[オタク機器日記] RTX8000で4bit量子化版Command R+ 104B版を試す

Cohere社はコンサルティング企業のマッキンゼーといち早くアライアンスを締結したり、企画屋の僕としても気になる存在だった。
そのCohere社がCommand R+という多国語対応LLM (生成AI) を提供する話は聞いていたが、さすがにパラメータ104B版を個人で動かすのは難しい… と思っていたら、4bit量子化(GGUF)版を作成して下さる神がいた。
これならば我がNVIDIA Quadra RTX 8000 (48GB/VRAM) でも十分に動かすことが出来そうだと、さっそく挑戦することにした。結論からいうと、一万文字の小説をプロ編集者として批評して頂くことに成功した。
(なかなか的確な指摘で、心が相当にエグられたけれども)
ただし久しぶりにNVIDIA製GPUを搭載したマシンを操作したので、いろいろと苦労する羽目になってしまった。今回はそんな一部始終を顛末記として報告することにしたい。
立ち上がれクアドラ
やはりNVIDIAのデータセンタ向けGPUを取り扱うのは大変だ。数週間くらい使わなかったら、見事に動かない状態になっていた。どうやらNVIDIAドライバが正常に動作していないらしい。起動時に赤い警告文字が表示されるので写真に撮って、そこで表示されたコマンドを実行したけれども、「ああ、そういうことね」で終わってしまう。そこからどうしたら、再びGPUを駆使できるようになるのかサッパリ分からない。
素人に毛が生えた程度だと、こんなものだろう。しかし「あきらめたら、そこでゲームセットですよ (by 安西先生)」である。ともかくubuntu 22.04さんのご指示に従ってコマンド実行したら、無事に稼働することになった。
$ sudo apt --fix-broken installなんだか最初から不穏な雲行きだったが、やはりこれが素人エンジニアの限界といったところだろうか。実は事態は、悪化の一途を辿ったのであった。
張り子のGPU
さてnvidia-smiコマンドやnvcc --versionが正常表示するようになったらコチラのもの…と、さっそく4bit量子化版Command R+ 104B版(GGUF版)を実行するのに必要なllama.cppをダウンロードしてmakeしたら… 順調には動いてくれなかった。
$ make4bit量子化版でも二つのファイルをmodelsディレクトリにダウンロードして実行する必要がある。合計60GBを超えており、それだけでも忍耐力が削られる。
command-r-plus-Q4_K_M-00001-of-00002.gguf
command-r-plus-Q4_K_M-00002-of-00002.gguf
ちなみにコマンドでは日本語のプロンプトを使えないという話を聞いたけれども、特に問題なく使えた。サンプルの "who am i?" の代わりに「ドラゴンボールの孫悟空を紹介してください」と入れたら、あっさりと説明してくれた。なおVRAMへのオフロードは48GBしかなかったので-ngl 48で試したけれども上手くいかず、-ngl 30では問題なく動作した。(と、その時は思っていた)
しかし肝心の1万文字小説を評価して貰おうとしたけれども、ターミナルが落ちてしまう。いやそもそも最初は何も考えずにネットに転がっているスクリプトを実行させようとしたら、「1万文字なんてデフォルト設定では無理だよ」とCommand R+さんに突っ返されてしまった。
で、「泣いているだけでは何も解決しないぞ、セーラームーン」というタキシード仮面山本さまのご指導を思い出し、よくよくターミナルを見てみると、Command R+のコマンドで使える変数などが説明されている。"-c トークン数" と指定すればデフォルト値を変えることが可能とのことで、-c 6800とやったらば取り合えずプロンプトは読み込んでくれるようになった。(なんでもCommand R+にとって日本語1万文字は6500トークンというのがエラー表示で説明されていたので、少し大きめに6800に設定してみたという訳だ)
ちなみにそこで "-p プロンプト" の代わりに "-f ファイル名" とすれば良いとのことだったので、もちろん1万文字はファイルに保存した。
が、先ほど書いたように、プロンプトの1万文字小説をターミナルで表示したらば落ちてしまう。これを解決するには30分ほど必要となってしまった。解決できたのは、nvidia-smiコマンドを見ていたおかげだ。どう見てもGPUが使用されていない。
これは初心に戻ってLlama.cppサイトを閲覧して原因判明した。「そういやデフォルトで指定されているmakeだけを叩いたのでは、CPUでしか動作しないようにmainプログラムがコンパイルされる仕様だった」のである。
$ make LLAMA_OPENBLAS=1 これで無事にLlama.cppがGPUを使用するようになり、あとはエラーメッセージを見ながらパラメータを調整した。
ちなみにVRAMが48GBあればECCオンでも46GBは使えるけれども、-ngl 47はダメだった。なぜならばVRAMに収納されるのはモデルだけでなく、プロンプトも収納される。さすがに1万文字だと相当のメモリを必要とするので、nvidia-smiコマンドでVRAM使用量を見ながら-ngl 45という結果に落ち着いた。
かくして張り子のトラならぬ宇宙で利用されるモビルスーツの足のように『ただのお飾り』と化していたNVIDIA Quadra RTX 8000は、無事にLlama.cppで利用されるようになったのであった。

まとめ (実行コマンド)
そんな訳で今回の1万文字小説を評価して頂くのに使ったのは下記コマンドである。小説はこちらのStargateというヤツ。
$ ./main -f ./prompt.txt --color -m ./models/command-r-plus-Q4_K_M-00001-of-00002.gguf -ngl 45 -c 6800なお本日2024年4月17日現在では小説を貼り合わせたMicrosoft Word換算36,204語の "幾つかの小説の集合体" の批評に成功している。もちろんプロンプトのサイズが大きくなっているので、必然的にVRAMオフロードも減っている。僕の場合は -ngl 38 という結果に落ち着いている。-c は30000だ。
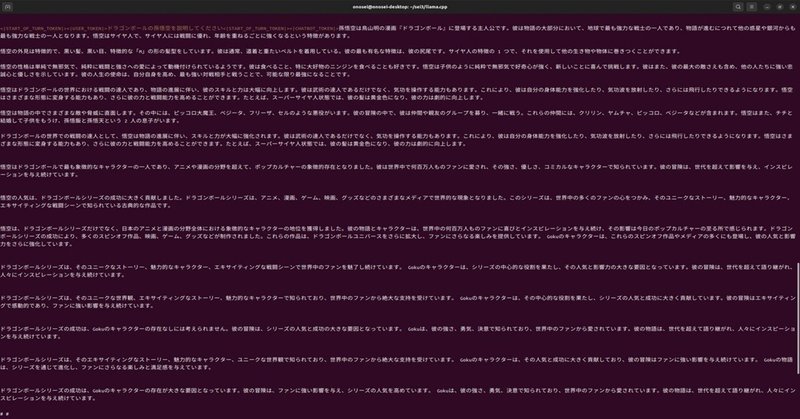
$ ./main -f ./prompt2.txt --color -m ./models/command-r-plus-Q4_K_M-00001-of-00002.gguf -ngl 38 -c 30000ただし申し訳ないけれども、上記は実行したコマンドそのものをコピペしたものではない。もしかしたら記憶違いしている点があるかもしれない。その場合は勘弁して頂けると嬉しい。ともかくこのテスト結果が、少しでも誰かのお役に立つことがあれば幸いである。なおプロンプトファイルは下記の通り。
あと実のところ、プロンプトファイルの作成には苦戦している。Ubuntu 22.04のFirefoxで表示したデータをテキストファイルとして保存したらば動くのだけれども、もともと原稿として作成したテキストファイルではInvalid charaterとやらでコアダンプを吐かれて終了してしまった。どうもファイル中の特殊文字とか、Shift-JISコードでテキストファイル作成している点が問題あたりが影響しているらしい。時間ができたら試してみたい。
それでは今回は、この辺で。ではまた。
ーーーーー
記事作成:小野谷静(オノセー)
この記事が気に入ったらサポートをしてみませんか?