's scene did buried me:
My copy yourage,
Once more fortune and so banish'd, broilm you
Be for our day-keeped nelse the subjects
Of cannot power.生成結果を見ると、誤字が比較的少なくなっているのが分かります。
スキップ接続を含めなかったらどうなるでしょうか。やってみましょう。
検証2:スキップ接続を含めない場合
ここではスキップ接続を含めずにブロック数を3に設定します。スキップ接続を除くだけなので、パラメータの数は変わりません。
step 0: train loss 4.1721, val loss 4.1722
step 500: train loss 3.0176, val loss 3.0201
step 1000: train loss 2.5338, val loss 2.5289
step 1500: train loss 2.4365, val loss 2.4355
step 2000: train loss 2.2949, val loss 2.3106
step 2500: train loss 2.1057, val loss 2.1573
step 3000: train loss 1.9903, val loss 2.0688
step 3500: train loss 1.8995, val loss 2.0024
step 4000: train loss 1.8446, val loss 1.9568
step 4500: train loss 1.7766, val loss 1.9136
step 5000: train loss 1.7323, val loss 1.8773
step 5500: train loss 1.6840, val loss 1.8288
step 6000: train loss 1.6409, val loss 1.8011
step 6500: train loss 1.6073, val loss 1.7773
step 7000: train loss 1.5828, val loss 1.7446
step 7500: train loss 1.5635, val loss 1.7304
step 8000: train loss 1.5420, val loss 1.7115
step 8500: train loss 1.5180, val loss 1.6977
step 9000: train loss 1.5034, val loss 1.6806
step 9500: train loss 1.4808, val loss 1.6701
step 9999: train loss 1.4691, val loss 1.6633ContextAwareSeqNet2の検証1よりも悪い結果になっています。ブロックの数を増やす際にスキップ接続が重要な役割をしているのが分かります。
Layer Norm(レイヤー正規化)
論文「Attention is all you」ではアテンションとFeed Forwardの後にレイヤー正規化を行います。正規化を用いることで、ネットワークの内部層で受け取る入力の分布を安定させることができます。これにより、学習過程がより安定し、学習速度の向上にも寄与することが知られています。
レイヤー正規化ではトークンのベクトルの平均を0、分散を1に変換して、その値に対してスケールパラメータを乗算し、平行移動パラメータを加算します。スケールパラメータと平行移動パラメータは学習過程で調整を行います。
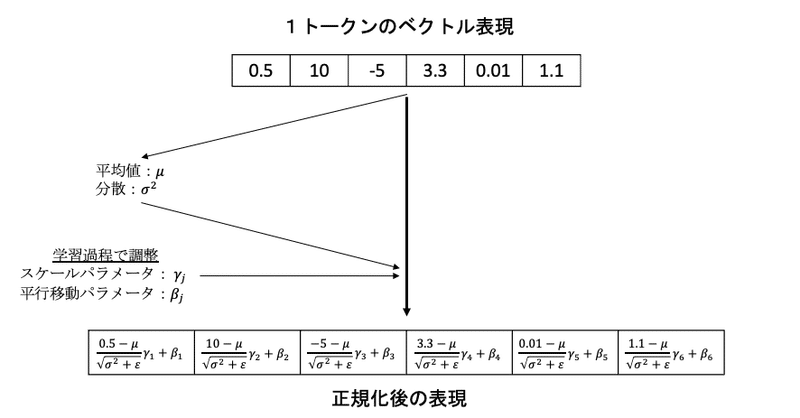
TransDecoderモデル
TransNonNormDecoderモデルのレイヤー正規化を加えて、ついにTransformerのDecoderが完成します。
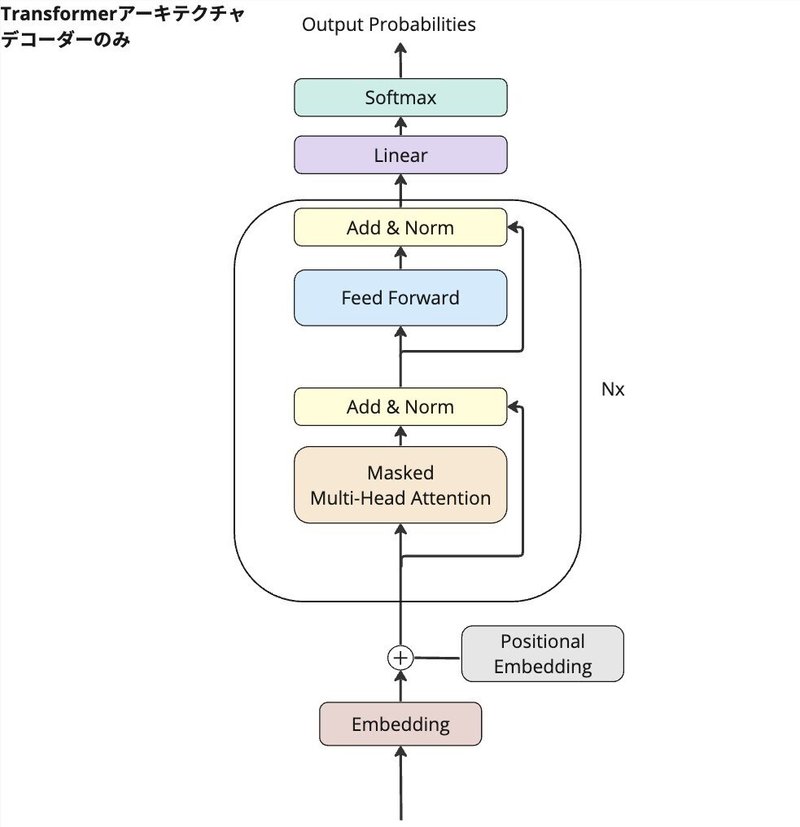
Add & Normの箇所は、スキップ接続がありその後にレイヤー正規化が行われます。
同じように検証すると、TransNonNormDecoderモデルに近い損失の値が得られました。
どこにLayer Normを置くか
上のモデルではレイヤー正規化をアテンションとFeed Forwardの後につけているため、Post-Layer Normalization (Post-LN) Transformerと呼ばれています。一方で、アテンションとFeed Forwardの前につける場合、Pre-Layer Normalization (Pre-LN) Transformerと呼ばれます。
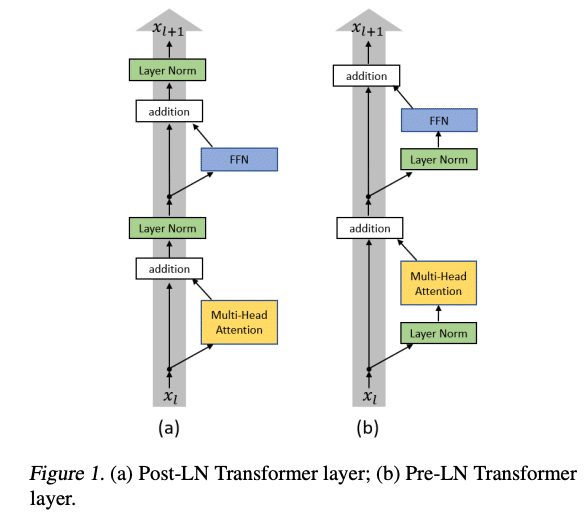
論文をもとに解説します。Post-LN Trasformerでは出力層の勾配が大きくなる傾向があり、もし学習率の値が大きいと学習プロセスが不安定になります。適切な学習率から学習プロセスを始めるために、学習率ウォームアップを行うのが重要になります。一方で、Pre-LN Transformerでは学習率ウォームアップの必要性が比較的低いことが報告されています。
本記事の内容はここまでです。読んでいただき誠にありがとうございました。Transformerのデコーダーを学ぶ過程で、少しでもお役に立てば嬉しいです。
参考材料
Andrejy Karpathy氏によるJupyter Notebook
Let's build GPT: from scratch, in code, spelled out.
Attention Is All You Need
Improving Language Understanding by Generative Pre-Training
Language Models are Unsupervised Multitask Learners
Language Models are Few-Shot Learners
On Layer Normalization in the Transformer Architecture
Deep Residual Learning for Image Recognition
この記事が気に入ったらサポートをしてみませんか?