LLMファインチューニングのためのNLPと深層学習入門 #8 層(layers)

今回は、CVMLエキスパートガイドの『層 (layers) : ディープラーニングの層の種類まとめ』を勉強していきます。
1. 概要
層(layers)とは、ディープラーニングにおいて、DNNを構成・設計する際の最小構成単位を指します。
各種の「層」をノードとした計算グラフを構成することで、DNN構造の設計を行います。
つまり、層をつなげて任意のグラフ構造にすると、ディープニューラルネットワークができあがります。
なお、グラフ構造とは、「ノード」とその関係を示す「エッジ」からなるデータ構造のことを言います。
有向グラフや、無向グラフなどは、グラフ構造の一種です。
DNNでは、全ての層は微分可能な層として設計する必要があります。
また、層によっては学習するパラメータを保持していない層もあります。
DNNを設計する際には、今回紹介するような層を様々につなぎ合わせることで、良いDNNの設計を探っていくのが基本的な方針です。
なお、NAS(Neural Architecture Search)などの設計最適化アルゴリズムに最良設計を自動で選んでもらう潮流もあるとのことです。
2. 層の種類の一覧
現在の主要な層の種類は次のようになっています。
全結合層
畳み込み層
活性化関数
[中間層] ReLU型の活性化関数
[出力層] softmax
プーリング層
バッチ正規化
ドロップアウト(正則化目的)
埋め込み層(NLPでよく使う、系列モデル向けのトークン表現作成層)
※Kevin Patrick Murphy氏の新著 Probabilistic Machine Learning: An Introduction では、バッチ正規化もCNNの一般的な層のひとつとして分類・紹介していますが、最近のテキストや論文でも、バッチ正規化を層として明示的に分類していない場合もあります。
PyTorchのtorch.nnのクラス一覧には、PyTorchで使用可能な層が記載されています。
各クラスの説明と一緒に読み進めると、理解しやすいです。
3. 層(layer)の定義
本ページでは、冒頭の定義の通り、DNNの最小構成部品は全て「層」と呼ぶことにします。
以下の図1は、4層で構成されたDNNのサンプル図です。

CVMLエキスパートガイドより
このDNNでは、中間層(隠れ層)の2つが全結合層であり、出力はsoftmax関数となっています。
多くの教科書や論文では「ニューロンユニット間でインタラクションがある部品」のみを「層」と呼ぶ形式です。
その場合、今回の例でいうsoftmax関数のような「活性化関数」は、層とはみなされず別枠で紹介されます。
しかし、今回は「層とブロックを組み合わせるDNN」という視点から学んでいくので、「層」と「活性化関数」を分けて呼ぶのは面倒です。
したがって、今後「活性化関数も層カテゴリの一種である」とみなし、まとめて「層」と呼ぶことにします。
全ての層は「微分可能」
次の節で紹介する各「層の種類」は、基本的に全て微分可能です。
これは、深層学習において基本的かつ重要なポイントです。
深層学習で用いるDNNは、非常に大量の重みパラメータや、アテンション係数・バッチ正規化パラメータをEnd-to-End学習します。
『End-to-End学習』
入力から出力までの全ての処理を一つのモデルで行うアプローチです。
特徴抽出から最終的な予測まで、モデル内の全てのパラメータが共同で学習されるため、特徴抽出の段階での人間のバイアスが排除され、データから直接的な学習が可能になります。
DNNは、SGD(確率的勾配降下法)でバッチ最適化するので、DNN内の全ての層は微分可能である必要があるのです。
『確率的勾配降下法(SGD)』
機械学習や深層学習の最適化アルゴリズムの一つです。
全ての訓練データを使って勾配を計算するのではなく、ランダムに選ばれた一部のデータ(ミニバッチ)を使って勾配を計算し、その勾配の方向にパラメータを少しずつ更新していきます。
これにより、計算効率を高めながらパラメータの最適化を行います。
なお、ランダムに選ばれたデータを使って勾配を計算し、その勾配の方向にパラメータを更新していく「ミニバッチ」という考え方は、Huggingfaceの提供するライブラリを使用してトレーニングする際に指定する「バッチ数」と同じです。
微分できない関数は、微分可能な層に変形
したがって、「もとは微分不可能な関数」を層に取り入れたい場合は、なんらかの近似関数化を行い、微分可能な関数として設計する必要があります。
また、ランダム変数を関数内に含むようなベイズ確立モデリング目的の層だと、ランダム変数生成部分が微分できないので、決定的な関数(同じ入力に対して常に同じ出力を返す関数)によってランダム生成部分を代替します。
具体的な例では、変分オートエンコーダ(VAE)では「再パラメータ化トリック」が、Gumbel Softmaxでは「Gumbel Softmaxトリック」がこれに当たります。これらの手法により、確率的な生成プロセスを持つモデルでも微分可能な形で学習を行うことが可能になります。
まとめると、微分不可能な関数や、ランダム変数を関数内に含む場合、「(潜在変数の)ランダム生成を、決定的な関数に代替させる」トリックを用いて、微分可能な層に替えてから使用します。
『ベイズ確立モデリング』
ベイズ確率モデリングは、確率的な不確実性を直接的にモデル化するための手法であり、ベイズの定理に基づいています。
ベイズ確率モデリングを目的とした層は、この確率的な不確実性を取り扱うための層で、出力が確率分布に従うという特性を持ちます。
4. 主要な層の種類
4.1 全結合層

CVMLエキスパートガイドより
全結合層(Fully Connected Layer、Dence Layer、または密層)は、伝統的なニューラルネットワークの中間層を構成する基幹部品です。
1つの層にあるすべてのノードが次の層のすべてのノードに結合しています。お互いに接続している特徴を持ちます。
つまり、各入力ノードがそれぞれの出力ノードに「すべてつながっている」ことから、全結合層と呼ばれます。
全結合層は、3層MLP(Multi-Layer Perceptron: 多層パーセプトロン)時代は最も基本的な構成部品でした。
しかし、CNNとDNNの登場で、同じ線形層でも効率的で空間的な操作の畳み込み層に立場を譲り、出力層の付近でしか使われなくなっていました。
ところが、2018年ごろのTransformerやBERT、GPTの登場で、これらのモデルも重要な部品として採用されました。
以降、Transformerの部品で用いる埋め込み層やマルチヘッドアテンション内に含まれる全結合層を、DNNで多用することになります。
これにより、畳み込み層に一度主役を奪われた全結合層の立場が、「アテンション+全結合層」を主部品とするTransformerを通じて復権してきたとも言えます。
4.2 畳み込み層

CVMLエキスパートガイドより
畳み込み層は、入力されたデータから、K個のカーネルで特徴抽出を行った結果を出力する層です。
カーネルは学習可能なパターンであり、訓練の過程で最適化されます。
すなわち、カーネルに学習されている各パターンが、入力特徴マップ中のどこに強く存在しているかのマップを、各チャンネルに出力する層です。
畳み込み層により、フィルターが学習した特定の単語のパターンが、入力文中のどこに存在するかを示す特徴マップが生成されます。これにより、フィルターが検出したパターンに基づいて、文中の重要な意味的な機能を抽出することが可能になります。
しかし、畳み込みの結果にはノイズが含まれる可能性があるため、そのまま次の層につなげていっても良い情報とはなり得ません。
そこで、それぞれの畳み込みの後でReLUのような非線形の活性化関数を適用することが一般的です。
これにより、ノイズが消えて特徴の強い場所だけ残った特徴マップ群を得ることができます。
4.3 活性化関数

CVMLエキスパートガイドより
活性化関数層は、他の層で抽出した特徴のうち、強い値だけを残す閾値関数の役割を担当します。
DNNにおいて、活性化関数は以下の2つの用途に使われます。
中間層の値の活性化(ReLU系・tanh)
出力層(softmax / シグモイド)
本当は「ステップ関数」を使えば閾値処理としての目的は簡単に達成できます。
しかし、ステップ関数は微分不可能なので、勾配降下法ベースで最適化することが主流の(ディープ)ニューラルネットワークでは使用できません。
『ステップ関数』
入力が特定の閾値より小さいか大きいかに応じて値を切り替える関数。
$${f(x) = 0 \quad (x < 0) \\ f(x) = 1 \quad (x \geq 0)}$$
よって、「中間層」では、微分可能な関数としてシグモイド関数やtanh関数などが用いられていましたが、ディープラーニングが登場すると、CNN界隈を皮切りにReLU系関数が中間層の活性化関数の主流となりました。
出力層では、クラス確率値ベクトルを出力できるsoftmaxまたはシグモイド関数が使われます。
4.3.1 ReLU型の活性化関数

CVMLエキスパートガイドより
ディープラーニング・CNNの登場後、中間層として最もよく用いられるようになったのが、ReLU系の活性化関数です。
10層~20層のCNNを学習して最適化していた2010年以降では、旧来のシグモイド関数などでは、微分計算が遅く不便でした。
そこで、効率的な微分値計算で逆伝搬ができる、シンプルなランプ関数型のReLUが中間層の活性化関数として提案されました。
ランプ関数とは、一般に$${f(x) = max(0, x)}$$として定義される関数で、その形状がランプ(傾斜)に似ていることからその名前がつけられました。
ReLUは著名研究者のKaiming He氏による提案であったこともあり、標準的に使用されるようになりました。
ただ、ReLUには、負の値に対する出力が常に0であるという欠点が存在しました。
これは、負の値に対する勾配が常に0であるということを意味し、ニューラルネットワークの学習中に、あるニューロンが常に負の値を出力する可能性があるとき、そのニューロンは学習中に全く更新されなくなってしまいます。
つまり、「死んだ」ニューロンはネットワークにとって無意味になってしまうということです。
そこで、非線形関数に改善されたPReLUやGELU(Gaussian Error Linear Unit)やSwishなどが登場し、オリジナルのReLUの代わりに使用されることとなります。
4.3.2 softmax関数・シグモイド関数による出力層

CVMLエキスパートガイドより
基本的なCNNである物体認識向けクラス識別CNNでは、最終出力層部分をSoftmax層+交差エントロピー層の組み合わせで構成することが多いです。
Softmaxは名前の通り「Soft化したargmax関数」で、合計が1に正規化された、Nクラスの各確率値を出力できます。
ロジスティック回帰や3層MLPなど、ディープラーニング登場以前からクラス識別モデルで使用されてきました。
softmax識別器は多クラス識別向けで、2クラス識別器の場合は代わりにシグモイド関数を用います。
なお、Hugging Faceの提供するTrainerクラスでは、デフォルトでクロスエントロピー損失を使用しています。
この損失は、モデルが予測した確率分布と実際のラベル(正解の確率分布)との間の不一致を計測します。
モデルの予測が正解ラベルに近づくほど、この損失は小さくなります。
一般的に、出力層でsoftmax関数を用いて確率分布を生成し、その後クロスエントロピー損失を計算する流れが取られます。
ただし、Hugging FaceのTrainerクラスでは、自分で定義した損失関数を使用することも可能です。
そのため、特定のタスクに対して特化した損失関数を使用することもできます。
4.4 プーリング層
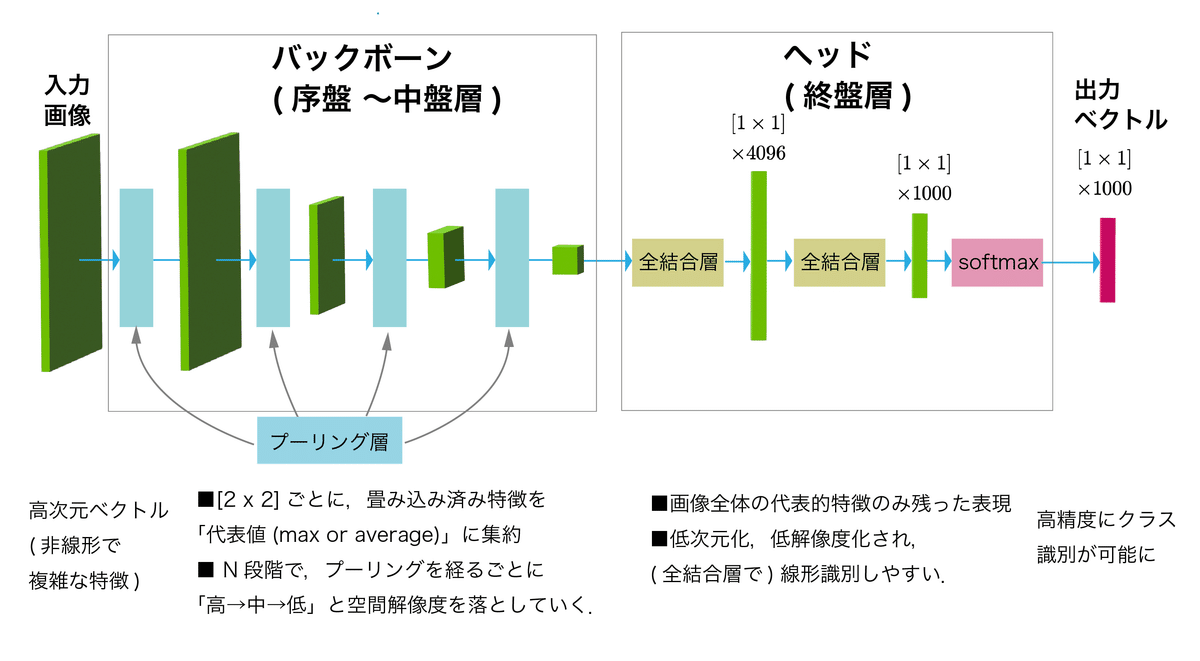
CVMLエキスパートガイドより
画像認識向けCNNによく使用される、最大値プーリングや平均プーリングのような局所プーリング層は、特徴集約を担当する層です。
プーリング層では、順伝搬で抽出した特徴マップを、空間ダウンサンプリングとともに局所領域ごとに集約を行います。
これにより、各局所領域の代表値が生き残った特徴マップへと変換され、以降の層では変換した特徴マップをもとに広範囲の情報を「畳み込み層+ReLU」で効率的に特徴抽出できるようになります。
(局所)プーリング層を用いないと、広範な特徴を抽出するには大量の畳み込み層が必要になり、計算効率が悪くなります。
それが、プーリング層を使用することで効率的な特徴の集約を行うことができるようになるということです。
ただし、プーリング層によるダウンサンプリングが文の序列情報を失わせる可能性があるため、CNN(畳み込みニューラルネットワーク)とは違い、NLPでよく使われるトランスフォーマーモデルなどではプーリング層は一般的に使用されません。
代わりに、自己注意メカニズムによって、各単語が文中の全ての単語との関連性を考慮することが可能になります。
4.5 バッチ正規化

CVMLエキスパートガイドより
この層は、各中間層で特徴マップを毎回正規化することにより、DNNの学習を安定させ、なおかつ高速化する役割の層です。
バッチ正規化は、各中間層の「層と層の間」に挿入される層です。
なお、「バッチ正規化」という名前ですが、1つのバッチ正規化層内で何度も正規化を繰り返すことではないということに注意してください。
それぞれのバッチ正規化層は、その前の層からの入力データ(バッチ)に対して一度だけ正規化を行います。
これを各中間層で繰り返し用いることで、値が一定の範囲内に常に収まるため、モデル全体の学習が安定し、高速化します。
特徴正規化や特徴スケーリングは、機械学習では昔から使用されているテクニックですが、DNNとSGD向けの特徴正規化テクニックがバッチ正規化です。
元々はCNN向けに、つまり画像データ向けに登場した層でしたが、時系列データ、つまり自然言語処理向けにレイヤー正規化が登場し、Transformerでも使用されました。
また、CNNなどのモデルの規模が大きくなるにつれ、更にバッチ学習向けに効率的なテクニックが必要となり、グループ正規化が登場しました。
その後、グループ正規化の発展形や派生形がCV(コンピュータビジョン)ではよく研究されています。
4.6 ドロップアウト層

CVMLエキスパートガイドより
ドロップアウト層は、学習時の毎エポック時に、ニューロンユニットの出力を一定割合だけランダムにドロップすることで、正則化効果を得る目的の層です。
ここで、正則化とは、機械学習モデルの学習過程で、モデルが過学習(オーバーフィッティング)するのを防ぐための手法です。
正則化は、モデルの複雑さにペナルティを課すことで実現されます。
具体的には、損失関数に対してペナルティ項(通常はモデルのパラメータの大きさに関連する項)を追加します。
これにより、モデルが訓練データに過剰に適合することを抑制し、未知のデータに対する汎化性能を向上させます。
ドロップアウト層では、割合p(=0.5が標準値)だけ、ランダムにニューロンを無効にして、部分ネットワーク群の重みを訓練データにフィットするように更新します。
これを繰り返すと、毎回の部分ネットワークの順伝搬の平均近似をデータセットにフィットさせることになるので、もとの間引きなしのネットワークで過学習してしまうのを防ぐことができます。
簡単な「ランダム間引き処理」を加えるだけで複雑な深いニューラルネットワークを正則化できるため、非常に多くのネットワークで標準的に使われるようになりました。
ドロップアウトは、Transformerが登場する前までは、バッチ正規化が登場して以降、あまり使用されていませんでした。
ところが、昨今のTransformerでは、基板モデルがもつネットワークはとても巨大なので、強い正則化が必要であり、ドロップアウトの出番が復活したとも言えます。
4.7 埋め込み層(NLPやTransformerむけ)
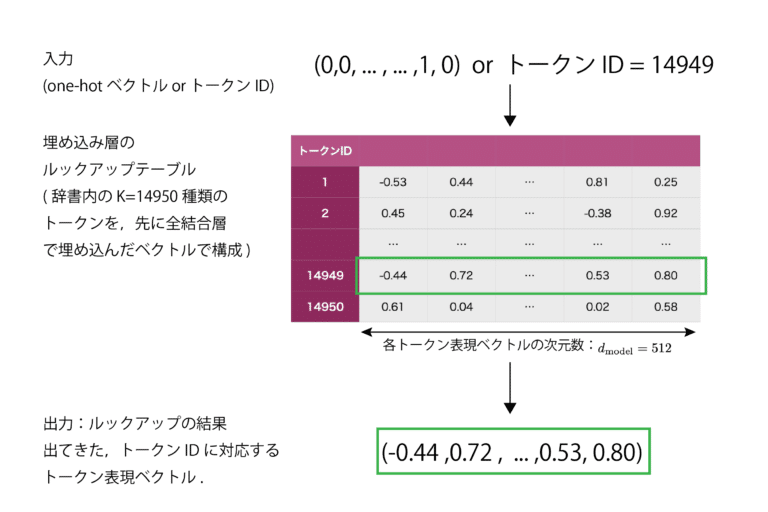
CVMLエキスパートガイドより
単語・トークンの埋め込み層(Embedding Layer)では、「one-hotベクトル入力→全結合層」のペアで構成される層です。
実際は、単語・トークンの高次元one-hot表現を、低次元表現へ埋め込んだものが保管されているルックアップテーブルであり、単語・トークンIDを入力すると、対応するIDの埋め込みベクトルを出力することができるようになっています。
単語・トークンの埋め込みベクトルをつくり、RNNLMやseq2seq、Transformer・BERTなどへ入力する際によく用いる、NLP向けの層です。
5. おわりに
今回はディープラーニングにおいて用いられる「層」の種類とその機能について勉強しました。
埋め込み層やバッチ正規化、畳み込み層など、以前調べていてよく分からなかった項目について、概要を簡単に理解できたのは嬉しいですね、随分と見晴らしが良くなりました。
スキップ接続→残差接続→レイヤー正規化→Transformerの流れで勉強を進めていきたいので、次回はスキップ接続について学ぶ予定です。
それでは。
進捗上げてます
「#AIアイネス」で日々の作業内容を更新しています。
ぜひ覗いてみて下さい。
参考
層 (layers) : ディープラーニングの層の種類まとめ, CVMLエキスパートガイド, 林 昌希, 2022
この記事が気に入ったらサポートをしてみませんか?